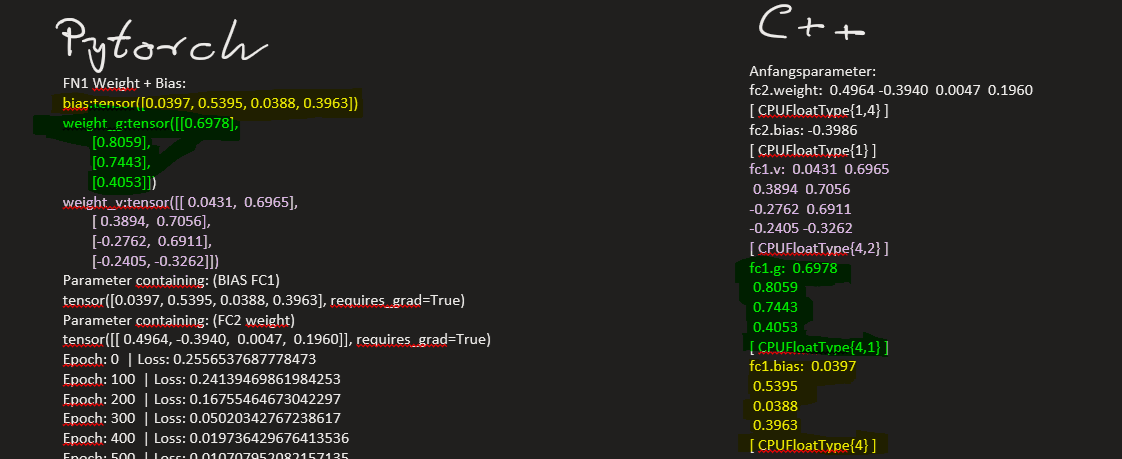
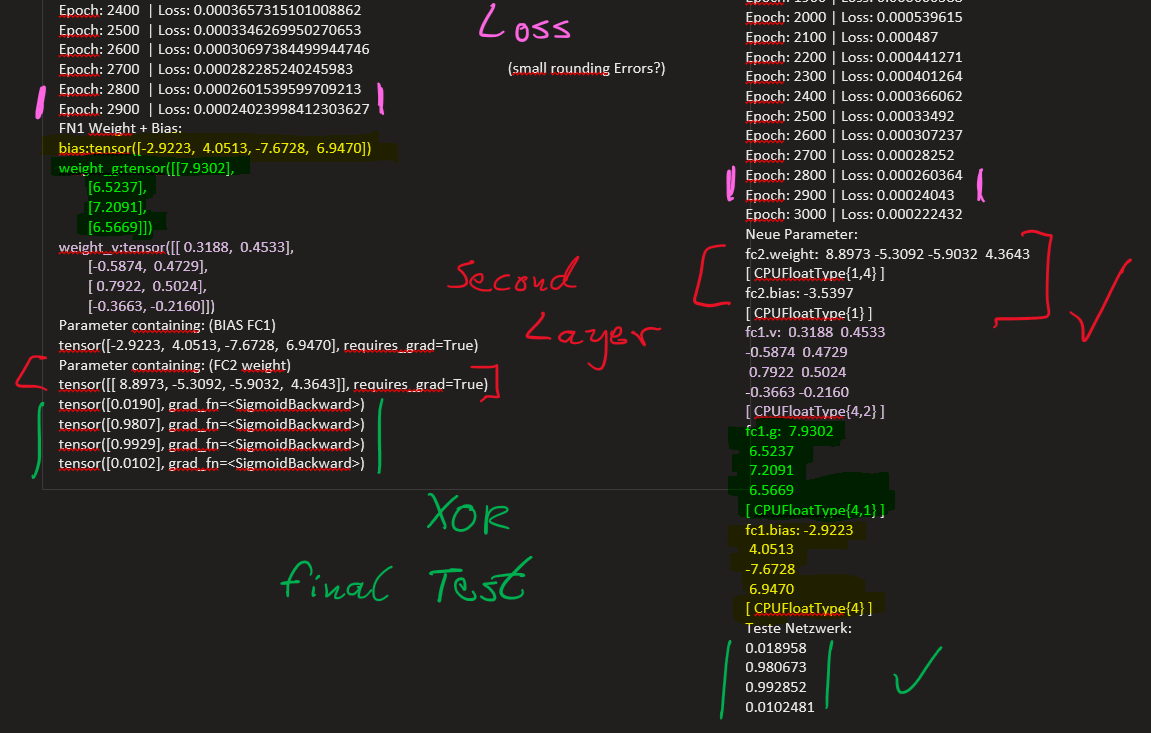
Hello Pytorch Community,
since at this point in time, there’s no weight normalization available in Libtorch, but I still need it to port a model over to the C++ API, I tried to manually implement it in C++. I used the source code for the python implementation: https://pytorch.cn/docs/master/_modules/torch/nn/utils/weight_norm.html as inspiration.
But I’m just not sure if I can actually use this in real projects or if this approach is incorrect.
First, in the Constructor of the network, I call init_pre_forward_normalize(*layer) after initialising and registering the layer to my network:
void init_pre_forward_normalize(torch::nn::Module & module)
{
//Since we cannot delete the old Paramter, we treat it as our "weight_v"
//We assume that we only want to apply this normalization to "weight" parameter
auto old_weight = module.named_parameters().find("weight")->data();
torch::Tensor new_weight = _norm(old_weight);
module.register_parameter("weight_g", new_weight.data());
}
Using a simplified _norm function:
torch::Tensor _norm(torch::Tensor &old_weight)
{
//We assume, that always: dim=0
torch::Tensor new_weight;
if (old_weight.dim() == 1)
{
new_weight = old_weight.contiguous().view({ old_weight.size(0), -1 }).norm(2, 1)
.view({ old_weight.size(0) });
}
if (old_weight.dim() == 2)
{
new_weight = old_weight.contiguous().view({ old_weight.size(0), -1 }).norm(2, 1)
.view({ old_weight.size(0), 1 });
}
if (old_weight.dim() == 3)
{
new_weight = old_weight.contiguous().view({ old_weight.size(0), -1 }).norm(2, 1)
.view({ old_weight.size(0), 1, 1 });
}
if (old_weight.dim() == 4)
{
new_weight = old_weight.contiguous().view({ old_weight.size(0), -1 }).norm(2, 1)
.view({ old_weight.size(0), 1, 1, 1 });
}
return new_weight;
}
And then, in the forward Method of my network, I just call pre_forward_normalize(*layer) everytime before using that specific layer’s forward function.
void pre_forward_normalize(torch::nn::Module & module)
{
auto v = *(module.named_parameters().find("weight")); //This will be normalized and stay between -1.0 and 1.0
auto g = *(module.named_parameters().find("weight_g")); //This will stay constant through out Learning process
module.named_parameters().find("weight")->data() = v * (g / _norm(v));
}
I tested it with a simple 2-Linear-Layer Network and the XOR Dataset, and it seems to be working?, since the “weight” parameters of the layers are still changing and the loss is decreasing (though the network’s performance is getting worse, especially when using Normalization on both layers).
I also noticed, that the weight’s values are always between -1.0 and 1.0 for the layers with Normalization, while the “weight_g” values are just staying the same during the training process.
I hope that somebody can look at my code and tell me if there’s something wrong here, because I’m not sure if I can rely on this implementation or not. Any help or suggestions are welcome.
with kind regards, Florian Korotschenko