Hello,
I have implemented a one layer LSTM network followed by a linear layer. I followed a few blog posts and PyTorch portal to implement variable length input sequencing with pack_padded and pad_packed sequence which appears to work well. However, the training loss does not decrease over time.
The network architecture I have is as follow,
input —> LSTM —> linear+sigmoid —> BCEWithLogitsLoss(flatten_logits, targets)
E.g., for input =
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
and target =
[[1, 0],
[0, 0],
[0, 1],
[1, 1]]
(flattened target = [1, 0, 0, 0, 0, 1, 1, 1])
I believe the BCE with logits loss function works on flatten logits and targets
flattened_logits = [0.7, 0.2, 0.1, 0.1, 0.3, 0.6, 0.3, 0.8]
targets = [1, 0, 0, 0, 0, 1, 1, 1]
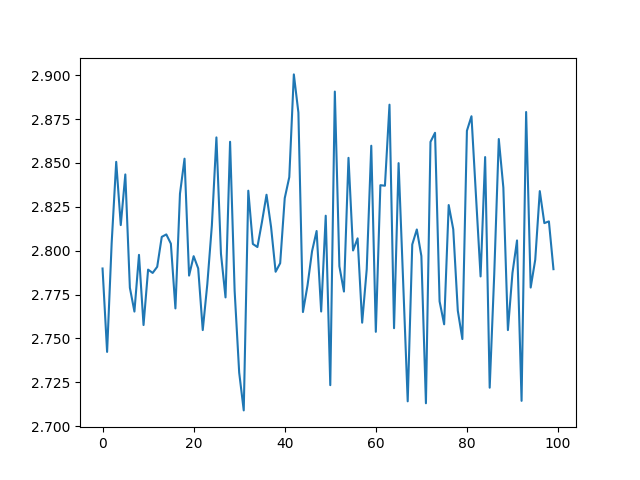
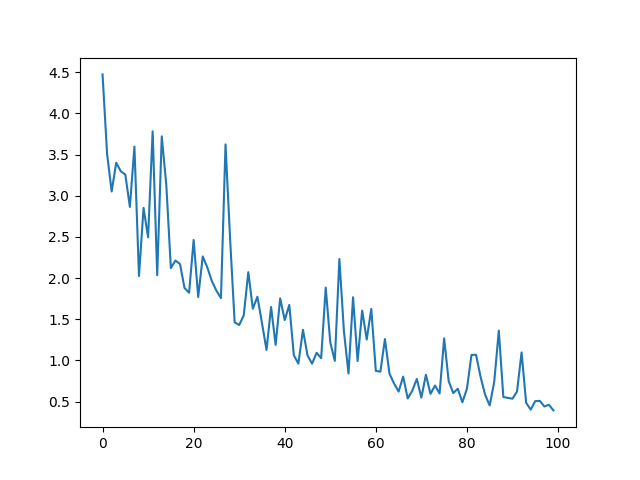
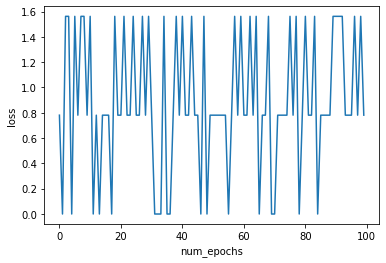
I expect this loss to decrease over time which does not happen.
The code for this is as follow,
LSTM Network Code
class BuildModel(nn.Module):
on_gpu = False
def __init__(self, output_dim, batch_size = 2, lstm_units = 200):
super(BuildModel, self).__init__()
self.lstm_units = lstm_units
self.batch_size = batch_size
self.output_dim = output_dim
self.input_dim = output_dim * 2
self.seq_len = seq_len
self.__build_model()
def __build_model(self):
self.lstm = nn.LSTM(
input_size = self.input_dim,
hidden_size = self.lstm_units,
num_layers = 1,
batch_first = True,
)
self.hidden_to_outputs = nn.Linear(self.lstm_units, self.output_dim)
def init_hidden(self):
hidden_a = torch.randn(1, self.batch_size, self.lstm_units)
hidden_b = torch.randn(1, self.batch_size, self.lstm_units)
if self.on_gpu:
hidden_a = hidden_a.cuda()
hidden_b = hidden_b.cuda()
hidden_a = Variable(hidden_a, requires_grad=True)
hidden_b = Variable(hidden_b, requires_grad=True)
return (hidden_a, hidden_b)
def forward(self, X, X_lengths):
self.hidden = self.init_hidden()
batch_size, seq_len, _ = X.size()
X = torch.nn.utils.rnn.pack_padded_sequence(X, X_lengths, batch_first=True, enforce_sorted=False)
X, self.hidden = self.lstm(X, self.hidden)
X, _ = torch.nn.utils.rnn.pad_packed_sequence(X, batch_first=True)
# Transfer data from (batch_size, seq_len, lstm_units) --> (batch_size * seq_len, lstm_units)
X = X.contiguous()
X = X.view(-1, X.shape[2])
X = self.hidden_to_outputs(X)
X = torch.nn.functional.sigmoid(X)
# return the predictions
return X
def loss(self, Y_hat, Y, threshold, seq_len):
#flatten labels
Y = Y.view(-1)
Y_hat = Y_hat.view(-1, seq_len * self.output_dim * self.batch_size)
## Identifying mask to zero out all the elements with -1 from logits and targets
mask = (Y > -1).float()
mask_long = (Y > -1).long()
nb_tokens = int(torch.sum(mask).item())
## Zeroing all the elements that have -1 values in targets so that they don't
## contribute in loss.
Y_hat = Y_hat[range(Y_hat.shape[0])] * mask
Y_hat = Y_hat.reshape(-1)
Y = Y[range(Y.shape[0])] * mask_long
Y = Y.float()
loss = torch.nn.BCEWithLogitsLoss()
ce_loss = loss(Y_hat, Y)
return Variable(ce_loss, requires_grad = True)
Training Code.
learning_rate = .1
output_dim = 2
total_step = len(loader)
model = BuildModel(output_dim, 2, 200)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
overall_loss = 0.0
for i, (X, y, lengths, seq_len) in enumerate(loader):
X = torch.from_numpy(X).float()
y = torch.from_numpy(y).long()
optimizer.zero_grad()
outputs = model(X, lengths)
loss = model.loss(outputs, y, 0.5, seq_len)
overall_loss += loss.tolist()
loss.backward()
optimizer.step()
print(overall_loss) ### <--- I believe this loss should decrease over the number of epochs which does not happen.
The loss for this network does not decrease over time. Pardon me if this is not a suitable question for this forum but I asked the question on SO: https://stackoverflow.com/questions/58245251/loss-does-not-decrease-for-pytorch-lstm and did not get a response, so I am trying this forum.
I am new to PyTorch (and LSTM as well). Would you be so kind and help? Specifcially,
- Does the architecture (in code and from what I intend to do) look correct?
- Is there any issue with the way I train the network?
- Is there any issue with the loss function?
- Did I miss any basic (conceptual) thing in implementation?
- Is there any other issue?
Your help is much appreciated.
Thank You