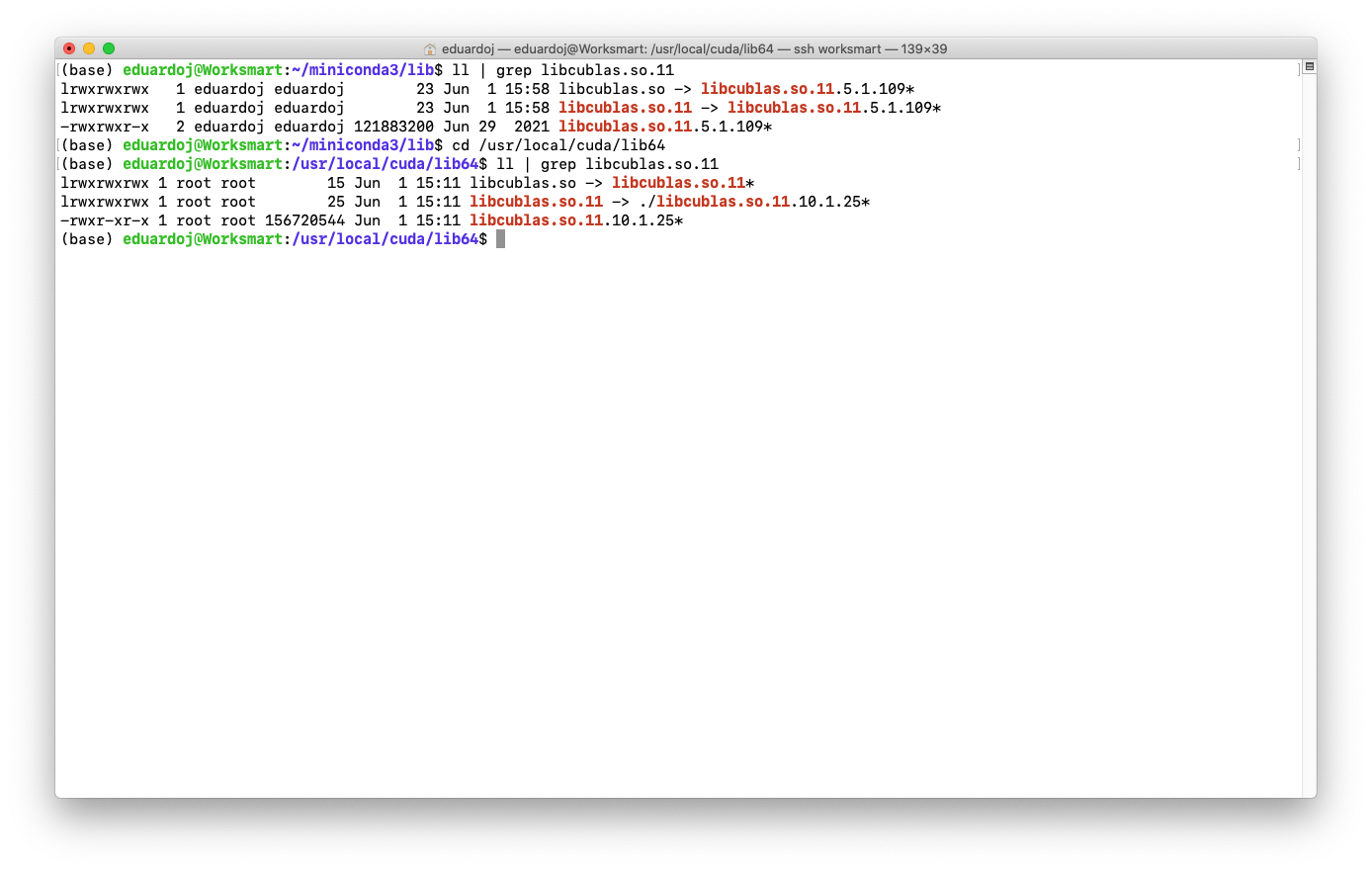
Here is the backtrace output.
(base) eduardoj@Worksmart:~/Repo/eduardo4jesus/PyTorch-cuDNN-Convolution$ gdb python
gdb: /home/eduardoj/miniconda3/lib/libtinfo.so.6: no version information available (required by gdb)
gdb: /home/eduardoj/miniconda3/lib/libncursesw.so.6: no version information available (required by gdb)
gdb: /home/eduardoj/miniconda3/lib/libncursesw.so.6: no version information available (required by gdb)
gdb: /home/eduardoj/miniconda3/lib/libncursesw.so.6: no version information available (required by gdb)
GNU gdb (Ubuntu 12.0.90-0ubuntu1) 12.0.90
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from python...
(gdb) run example.py
Starting program: /home/eduardoj/miniconda3/bin/python example.py
/bin/bash: /home/eduardoj/miniconda3/lib/libtinfo.so.6: no version information available (required by /bin/bash)
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[Detaching after fork from child process 8480]
[New Thread 0x7fff17cdd640 (LWP 8486)]
Using /home/eduardoj/.cache/torch_extensions/py39_cu113 as PyTorch extensions root...
[Detaching after fork from child process 8487]
[Detaching after fork from child process 8488]
[Detaching after fork from child process 8489]
Detected CUDA files, patching ldflags
Emitting ninja build file /home/eduardoj/.cache/torch_extensions/py39_cu113/cudnn_convolution/build.ninja...
Building extension module cudnn_convolution...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[Detaching after fork from child process 8490]
ninja: no work to do.
Loading extension module cudnn_convolution...
Compiled and Loaded!
[New Thread 0x7fff161fdac0 (LWP 8491)]
[New Thread 0x7fff159fbb40 (LWP 8492)]
[New Thread 0x7fff151f9bc0 (LWP 8493)]
[New Thread 0x7fff149f8640 (LWP 8494)]
[New Thread 0x7fff11fff640 (LWP 8495)]
Trying all
Thread 1 "python" received signal SIGSEGV, Segmentation fault.
0x00007fffd73c7eb1 in cublasGetMathMode () from /home/eduardoj/miniconda3/lib/python3.9/site-packages/torch/lib/../../../../libcublas.so.11
(gdb) backtrace
#0 0x00007fffd73c7eb1 in cublasGetMathMode () from /home/eduardoj/miniconda3/lib/python3.9/site-packages/torch/lib/../../../../libcublas.so.11
#1 0x00007ffe2c0b9014 in ?? () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#2 0x00007ffe2c0beff3 in cudnn::winograd_nonfused::conv2dForward(cudnnContext*, CUstream_st*, void const*, cudnnTensor4dStruct const*, void const*, cudnnFilter4dStruct const*, void const*, cudnnConvolutionStruct const*, void*, unsigned long, bool, void const*, void const*, void const*, cudnnTensor4dStruct const*, void*, bool) () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#3 0x00007ffe2bde96b9 in cudnn::cnn::WinogradNonfusedEngine<true>::execute_internal_impl(cudnn::backend::VariantPack const&, CUstream_st*) ()
from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#4 0x00007ffe2b9d3e71 in cudnn::cnn::EngineInterface::execute(cudnn::backend::VariantPack const&, CUstream_st*) ()
from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#5 0x00007ffe2bb46b1e in cudnn::cnn::AutoTransformationExecutor::execute_pipeline(cudnn::cnn::EngineInterface&, cudnn::backend::VariantPack const&, CUstream_st*) const () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#6 0x00007ffe2bb46c23 in cudnn::cnn::BatchPartitionExecutor::operator()(cudnn::cnn::EngineInterface&, cudnn::cnn::EngineInterface*, cudnn::backend::VariantPack const&, CUstream_st*) const () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#7 0x00007ffe2bb62466 in cudnn::cnn::GeneralizedConvolutionEngine<cudnn::cnn::WinogradNonfusedEngine<true> >::execute_internal_impl(cudnn::backend::VariantPack const&, CUstream_st*) () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#8 0x00007ffe2b9d3e71 in cudnn::cnn::EngineInterface::execute(cudnn::backend::VariantPack const&, CUstream_st*) ()
from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#9 0x00007ffe2b9ef9e8 in cudnn::backend::execute(cudnnContext*, cudnn::backend::ExecutionPlan&, cudnn::backend::VariantPack&) ()
from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#10 0x00007ffe2bcd3a19 in cudnn::backend::EnginesAlgoMap<cudnnConvolutionFwdAlgo_t, 8>::execute_wrapper(cudnnContext*, cudnnConvolutionFwdAlgo_t, cudnn::backend::ExecutionPlan&, cudnn::backend::VariantPack&) () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#11 0x00007ffe2bcc6aa8 in cudnn::backend::convolutionForward(cudnnContext*, void const*, cudnnTensorStruct const*, void const*, cudnnFilterStruct const*, void const*, cudnnConvolutionStruct const*, cudnnConvolutionFwdAlgo_t, void*, unsigned long, bool, void const*, void const*, void const*, cudnnActivationStruct const*, cudnnTensorStruct const*, void*) () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#12 0x00007ffe2be2d839 in cudnn::cnn::convolutionForward(cudnnContext*, void const*, cudnnTensorStruct const*, void const*, cudnnFilterStruct const*, void const*, cudnnConvolutionStruct const*, cudnnConvolutionFwdAlgo_t, void*, unsigned long, void const*, cudnnTensorStruct const*, void*) ()
from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#13 0x00007ffe2be3f426 in ?? () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#14 0x00007ffe2be3fe34 in cudnnStatus_t findAlgorithm<find_get_conv_params, cudnnConvolutionStruct, cudnnConvolutionFwdAlgo_t, cudnnConvolutionFwdAlgoPerfStruct, 8, true>(find_get_conv_params, int, int*, cudnnConvolutionFwdAlgoPerfStruct*) () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#15 0x00007ffe2be2dbc9 in cudnnFindConvolutionForwardAlgorithm () from /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8
#16 0x00007fff17480e87 in convolution(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool) () from /home/eduardoj/.cache/torch_extensions/py39_cu113/cudnn_convolution/cudnn_convolution.so
#17 0x00007fff174abce8 in at::Tensor pybind11::detail::argument_loader<int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool>::call_impl<at::Tensor, at::Tensor (*&)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool), 0ul, 1ul, 2ul, 3ul, 4ul, 5ul, 6ul, 7ul, 8ul, 9ul, 10ul, pybind11::detail::void_type>(at::Tensor (*&)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool), std::integer_sequence<unsigned long, 0ul, 1ul, 2ul, 3ul, 4ul, 5ul, 6ul, 7ul, 8ul, 9ul, 10ul>, pybind11::detail::void_type&&) && () from /home/eduardoj/.cache/torch_extensions/py39_cu113/cudnn_convolution/cudnn_convolution.so
--Type <RET> for more, q to quit, c to continue without paging--c
#18 0x00007fff174a7213 in std::enable_if<!std::is_void<at::Tensor>::value, at::Tensor>::type pybind11::detail::argument_loader<int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool>::call<at::Tensor, pybind11::detail::void_type, at::Tensor (*&)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool)>(at::Tensor (*&)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool)) && () from /home/eduardoj/.cache/torch_extensions/py39_cu113/cudnn_convolution/cudnn_convolution.so
#19 0x00007fff174a1bac in pybind11::cpp_function::initialize<at::Tensor (*&)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool), at::Tensor, int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool, pybind11::name, pybind11::scope, pybind11::sibling, char [12]>(at::Tensor (*&)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool), at::Tensor (*)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool), pybind11::name const&, pybind11::scope const&, pybind11::sibling const&, char const (&) [12])::{lambda(pybind11::detail::function_call&)#3}::operator()(pybind11::detail::function_call&) const () from /home/eduardoj/.cache/torch_extensions/py39_cu113/cudnn_convolution/cudnn_convolution.so
#20 0x00007fff174a2238 in pybind11::cpp_function::initialize<at::Tensor (*&)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool), at::Tensor, int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool, pybind11::name, pybind11::scope, pybind11::sibling, char [12]>(at::Tensor (*&)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool), at::Tensor (*)(int, at::Tensor const&, at::Tensor const&, at::Tensor const&, c10::ArrayRef<long>, c10::ArrayRef<long>, c10::ArrayRef<long>, long, bool, bool, bool), pybind11::name const&, pybind11::scope const&, pybind11::sibling const&, char const (&) [12])::{lambda(pybind11::detail::function_call&)#3}::_FUN(pybind11::detail::function_call&) () from /home/eduardoj/.cache/torch_extensions/py39_cu113/cudnn_convolution/cudnn_convolution.so
#21 0x00007fff1748faae in pybind11::cpp_function::dispatcher(_object*, _object*, _object*) () from /home/eduardoj/.cache/torch_extensions/py39_cu113/cudnn_convolution/cudnn_convolution.so
#22 0x00005555556a290c in cfunction_call (func=0x7fff1df514f0, args=<optimized out>, kwargs=<optimized out>) at /usr/local/src/conda/python-3.9.13/Objects/methodobject.c:543
#23 0x0000555555688fa7 in _PyObject_MakeTpCall (tstate=0x55555590fd50, callable=0x7fff1df514f0, args=<optimized out>, nargs=<optimized out>, keywords=<optimized out>) at /usr/local/src/conda/python-3.9.13/Objects/call.c:191
#24 0x0000555555684d5f in _PyObject_VectorcallTstate (kwnames=0x0, nargsf=<optimized out>, args=<optimized out>, callable=0x7fff1df514f0, tstate=<optimized out>) at /usr/local/src/conda/python-3.9.13/Include/cpython/abstract.h:116
#25 _PyObject_VectorcallTstate (kwnames=0x0, nargsf=<optimized out>, args=0x55555596a8c8, callable=0x7fff1df514f0, tstate=<optimized out>) at /usr/local/src/conda/python-3.9.13/Include/cpython/abstract.h:103
#26 PyObject_Vectorcall (kwnames=0x0, nargsf=<optimized out>, args=0x55555596a8c8, callable=0x7fff1df514f0) at /usr/local/src/conda/python-3.9.13/Include/cpython/abstract.h:127
#27 call_function (kwnames=0x0, oparg=<optimized out>, pp_stack=<synthetic pointer>, tstate=0x55555590fd50) at /usr/local/src/conda/python-3.9.13/Python/ceval.c:5077
#28 _PyEval_EvalFrameDefault (tstate=<optimized out>, f=<optimized out>, throwflag=<optimized out>) at /usr/local/src/conda/python-3.9.13/Python/ceval.c:3489
#29 0x000055555567ea17 in _PyEval_EvalFrame (throwflag=0, f=0x55555596a750, tstate=0x55555590fd50) at /usr/local/src/conda/python-3.9.13/Include/internal/pycore_ceval.h:40
#30 _PyEval_EvalCode (tstate=<optimized out>, _co=0x7ffff6dd2870, globals=<optimized out>, locals=<optimized out>, args=<optimized out>, argcount=<optimized out>, kwnames=<optimized out>, kwargs=<optimized out>, kwcount=<optimized out>, kwstep=<optimized out>, defs=<optimized out>, defcount=<optimized out>, kwdefs=<optimized out>, closure=<optimized out>, name=<optimized out>, qualname=<optimized out>) at /usr/local/src/conda/python-3.9.13/Python/ceval.c:4329
#31 0x000055555567e6d7 in _PyEval_EvalCodeWithName (_co=<optimized out>, globals=<optimized out>, locals=<optimized out>, args=<optimized out>, argcount=<optimized out>, kwnames=<optimized out>, kwargs=0x0, kwcount=0, kwstep=2, defs=0x0, defcount=0, kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at /usr/local/src/conda/python-3.9.13/Python/ceval.c:4361
#32 0x000055555567e689 in PyEval_EvalCodeEx (_co=<optimized out>, globals=<optimized out>, locals=<optimized out>, args=<optimized out>, argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0, closure=0x0) at /usr/local/src/conda/python-3.9.13/Python/ceval.c:4377
#33 0x0000555555739e3b in PyEval_EvalCode (co=co@entry=0x7ffff6dd2870, globals=globals@entry=0x7ffff6dc7b00, locals=locals@entry=0x7ffff6dc7b00) at /usr/local/src/conda/python-3.9.13/Python/ceval.c:828
#34 0x00005555557684a9 in run_eval_code_obj (tstate=0x55555590fd50, co=0x7ffff6dd2870, globals=0x7ffff6dc7b00, locals=0x7ffff6dc7b00) at /usr/local/src/conda/python-3.9.13/Python/pythonrun.c:1221
#35 0x0000555555764694 in run_mod (mod=<optimized out>, filename=<optimized out>, globals=0x7ffff6dc7b00, locals=0x7ffff6dc7b00, flags=<optimized out>, arena=<optimized out>) at /usr/local/src/conda/python-3.9.13/Python/pythonrun.c:1242
#36 0x00005555555e96d2 in pyrun_file (fp=0x55555590d4f0, filename=0x7ffff6d69eb0, start=<optimized out>, globals=0x7ffff6dc7b00, locals=0x7ffff6dc7b00, closeit=1, flags=0x7fffffffdf38) at /usr/local/src/conda/python-3.9.13/Python/pythonrun.c:1140
#37 0x000055555575e1f2 in pyrun_simple_file (flags=0x7fffffffdf38, closeit=1, filename=0x7ffff6d69eb0, fp=0x55555590d4f0) at /usr/local/src/conda/python-3.9.13/Python/pythonrun.c:450
#38 PyRun_SimpleFileExFlags (fp=0x55555590d4f0, filename=<optimized out>, closeit=1, flags=0x7fffffffdf38) at /usr/local/src/conda/python-3.9.13/Python/pythonrun.c:483
#39 0x000055555575b533 in pymain_run_file (cf=0x7fffffffdf38, config=0x55555590e490) at /usr/local/src/conda/python-3.9.13/Modules/main.c:377
#40 pymain_run_python (exitcode=0x7fffffffdf30) at /usr/local/src/conda/python-3.9.13/Modules/main.c:602
#41 Py_RunMain () at /usr/local/src/conda/python-3.9.13/Modules/main.c:681
#42 0x000055555572db79 in Py_BytesMain (argc=<optimized out>, argv=<optimized out>) at /usr/local/src/conda/python-3.9.13/Modules/main.c:1101
#43 0x00007ffff7cabd90 in __libc_start_call_main (main=main@entry=0x55555572db30 <main>, argc=argc@entry=2, argv=argv@entry=0x7fffffffe168) at ../sysdeps/nptl/libc_start_call_main.h:58
#44 0x00007ffff7cabe40 in __libc_start_main_impl (main=0x55555572db30 <main>, argc=2, argv=0x7fffffffe168, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffffffe158) at ../csu/libc-start.c:392
#45 0x000055555572da81 in _start ()