Hello!
I’m very new to Machine learning, I’ve created my own PPO implementation and am trying to implement MAML in the RL domain.
I am trying to replicate something like the following results shown in the original MAML paper:
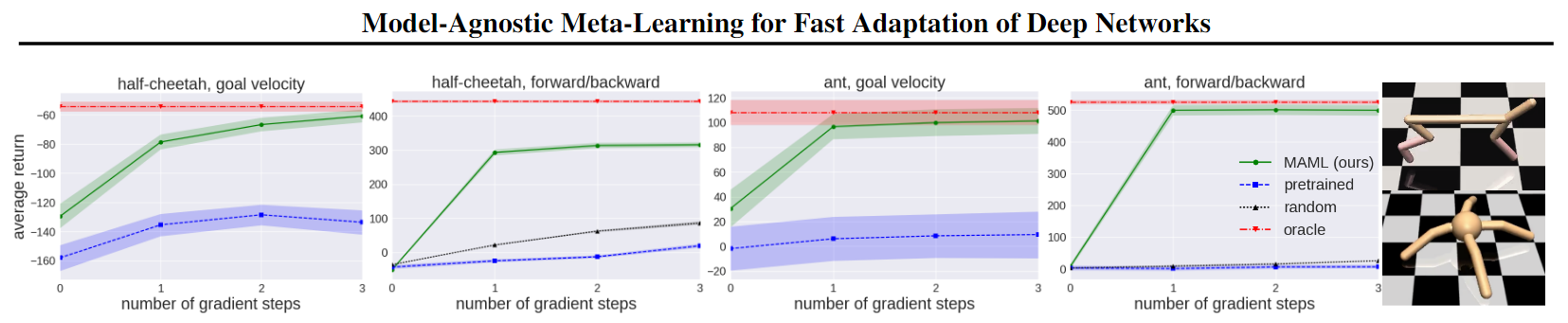
However, I’ve been using MetaWorld as my testing environments, specifically ML10.
My task distribution was 50 environments with randomly assigned tasks from ML10.
Hyperparameters:
- tasks per meta update = 5
- metaLr = 1e-2
- meta iterations = 100
- inner trajectory length = 500 (1 episode)
- innerLr = 5e-2
- inner trajectories per gradient step = 20
After meta training, I’ve been validating by comparing a PPO agent using my meta-trained weights, to a freshly initialised PPO agent, on the ML10 test tasks and observing their average return after 0-4 Episodes->NetworkUpdates. I did 30 episodes of evaluation after each Network update.
Here are some of the results I’ve been getting (note the legend is wrong from - the red is the meta agent:
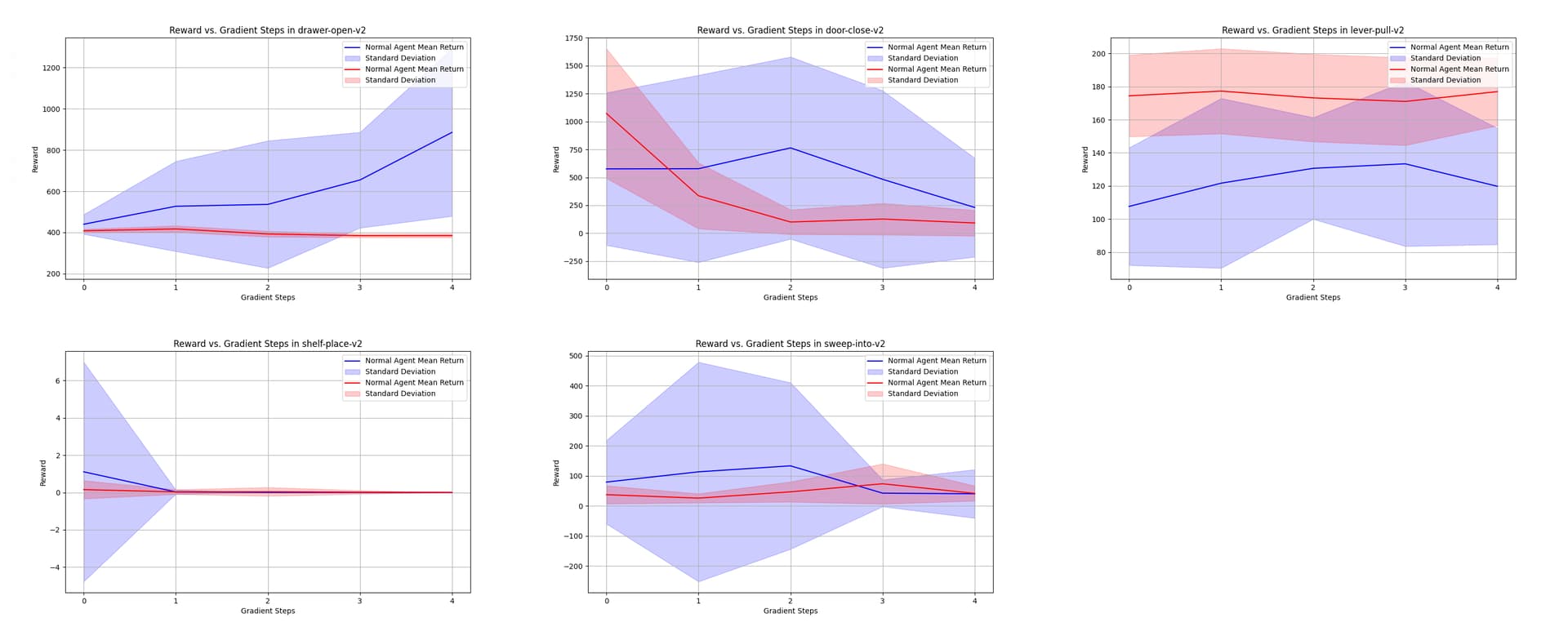
I’ve tried my hardest to work this out myself but I’m pretty stumped, can someone more knowledgeable than me spot the errors in implementation? I’ve been stuck for weeks trying to work this out.
class MAMLMetaLearner():
def __init__(self, envs, tasks=5, metaLr=3e-3, metaSteps=30, innerTimeSteps=500, innerLr=1e-2, innerRollouts=20):
self.envs = envs
self.env = None
self.metaLr = metaLr
self.innerTimeSteps = innerTimeSteps
self.innerLr = innerLr # inner learning rate is generally higher than the meta learning rate
self.metaSteps = metaSteps
self.tasks = tasks # number of tasks to train on per meta iteration
self.innerRollouts = innerRollouts # number of rollouts for inner loop training
self.metaAgent = PPO("MLP", self.envs[0], lrAnealling=False, progressBar=False) # meta agent
self.metaOptimizer = torch.optim.Adam(self.metaAgent.actorCritic.parameters(), lr=metaLr)
self.metaLoss = []
# train the agent on a single task
def ComputeTaskLoss(self, env):
self.metaAgent.env = env # set the environment for inner loop learning
# adapt the task agent parameters using the task model
state = None
# in order to not break the computational graph I will create a dictionary of the inner loop parameters
adaptedParametersDictionary = {name: parameter for (name, parameter) in self.metaAgent.actorCritic.named_parameters()}
for step in range(self.innerRollouts):
state, states, actions, oldLogProbabilities, returns, advantages, _, _ = self.metaAgent.CollectTrajectories(totalTimesteps=self.innerTimeSteps, state=state, parameters = adaptedParametersDictionary, batchSize=self.innerTimeSteps) # collect trajectories using the task agent
if len(advantages) > 1:
advantages = (advantages - advantages.mean()) / torch.max(advantages.std(), torch.tensor(1e-9, device=self.metaAgent.device))
if self.metaAgent.discreteActionSpace:
actionLogits, values = self.metaAgent.ForwardPass(states, parameters=adaptedParametersDictionary)
newProbabilityDistribution = Categorical(logits=actionLogits) # using categorical is good because it provides functions to sample and calculate log probabilities
newLogProbabilities = actionDistribution.log_prob(actions)
else:
mean, standardDeviation, values = self.metaAgent.ForwardPass(states, parameters=adaptedParametersDictionary)
newProbabilityDistribution = torch.distributions.Normal(mean, standardDeviation)
newLogProbabilities = (newProbabilityDistribution.log_prob(actions)).sum(dim=-1)
probabilityRatio = torch.exp(newLogProbabilities - oldLogProbabilities) # this is a measure of how much the policy has changed from the old policy
# compute loss
loss, _, _, _ = self.metaAgent.ComputeLoss(values, returns, newProbabilityDistribution, probabilityRatio, advantages)
self.metaAgent.optimizer.zero_grad() # zero the gradients
# compute gradients with respect to adapted parameters
gradients = torch.autograd.grad(loss, adaptedParametersDictionary.values(), create_graph=True)
# update the adapted parameters using the gradients
adaptedParametersDictionary = {name: parameter - self.innerLr * gradient for ((name, parameter), gradient) in zip(adaptedParametersDictionary.items(), gradients)}
# compute loss after adaptation
_, states, actions, newLogProbabilities, returns, advantages, _, _ = self.metaAgent.CollectTrajectories(totalTimesteps=self.innerTimeSteps, parameters=adaptedParametersDictionary, batchSize=self.innerTimeSteps) # collect trajectories using the updated task agent
if len(advantages) > 1:
advantages = (advantages - advantages.mean()) / torch.max(advantages.std(), torch.tensor(1e-9, device=self.metaAgent.device))
if self.metaAgent.actorCritic.discreteActionSpace:
actionLogits, _ = self.metaAgent.actorCritic(states)
actionDistribution = Categorical(logits=actionLogits) # using categorical is good because it provides functions to sample and calculate log probabilities
oldLogProbabilities = actionDistribution.log_prob(actions)
else:
mean, standardDeviation, _ = self.metaAgent.actorCritic(states)
oldProbabilityDistribution = torch.distributions.Normal(mean, standardDeviation)
oldLogProbabilities = (oldProbabilityDistribution.log_prob(actions)).sum(dim=-1)
# calculate newProbabilityDistribution
if self.metaAgent.actorCritic.discreteActionSpace:
actionLogits, values = self.metaAgent.ForwardPass(states, parameters=adaptedParametersDictionary)
newProbabilityDistribution = Categorical(logits=actionLogits)
else:
mean, standardDeviation, values = self.metaAgent.ForwardPass(states, parameters=adaptedParametersDictionary)
newProbabilityDistribution = torch.distributions.Normal(mean, standardDeviation)
probabilityRatio = torch.exp(newLogProbabilities - oldLogProbabilities) # this is a measure of how much the policy has changed from the original policy
adaptedLoss, _, _, _ = self.metaAgent.ComputeLoss(values, returns, newProbabilityDistribution, probabilityRatio, advantages)
return adaptedLoss
def MetaTrain(self):
print("Meta Training Started...")
count = 0
smallestLoss = -float("inf")
for metaIteration in tqdm(range(self.metaSteps), desc="Meta Training Progress", unit = "iterations"):
metaLoss = 0.0
tasks = [random.choice(self.envs) for task in range(self.tasks)] # randomly select tasks from the environment list
for task in tasks:
taskLoss = self.ComputeTaskLoss(task) # inner loop learning
metaLoss = metaLoss + taskLoss
metaLoss = metaLoss / self.tasks
# meta update
self.metaOptimizer.zero_grad() # zero the gradients
torch.nn.utils.clip_grad_norm_(self.metaAgent.actorCritic.parameters(), 0.5) # clip the gradients
# apply the meta gradients
metaGradients = torch.autograd.grad(metaLoss, self.metaAgent.actorCritic.parameters()) # compute gradients
for parameter, gradient in zip(self.metaAgent.actorCritic.parameters(), metaGradients):
parameter.grad = gradient
self.metaOptimizer.step()
count += 1
print(f"Iteration {len(self.metaLoss)} , Loss: {metaLoss.item()}. {count} training iterations completed this session")
print("Meta Training Complete")
The MAML class borrows functions from my PPO implementation, eg: CollectTrajectories, from my PPO implementation. The MAML class uses it for collecting rollouts
CollectTrajectories
def CollectTrajectories(self, totalTimesteps, progressBar=None, timesteps=0, state=None, parameters=None, batchSize=None):
self.actorCritic.eval() # Set the network to eval mode to disable dropout during rollout
# sanity check
if state is None:
state, _info = self.env.reset()
# if the batch size is not specified, use the default batch size
if batchSize is None:
batchSize = self.batchSize // self.env.num_envs
# if the environment is vectorised, we need to handle the batch tensors differently
if self.env.is_vector_env:
observationSpace = self.env.unwrapped.single_observation_space.shape
actionSpace = self.env.unwrapped.single_action_space.shape
else:
observationSpace = self.env.observation_space.shape
actionSpace = self.env.action_space.shape
# tensors for each environment's trajectory (dimensions: [batch_size, num_envs, ...])
states = torch.zeros((batchSize, self.env.num_envs, *observationSpace), dtype=torch.float, device=self.device)
actions = torch.zeros((batchSize, self.env.num_envs, *actionSpace), dtype=torch.float, device=self.device)
rewards = torch.zeros(batchSize, self.env.num_envs, dtype=torch.float, device=self.device)
logProbabilities = torch.zeros(batchSize, self.env.num_envs, dtype=torch.float, device=self.device)
values = torch.zeros(batchSize, self.env.num_envs, dtype=torch.float, device=self.device)
dones = torch.zeros(batchSize, self.env.num_envs, dtype=torch.bool, device=self.device)
if timesteps == 0:
state, _info = self.env.reset() # [num_envs, [single_observation_space]]
done = torch.zeros(self.env.num_envs).to(self.device)
truncated = torch.zeros(self.env.num_envs).to(self.device)
with torch.no_grad():
# collect a batch of trajectories to train the network
for step in range(0, (batchSize)):
timesteps += 1 * self.env.num_envs
state = torch.tensor(state, dtype=torch.float, device=self.device)
states[step] = state
if self.discreteActionSpace:
actionLogits, value = self.ForwardPass(state, parameters)
actionDistribution = Categorical(logits=actionLogits)
action = actionDistribution.sample()
if not self.env.is_vector_env:
action = action.squeeze() # a single environment would expect a value without the extra dimension
logProbability = actionDistribution.log_prob(action)
else:
mean, standardDeviation, value = self.ForwardPass(state, parameters)
actionDistribution = torch.distributions.Normal(mean, standardDeviation)
action = actionDistribution.sample()
logProbability = (actionDistribution.log_prob(action)).sum(dim=-1)
actions[step] = action
nextState, reward, done, truncated, info = self.env.step(action.cpu().numpy())
done = torch.tensor(done, dtype=torch.bool, device=self.device)
truncated = torch.tensor(truncated, dtype=torch.bool, device=self.device)
dones[step] = torch.logical_or(done, truncated)
rewards[step] = torch.tensor(reward, dtype=torch.float, device=self.device)
values[step] = value.squeeze() # remove the extra dimension
logProbabilities[step] = logProbability
state = nextState
# episode termination handling
for i in range(self.env.num_envs):
if info:
if self.env.is_vector_env:
if "_episode" in info: # check if the key "_episode" exists
if info["_episode"][i]: # if THE episode has ended
episodeMetrics = info.get('episode', {}) # get the metrics of the episode that ended
self.episodeLengths.append(episodeMetrics.get('l', [0])[i])
self.totalEpisodeRewards.append(episodeMetrics.get('r', [0])[i])
elif (done or truncated):
episodeMetrics = info.get('episode')
self.episodeLengths.append(episodeMetrics.get('l', 0).item())
self.totalEpisodeRewards.append(episodeMetrics.get('r', 0).item())
state, _info = self.env.reset() # single environments are not automatically reset
# update the progress bar
if self.progressBar:
progressBar.update(self.env.num_envs)
if timesteps >= totalTimesteps: # if the last batch exceeds the total timesteps end early
break
# we need to know the value of the next state for the last state in the batch and if it was terminal
with torch.no_grad():
if self.discreteActionSpace:
_actionLogits, lastNextValues = self.actorCritic(torch.tensor(state, dtype=torch.float, device=self.device)) # get the value of the next state
else:
_mean, _standardDeviation, lastNextValues = self.actorCritic(torch.tensor(state, dtype=torch.float, device=self.device))
lastNextValues = lastNextValues.squeeze()
if self.profiling:
self.logMemoryUsage("after_batch/before_advantages&returns")
# calculate the advantages for the batch
returns = self.GetReturns(rewards, dones, lastNextValues)
advantages = self.GetAdvantages(rewards, values, dones, lastNextValues)
# flatten the trajectories
states = states.view(-1, *states.shape[2:])
logProbabilities = logProbabilities.view(-1)
returns = returns.view(-1)
advantages = advantages.view(-1)
if self.discreteActionSpace:
actions = actions.view(-1)
else:
actions = actions.view(-1, actions.size(-1) if actions.ndim > 2 else 1)
return state, states, actions, logProbabilities, returns, advantages, timesteps, progressBar
Here is my ForwardPass function, used to collect inner loop rollouts without breaking the computational graph. When I want to use the actual networks weights, i just don’t pass a parameter input.
ForwardPass
def ForwardPass(self, state, parameters):
if parameters is None:
return self.actorCritic(state)
# if the parameters are not None, we are using the network for MAML and need to pass the adapted parameters to the forward function
else:
return func.functional_call(self.actorCritic, parameters, state)
The I calculate my loss in the MAML class with this ComputeLoss function.
ComputeLoss
def ComputeLoss(self, values, returns, probabilityDistribution, probabilityRatio, advantages):
# calculate the value loss under the current critic network
values = values.squeeze() # remove the extra dimension
valueLoss = functional.smooth_l1_loss(returns, values) # smooth l1 loss is less sensitive to outliers
# calculate the entropy loss
entropyLoss = -probabilityDistribution.entropy().mean()
# calculate policy loss
surrogate1 = probabilityRatio * advantages
surrogate2 = torch.clamp(probabilityRatio, 1 - self.epsilon, 1 + self.epsilon) * advantages
# PPO attempts to maximise the clipped objective function but ADAM minimises the loss so we add a negative sign
policyLoss = -torch.min(surrogate1, surrogate2).mean()
# combine all the losses
loss = policyLoss + (valueLoss * self.valueLossCoef) - (entropyLoss * self.entropyCoef) # the entropy loss is subtracted because we want to maximise entropy
return loss, valueLoss, policyLoss , entropyLoss