I’ve trained a small autoencoder on MNIST and want to use it to make predictions on an input image. This is what I do, in the same jupyter notebook, after training the model.
example_index = 67
# make example a torch tensor
value = torch.from_numpy(x_train[example_index])
# then put it on the GPU, make it float and insert a fake batch dimension
test_value = Variable(value.cuda())
test_value = test_value.float()
test_value = test_value.unsqueeze(0)
# pass it through the model
prediction = model(test_value)
# get the result out and reshape it
cpu_pred = prediction.cpu()
result = cpu_pred.data.numpy()
array_res = np.reshape(result, (28,28))
then I plot both model output and this input. No matter how I change the input, the output image is exactly the same. Any ideas?
It’s good practice to call model.eval() to switch to “evaluate” mode before predictions. Currently the only layers this affects are batch norm and dropout (so if you don’t have those types of layers it won’t make a difference)
Printed out all intermediary layers. None look like they should. I don’t really understand why this happens.
Don’t understand what model.eval() does. My model class has no method called eval. I included it into my code and it does absolutely nothing.
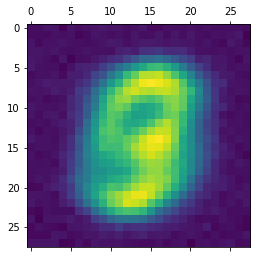
This is what I get on mnist:
Output
Output is exactly the same no matter what input example I give. ( I wanted to put all layers, but this forum does not allow that…)
Still trying to make it work. Here is my training log:
Epoch 1 training loss: 0.148
Epoch 1 validation loss: 0.097
Epoch 2 training loss: 0.083
Epoch 2 validation loss: 0.075
Epoch 3 training loss: 0.071
Epoch 3 validation loss: 0.070
Epoch 4 training loss: 0.067
Epoch 4 validation loss: 0.070
Epoch 5 training loss: 0.067
Epoch 5 validation loss: 0.069
Epoch 6 training loss: 0.067
Epoch 6 validation loss: 0.069
Epoch 7 training loss: 0.067
Epoch 7 validation loss: 0.069
Epoch 8 training loss: 0.067
Epoch 8 validation loss: 0.069
Epoch 9 training loss: 0.067
Epoch 9 validation loss: 0.069
Epoch 10 training loss: 0.067
Epoch 10 validation loss: 0.069
The validation loss is slightly higher than the training loss because I’m averaging it over the entire test set, as opposed to over 2000 minibatches (as with the test set). This is a small issue I will solve later.
Loss function is MSE and learning rate is 0.0001.
EDIT: WORKS !
The only change I made was to go from optimizer.SGD to optimizer.Adam. Any idea why this has such a huge effect?
I know this is super late, but I think that problem is related to a local minima, like the average of all the training images, and SGD gets stuck in that minimum.