I’m trying to build a LSTM-VAE model to infer the latent space of a time series. I’m building it in PyTorch. I’m currently trying to train this model on a vanilla data which is y = sin(x):
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset, Dataset
from torch.optim import SGD, Adam
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from IPython.display import clear_output
d = np.sin(np.linspace(1, 1000, 2000))
data = pd.DataFrame({"x" : d})
timestep = 200
X = []
for i in range(timestep, data.shape[0]):
sample_piece = data.iloc[i - timestep : i, :].to_numpy().reshape((timestep, -1))
X.append(sample_piece.tolist())
X = np.array(X)
class MyData(Dataset):
def __init__(self, x):
super(MyData, self).__init__()
self._x = x
def __getitem__(self, index):
return self._x[index]
def __len__(self):
return len(self._x)
My model contains two parts, encoder and decoder.
In encoder, train data is put into LSTM and then extract the representation from the last hidden layer from the last time step. Then representations are sent into the fully connected layers to infer the means and log variances of latent spaces.
In decoder, the decoder LSTM uses the hidden cells of the encoder. It’s input is a duplicate of representations. For example, if my batch size is 2, the dimension after some transformation of the latent space is 3, then I will get a matrix like [[1, 2, 3], [2, 2, 3]]. I replicate each representation in the batch to align the number of time steps. For example, suppose I have 3 time steps, the input of encoder for first batch will be [[1,2,3]. [1,2,3], [1,2,3]]. Then, I will take the output of encoder LSTM in each time step as the reconstruction value.
Here’s my model:
class RNN_VAE(nn.Module):
def __init__(self, input_dimension = (20, 4),
rnn_hiddensize = 4,
rnn_numlayer = 2,
latent_space_dim = 1,
rnn_dropout = 0.2):
super(RNN_VAE, self).__init__()
self._input_dimension = input_dimension
self._rnn_hiddensize = rnn_hiddensize
self._rnn_numlayer = rnn_numlayer
self._latent_space_dim = latent_space_dim
self._rnn_encoder = nn.LSTM(input_dimension[1],
self._rnn_hiddensize,
self._rnn_numlayer,
dropout = rnn_dropout,
batch_first = True,
bidirectional = False)
self._fc_encoder = nn.Sequential(nn.Linear(self._rnn_hiddensize, int(self._rnn_hiddensize / 2)),
nn.ReLU(),
nn.Linear(int(self._rnn_hiddensize / 2), 2 * latent_space_dim))
self._fc_decoder = nn.Sequential(nn.Linear(latent_space_dim, int(self._rnn_hiddensize / 2)),
nn.ReLU(),
nn.Linear(int(self._rnn_hiddensize / 2), self._rnn_hiddensize))
self._rnn_decoder = nn.LSTM(self._rnn_hiddensize,
self._rnn_hiddensize,
self._rnn_numlayer,
dropout = rnn_dropout,
batch_first = True,
bidirectional = False)
self._decoder_shaper = nn.Sequential(nn.Linear(self._rnn_hiddensize, 16),
nn.ReLU(),
nn.Linear(16, self._input_dimension[1]))
def reparameterize(self, mean, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mean + std * eps
def encode(self, X):
_, hidden = self._rnn_encoder(X)
x = self._fc_encoder(hidden[0][-1, :, :])
mean = x[:, :self._latent_space_dim]
logvar = x[:, self._latent_space_dim:]
return mean, logvar, hidden
def decode(self, z, encoder_hidden):
x = self._fc_decoder(z)
x = x.unsqueeze(1).repeat(1, self._input_dimension[0], 1)
out, _ = self._rnn_decoder(x, encoder_hidden)
out = self._decoder_shaper(out)
return out
def forward(self, X):
mean, logvar, hidden = self.encode(X)
z = self.reparameterize(mean, logvar)
y_hat = self.decode(z, hidden)
return y_hat, mean, logvar
Here’s the training loop with visualization:
def get_loss(model, x, tracker, training = False):
y_hat, latent_mean, latent_logvar = model(x)
reconstruction_loss = nn.MSELoss()(x, y_hat)
KL_loss = torch.mean(-0.5 * torch.sum(1 + latent_logvar - latent_mean ** 2 - latent_logvar.exp(), dim = 1), dim = 0)
total_loss = reconstruction_loss + 25e-5 * KL_loss
if training:
tracker["t_hat"] = y_hat
return reconstruction_loss, KL_loss, total_loss
def train_step(model, dataloader, optimizer, tracker):
total_reconstruction_loss = 0
total_KL_loss = 0
model.train()
for idx, x, in enumerate(dataloader):
optimizer.zero_grad()
reconstruction_loss, KL_loss, total_loss = get_loss(model, x, tracker, True)
total_reconstruction_loss += reconstruction_loss.cpu().item()
total_KL_loss += KL_loss.cpu().item()
total_loss.backward()
optimizer.step()
tracker["t_loss"].append((total_reconstruction_loss / (idx + 1), total_KL_loss / (idx + 1)))
def valid_step(model, x_valid, tracker):
total_reconstruction_loss = 0
total_KL_loss = 0
model.eval()
with torch.no_grad():
reconstruction_loss, KL_loss, _ = get_loss(model, x_valid, tracker)
tracker["v_loss"].append((reconstruction_loss.cpu().mean(), KL_loss.cpu()))
def visualize_loss(model, tracker):
clear_output(wait = True)
t_loss = np.array(tracker["t_loss"])
v_loss = np.array(tracker["v_loss"])
fig, ax = plt.subplots(nrows = 2, ncols = 2, figsize = [6.4 * 1.5, 4.8 * 1.5])
ax[0, 0].plot(t_loss[:, 0], label = "train_reconstruction_loss")
ax[0, 0].plot(v_loss[:, 0], label = "validation_reconstruction_loss")
ax[0, 0].legend()
ax[0, 1].plot(t_loss[:, 1], label = "train_KL_loss")
#ax[0, 1].plot(v_loss[:, 1], label = "validation_KL_loss")
ax[0, 1].legend()
ax[1, 0].plot(tracker["t_true"][0, :, :].cpu().clone().detach().numpy(), label = "actual y")
ax[1, 1].plot(tracker["t_hat"][0, :, :].cpu().clone().detach().numpy(), label = "reconstructed y")
ax[1, 0].legend()
clear_output(wait = True)
plt.show()
print("validation MSE: " + str(v_loss[-1, 0]))
print("validation KL: " + str(v_loss[-1, 1]))
def train(model, x, optimizer, epochs, batch_size, device):
model = model.to(device)
x = torch.tensor(x, dtype = torch.float32, device = device)
x_train, x_valid = train_test_split(x, test_size = 0.3, shuffle = False)
train_data = MyData(x_train)
train_loader = DataLoader(train_data, batch_size, shuffle = True)
tracker = {"t_loss" : [],
"v_loss" : [],
"t_true" : x_train,
"t_hat" : None}
for e in range(epochs):
train_step(model, train_loader, optimizer, tracker)
valid_step(model, x_valid, tracker)
if e % 5 == 0:
visualize_loss(model, tracker)
model = RNN_VAE(input_dimension = (X.shape[1], X.shape[2]),
rnn_hiddensize = 64,
rnn_numlayer = 8,
latent_space_dim = 16)
optimizer = Adam(model.parameters(),
lr = 1e-5,
weight_decay = 0.995)
device = torch.device("cuda")
train(model, X, optimizer, epochs = 500, batch_size = 1, device = device)
The training progress looks like:
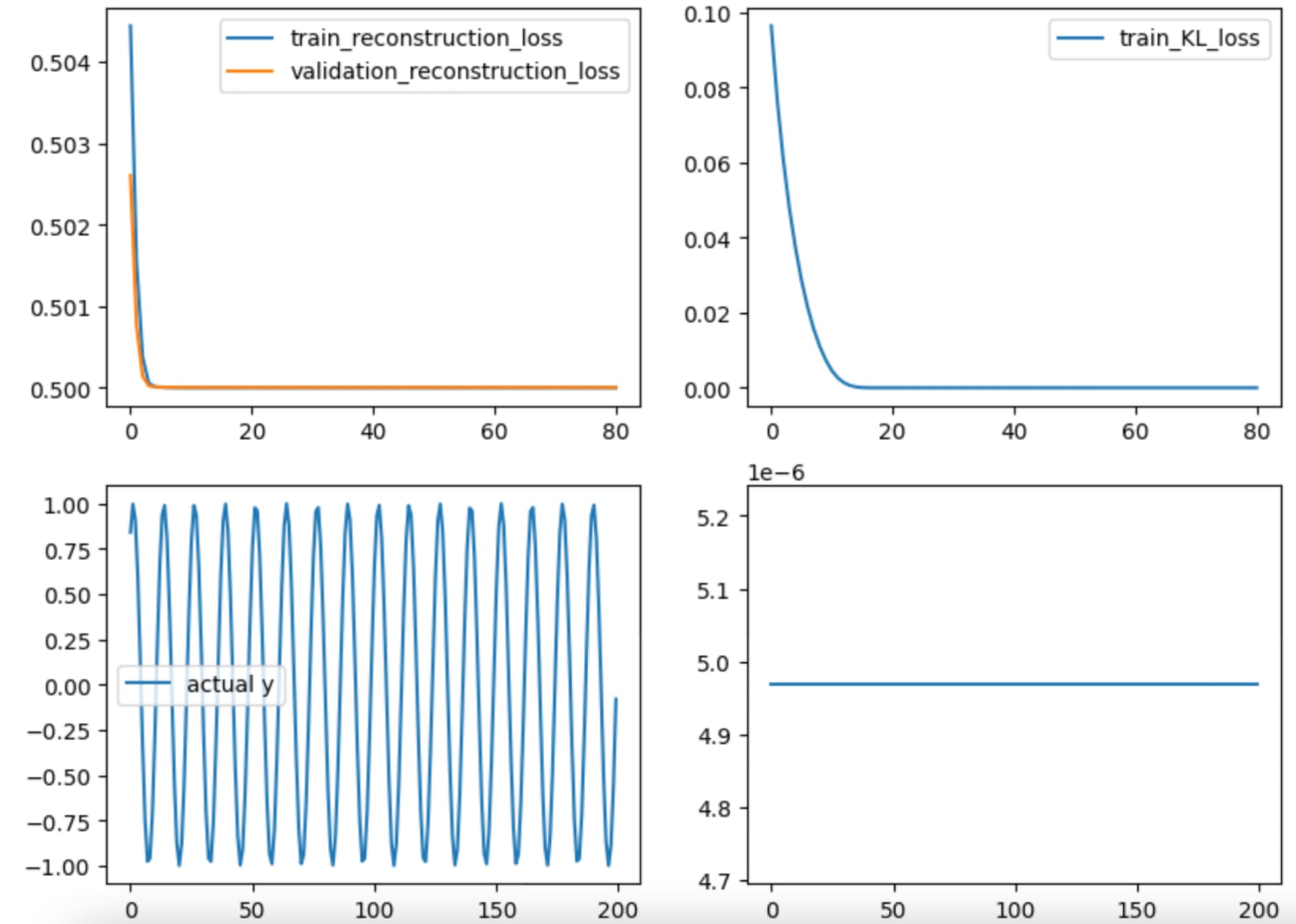
As you can see, there’s KL vanishing and the reconstruction value becomes a horizontal line. I’ve tried to make this model more complicated but there’s no change, reconstructed value still gets to straight lines.