Hello, I am working on a lung nodule classification problem, as either benign or malignant. The inputs are CT volumes in 3D. We have segmentations for each nodule, so all other tissues around the nodule are removed.
The dataset is highly imbalanced, with thousands of benign nodules samples, and only a few hundred malignant samples. I am using the WeightedRandomSampler, as it is suggested in other posts. I also added weights to the cross-entropy loss function (3.0 for the positive class: malignant). The function used to calculate the validation accuracy is the F beta score, with weight 0.5, to give more weight to the recall. The model used is DenseNet 121.
In general, I see the loss function going down, but the recall of the model in the test set goes down too, as the epochs progress. I was hoping for the opposite, to have a higher test recall. Do you have any suggestions? I can give more details if needed.
Depending on the details of your use case and the complexity of your model,
a few hundred positive samples might not be enough to train effectively. (You
should be able to overfit and get “good” results on your training set, without
necessarily getting good results on your validation set.)
If this is the case (and you can’t get more data), you should consider trying data augmentation, where you make additional semi-synthetic input data by
doing “irrelevant” things like stretching or cropping or rotating your real images.
This can permit you to train longer on “more” data, while reducing the risk of
overfitting.
This would be my preferred approach to an unbalanced dataset, assuming
that you have enough positive samples (relative to your batch size) that it is
unlikely for a given batch to contain duplicate positive samples.
This is also a reasonable approach (although I would lean against using
both WeightedRandomSampler and a loss-function weight, if only to make
the training process easier to reason about).
I’m curious how you came up with 3.0 for your positive-class weight.
Greater context would be helpful. I would suggest that you look at graphs, as
a function of training epoch, of not only the recall for your training set, but the
loss, recall, and accuracy (and any other performance metrics you especially
care about, such as your F-beta score), for both your training and validation
datasets. The idea would be to see how all of these evolve as you train, look
for any evidence of overfitting, and so on.
In particular, if your validation-set loss function is going down nicely, but your
validation-set performance metrics are also degrading, you would want to
understand why you have a disconnect between your loss function and your
performance metrics.
As a summary, the WeightedRandomSampler gave me good results. I tried some data augmentation but it didn’t really help to increase the performance. Also, I removed the loss-function weights, as I did not see any major change. The 3.0 weight was just a guess.
An interesting fact when I plotted the loss-function vs validation is that it took very few epochs, around 3 to 6, to reach the highest values. Then, early-stopping was very helpful.
My guess is that because I use already segmented lung nodules (around 10-20% of the image is the nodule and 80-90% is just uniform background), there is not much data to process, and it doesn’t take too many epochs to fit the model.
I could get around 84 - 86 % accuracy, sensitivity, and specificity, which is state-of-the-art for the DenseNet. I plan to try other architectures, like Vision Transformers, which seem to generate more accurate results.
My view of data augmentation is not that – all else being equal – it will lead
to better performance. Rather, using data augmentation will hopefully delay
the onset of overfitting so that you can achieve better performance by training
longer (without overfitting).
If your goal is to achieve the best performance metrics you can (and you have
sufficient computing resources) I would suggest using data augmentation and
training until overfitting clearly sets in.
Six epochs seems very small to me, especially given that an epoch only contains
a few hundred positive samples. (Six epochs seems small even for fine tuning a
pre-trained model.)
I would suggest that you try training significantly longer so that you can get a feel
for how your loss and performance metrics bounce around from epoch to epoch.
You don’t want to mistake epoch-to-epoch “noise” for your training starting to level
off. If your loss curve does start to level off (taking into consideration observed
“noise”), but you don’t yet see clear signs of overfitting, keep training. Sometimes
you can get “stuck” on a plateau, but with significant additional training you can
get unstuck and your model can continue to improve. (And try data augmentation
to delay overfitting as much as possible.)
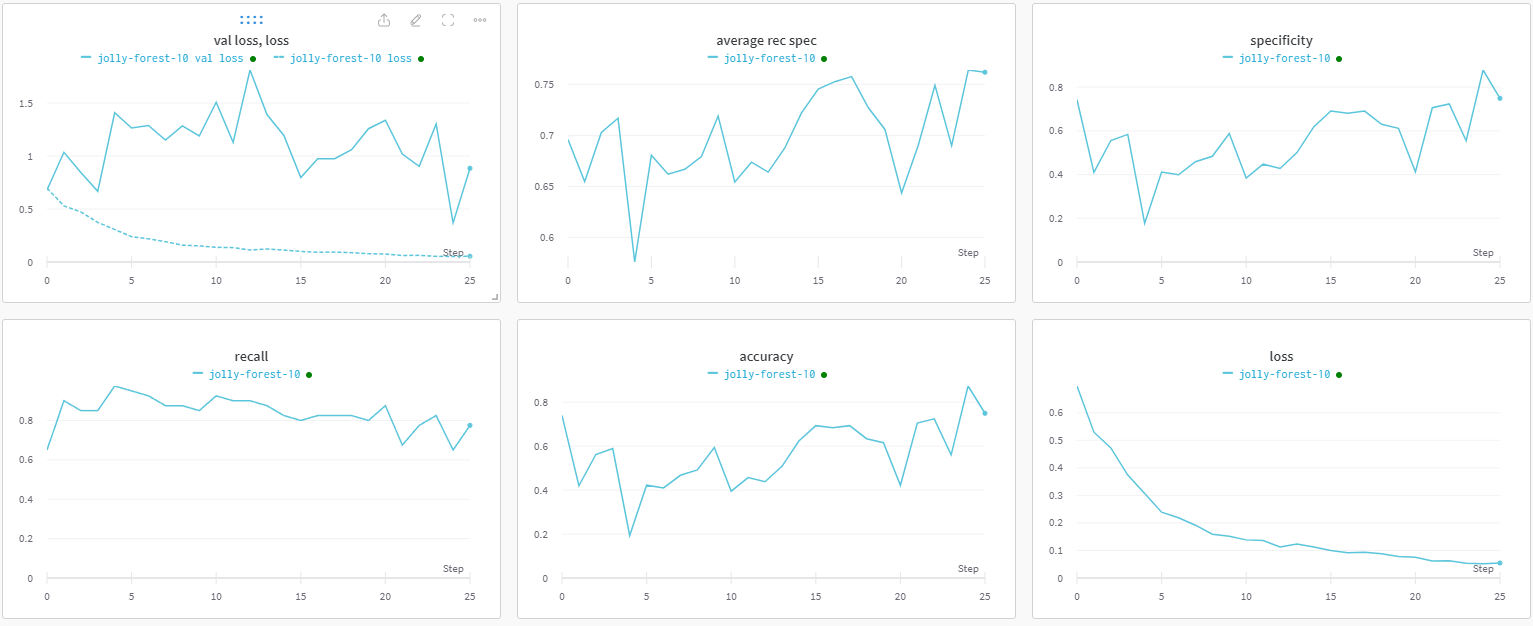
I decided to use weights and biases to plot the progress of the training. As it can be seen below, the loss goes down together with the recall, while the specificity and accuracy go up.
I am interested in optimising the average of recall and specificity, but it reaches a peak around epoch 17. Has this happened to you before? Any strategy you could suggest for this?
I plan to try dropout to delay overfitting, as you suggested, but I am also wondering if my loss function (torch.nn.BCEWithLogitsLoss) is not the right one.
With the exception of your (training) loss curve, these all seem sufficiently
noisy so as to prevent any conclusions from being drawn.
Your graph titled “val loss, loss” (the upper-left graph in the set of six) looks
quite odd. What appears to be your training loss is nice and smooth, while
your “val loss” is very noisy. Is your validation dataset much smaller than
your training dataset, or otherwise significantly different in character?
There is so much epoch-to-epoch noise in your “average rec spec” graph
that you can’t really conclude that such a peak is meaningful.
Assuming you manage to get your noise issue under control, you might want
to reconsider data augmentation as another tool to delay overfitting.
My understanding is that you do have a binary-classification problem: either
benign or malignant. Assuming that your prediction is a logit, typically the
output of a final Linear layer with out_features = 1 and no subsequent
“activations” such as sigmoid(), then yes, BCEWithLogitsLoss will be an
appropriate loss criterion.