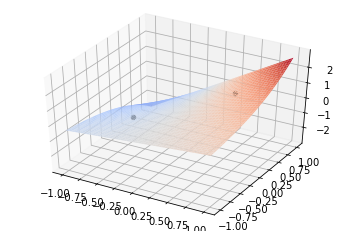
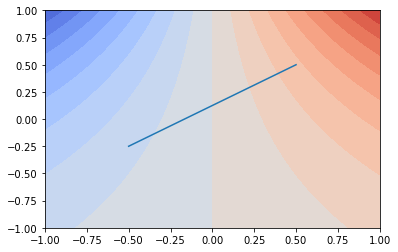
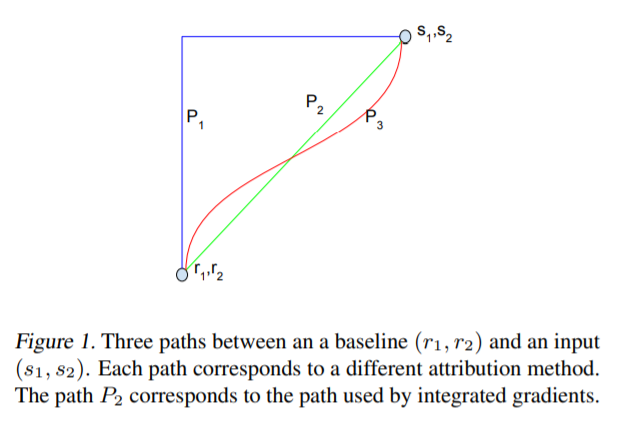
in the paper formula is,
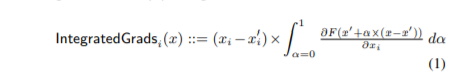
how do we manually calculate this value, for example,
from captum.attr import IntegratedGradients
import torch, torch.nn as nn, torch.nn.functional as F
class ToyModel(nn.Module):
r"""
Example toy model from the original paper (page 10)
https://arxiv.org/pdf/1703.01365.pdf
f(x1, x2) = RELU(ReLU(x1) - 1 - ReLU(x2))
"""
def __init__(self):
super().__init__()
def forward(self, input1, input2):
relu_out1 = F.relu(input1)
relu_out2 = F.relu(input2)
return F.relu(relu_out1 - 1 - relu_out2)
net = ToyModel()
net.eval()
# defining model input tensors
input1 = torch.tensor([3.0], requires_grad=True)
input2 = torch.tensor([1.0], requires_grad=True)
# defining baselines for each input tensor
baseline1 = torch.tensor([0.0])
baseline2 = torch.tensor([0.0])
# defining and applying integrated gradients on ToyModel and the
ig = IntegratedGradients(net)
attributions, approximation_error = ig.attribute((input1, input2),
baselines=(baseline1, baseline2),
method='gausslegendre',
return_convergence_delta=True)
attributions
gives
(tensor([1.5000], grad_fn=),
tensor([-0.5000], grad_fn=))
so, here baseline is 0, 0 input is 3, 1 if our function is,
f(x1, x2) = x1 - 1 - x2
do we replace x1 with x1*alpha, then differentiate wrt x1, so we get alpha, then integrate, so we get alpha**2 / 2 with alpha from 0 to 1, that is 1/2
and same thing for x2, replace x2 with x2*alpha, then differentiate wrt x2, so we get -alpha, then integrate, so we get -alpha**2 / 2 with alpha from 0 to 1, that is -1/2
then multiply these with input, which gives 1.5, -0.5.
what is the intuition behind using this technique, and how does one understand this formula in a better way?