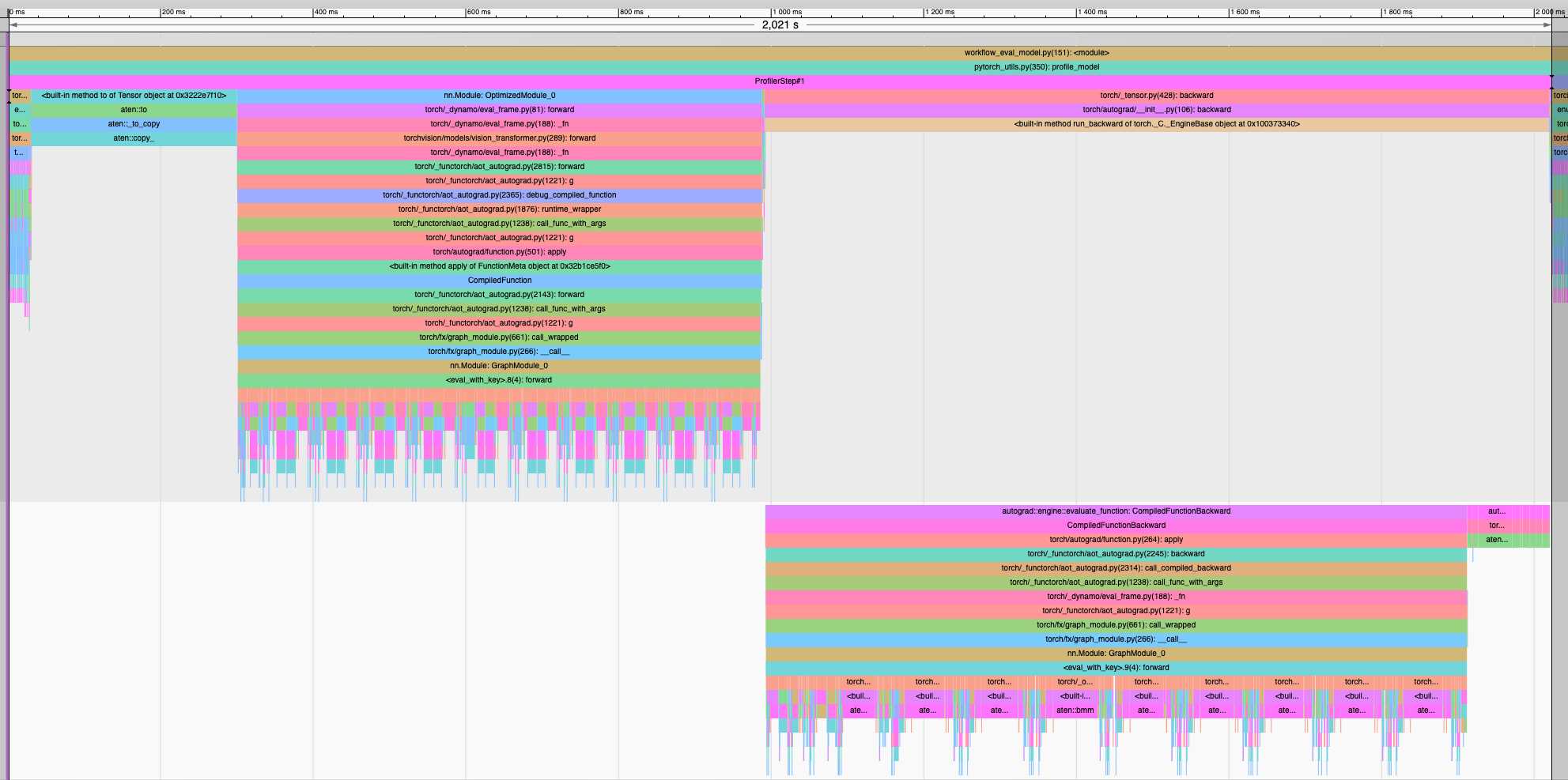
When trying to train a custom classifier (4 output features) based on the torchvision.models.resnet18 model on an M1 MacBook Air, I notice that the majority of the time logged when profiling is spent copying the image batches (standard 224x224 3-channel ImageNet resolution) to the mps device. This happens regardless of whether the model is compiled or not. Is this expected behavior?
Using torch.profiler with both a wait+skip step, a typical cycle takes about 165 ms. The table and picture below shows how this time is distributed with a batch size of 16 images.
Process | Time (ms)| Cycle ratio (%)
------------------------------------------------|------------|----------------
DataLoader (read img, uint8->float32, normalize)| 24.8 ms | 15 %
Copy to GPU | 105.2 ms | 64 %
Forward pass (incl. loss) | 16.7 ms | 10 %
Backprop (incl. use_grad) | 17.9 ms | 11 %
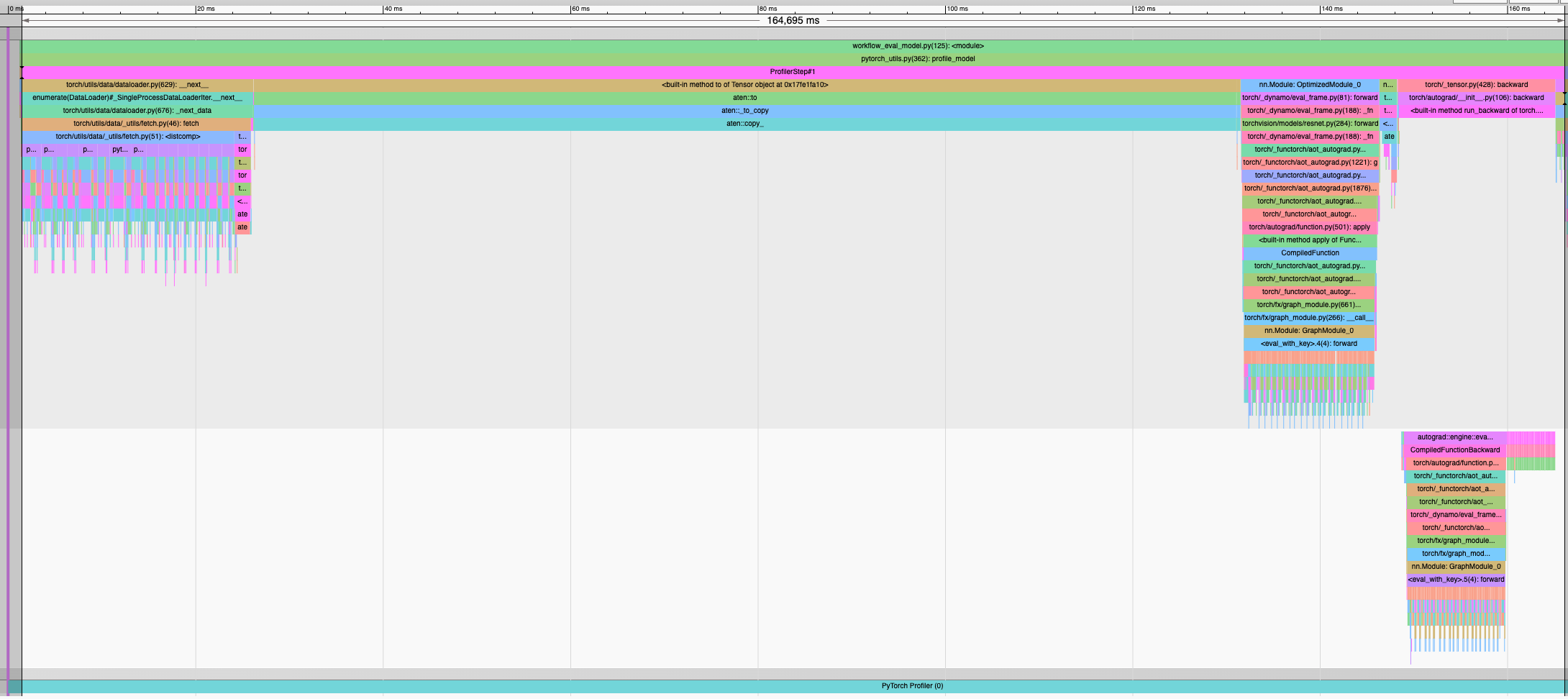
As shown, almost 2/3 of the training consists of the aten__::copy_ operator, which I find pretty strange.