Hello everyone,
I’m encountering issues while working on an LSTM implementation with online training. There are two primary problems:
- Overfitting during Online Training:
- I can train my model successfully with satisfactory results. However, when simulating online training over a year, the model exhibits significant overfitting, with predicted values (
y_pred) mirroring true values (y_true) but with a one-day lag.
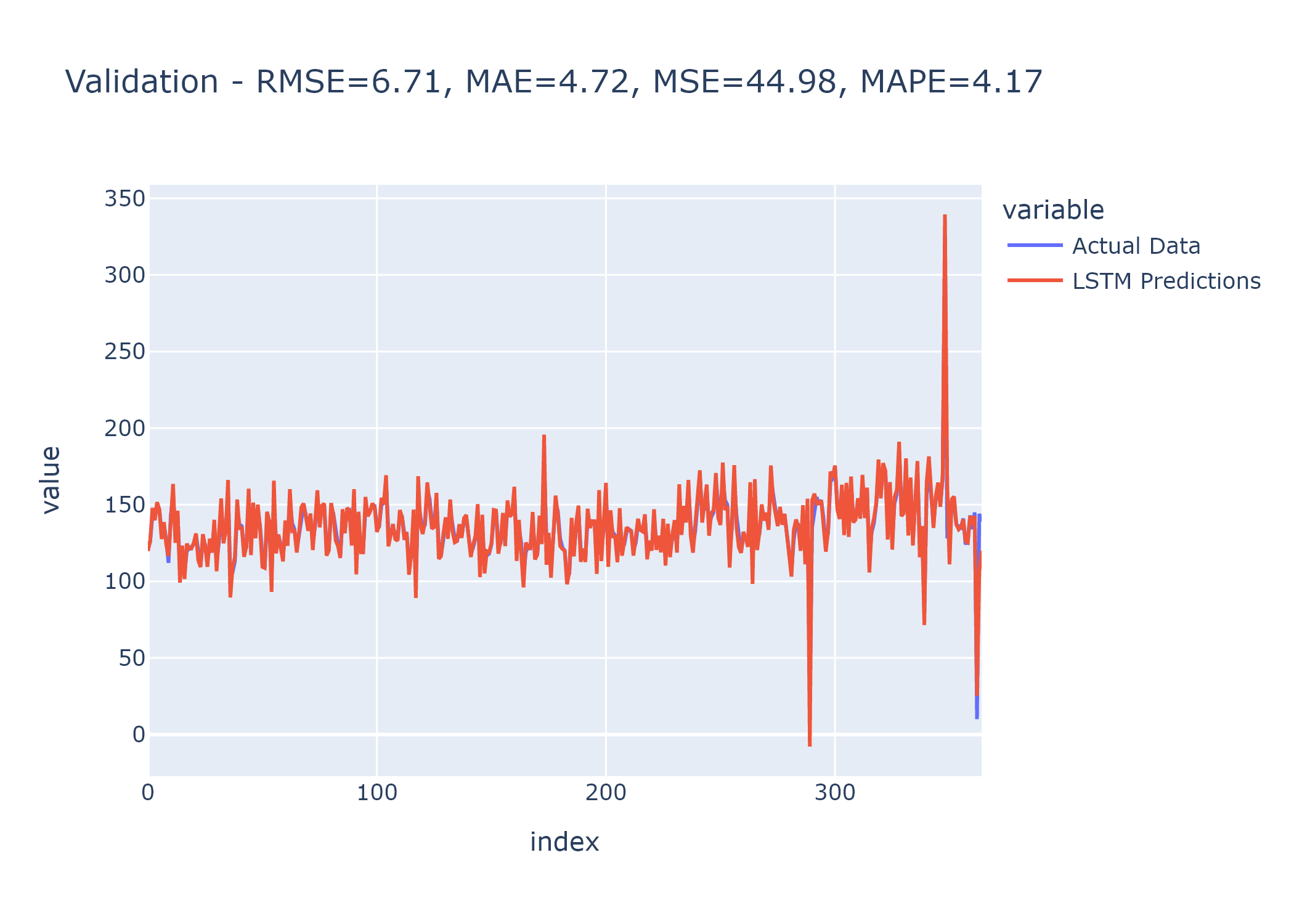
- Spikes in Predictions:
- Occasionally, the LSTM produces spikes in predictions. I’ve explored batch normalization as a solution, and while implementing it during the training loop is effective, it fails during online training due to feeding the network with a batch of length 1 at a time.
Here’s an overview of my code structure:
- I have implemented the code as a script with various functions such as
split_sequenceandonline_training. - The architecture involves creating sequences from the input data. For instance, if
Xhas a shape of (2000, 14) with 14 columns/features, applying the sequence function results in a shape of (2000, 7, 14) with 7 as the lookback value.
def split_sequences(input_sequences, output_sequence, n_steps_in, n_steps_out):
X, y = list(), list() # instantiate X and y
for i in range(len(input_sequences)):
# find the end of the input, output sequence
end_ix = i + n_steps_in
out_end_ix = end_ix + n_steps_out - 1
# check if we are beyond the dataset
if out_end_ix > len(input_sequences): break
# gather input and output of the pattern
seq_x, seq_y = input_sequences[i:end_ix], output_sequence[end_ix - 1:out_end_ix, -1]
X.append(seq_x), y.append(seq_y)
return np.array(X), np.array(y)
- The data is then split into training, validation, and test tensors, where the test set (
X_test) consists of 365 days, and the remaining data is split into an 80/20 ratio for training and validation tensors. - The initial training involves training the model on
X_trainwith early stopping based on the validation setX_val. - To simulate real-world usage, the
update_loopfunction runs the model every day, forecasts for the next 7 days, retrains the model on new data, and repeats the process.
Despite setting h_prev and c_prev to None at every step and trying different sequence lengths(even 1 to hide previous days data), the issue persists. Additionally, modifying the loss computation to focus only on the initial values of y_true and y_pred did not yield any improvement.
I’m seeking guidance on resolving the one-day lag issue and understanding why the model is consistently producing almost correct outputs during online training, even with a poorly trained initial model.
Additionally, interested individuals can find the test on my GitHub repository. It’s worth noting that while the dataset provided in the test is not the private dataset I’m currently working with, the same issue arises with the randomly generated dataset used for testing purposes.
You can find the code and illustration on this repository to test my problem :
By default it s torch for cpu in requirement.txt do not hesitate to reinstall in your environment torch with cuda to accelerate it.