Hello everyone,
Introduction: I am currently working on a computer vision problem, I have satellite images and I have to detect a particular archeological structure (Tell).
I have access to the previously made researches and I have access to a Manet model trained on 5 thousand images of mesopotamic area.
My project objective is to fine-tune this model in order to detect the same archeological structure in different geographical areas which have different characteristics, the problem is that I have something like 200 images of the “new” area which is why I am trying to fine-tune the old model I have access to.
The problem in few words is: which layers do you usually add on top of a base model for finetuning?
All the tutorial I have found online are for classification problems, however, the output of my model is a mask in (N, H, W) → P format where N is the batch size, and H and W are respectively height and width whereas p is the probability that the particular pixel belongs to the “Tell” or not (binary semantic segmentation). So if you have better tutorials I can follow it would be great. I did not find any tutorial about making a custom segmentation head to concatenate over an existing segmentation model like Unet or MaNet.
Thats what I am now thinking to do, is it sound correct to you?
- freeze old model weights
- add GlobalAveragePooling2D layer
- add Dropout(0.2) layer
- add Dense(512, 512) (imgs size)
- fine tuning
- unfreeze old model weights
- finetune the entire model with very low lr
While I know the whole workflow is correct, the thing that worries me the most is the process of editing the model (points 2-3-4), does it make sense?
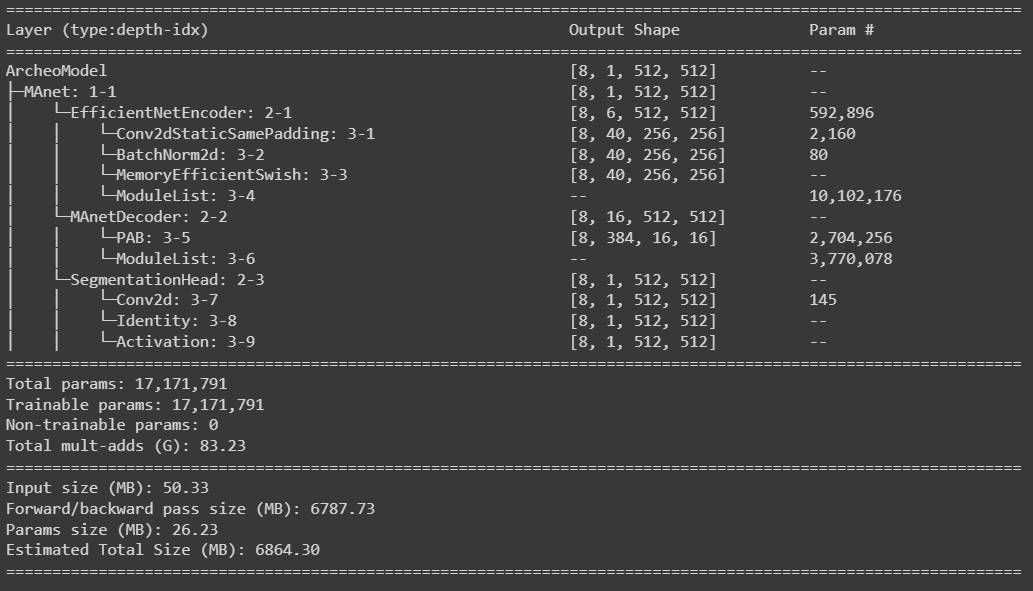
Thats the model summary with batch size 8 and image channels = 6: