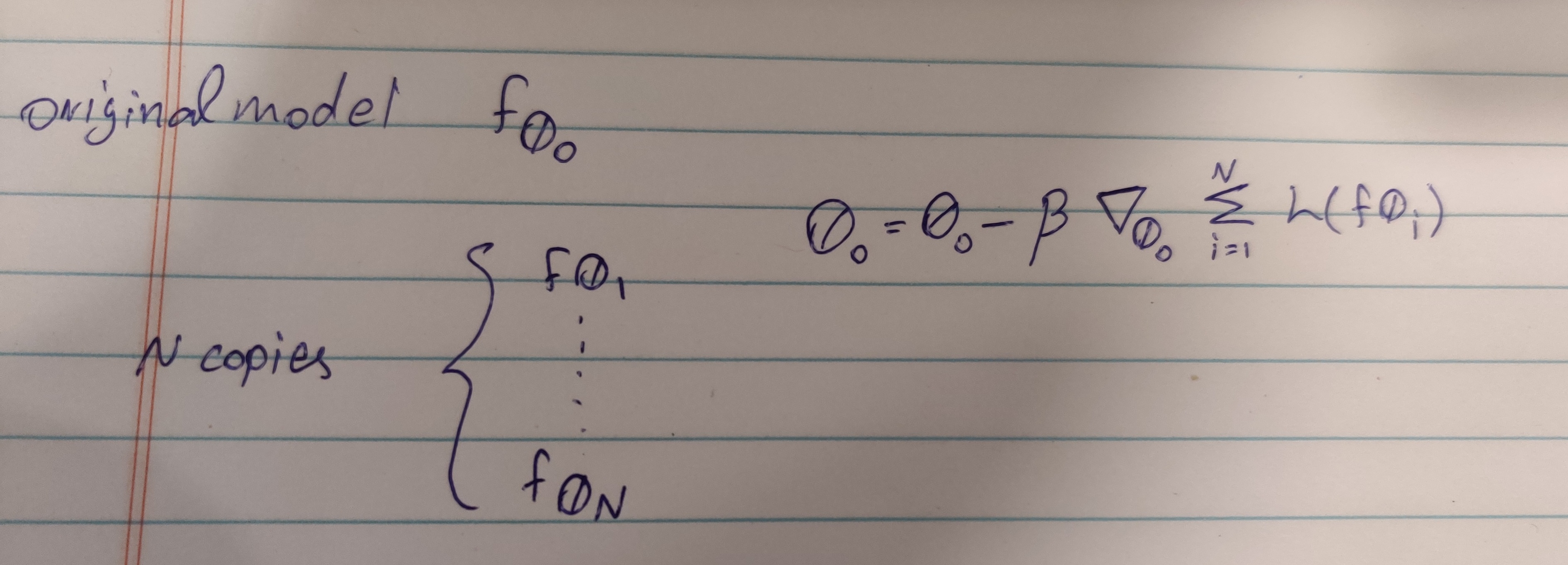I have an original model_0 and N copies of it model_{1,…,N} that are trained on different partitions of the data.
I want to compute losses for model 1 through N, then use their summed losses as the loss for model_0.
What I do now is compute the sum of losses in a variable loss_total
then I make a forward pass through model_0, and manually change the data variable to the wanted loss value
total_losses = #sum of losses from N copies
optimizer_0 = torch.optim.Adam(model_0.parameters(), lr=lr)
model_loss = loss(model_0(x_random), y_random) # make a forward pass through any data
model_loss.data = total_losses # manually change the loss
optimizer_0.zero_grad()
model_loss.backward()
optimizer_0.step()
I am not sure that this is the way to go about it, so I appreciate any expert opinion on the matter.
First of all, you should not use .data anymore.
You can use .detach() or torch.no_grad() to replace it.
What is the behavior you expect for the gradients?
Should they be the sum of the gradients for each models? Or should it be only for the first one with the value of the loss changed (so not the true gradients of that model but something else)?
It should be the gradient of model_0 with the loss value changed.
So it is equivalent of wanting to do gradient updates on the original model using a loss value that I manually enter.
Ok, can you write down mathematically what you want to do here please?
Or write down the values you expect for a very simple example where your model+loss just computes (2 * input).sum()
I want to train N copies of the model on different data. After that, I want to use their summed losses as the loss for the original model (parameter index 0 in the image) and update the original model’s parameters based on that summed loss.
Let me know if that cleared it up. I am implementing the adaption step from the MAML algorithm.
Oh I think I understand the confusion.
Every model that’s i != 0 has been trained on different data and each have a loss > 0.
Then I want the original model to treat that loss as its own, so the gradient of the loss wouldn’t be 0. I want to trick the model into thinking that it acquired the loss value on its own, and then do sgd on it.
model_0 = create_model()
summed_losses = 0
for _ in range(epochs):
models_array = [deepcopy(model) for _ in range N] # get N copies of the main model
for i in range(N):
local_optimizer = optimizer(models_array[i].parameters(), lr)
local_loss = loss(models_array[i](data[i]), labels[i])
#each model is trained on different data
local_optimizer.zero_grad()
local_loss.backward()
local_optimizer.step()
with torch.no_grad():
summed_losses += loss(models_array[i](eval_data[i]), eval_labels[i]) #collect sum of losses for the main model
main_optimizer = optimizer(model_0.parameters(), lr)
main_loss = summed_losses #this is the part that I want to figure out. How do I assign summed_losses as the loss for my main model
main_optimizer.zero_grad()
main_loss.backward() #trick the main model to use the summed loss as its own
main_optimizer.step()
so at every iteration, I initiate N copies of the main model, then they train on different data and update their weights independently. Then I evaluate those N models and get a summation of their losses, and use that loss as the main model’s loss.
Sorry, this does not really make sense to me.
Your models i>0 have different weights than the weights for the one with i=0. So the gradients of the i>0 models wrt w_0 are 0.
Given your torch.no_grad, I guess that you don’t plan on backpropagating through the weight updates.
I apologize for the confusion and I thank you for your patience with me.
The algorithm doesn’t really make sense outside of the few-shot learning framework.
I spent some time looking through the code @vainaijr posted and how the algorithm should work and I think this is what it should do:
Models 1 through N compute losses for tasks 1 through N, then model_0 uses that to get its parameters to a place where the optimal weights for any of those tasks are a few gradient steps away from each of the tasks 1 through N.
Models 1 through N have now accomplished their use, so we don’t need them for this iteration anymore.
In steps format:
make N copies of model_0 (namely model 1 thorough N)
use models 1 through N to train them on different tasks and collect the losses
pretend that the summed loss is the loss for model_0
pass the same data models 1 through N trained on to model_0 and compute the loss on them, but manually change that loss so it’s equal to the summed loss
discard models 1 through N
This happens for an epochs number of times, so the summed losses at each iteration work as an indicator for the main model as to how far it is from that good initialization place in the parameters space where most different tasks are a few gradient steps away.
That way model_0 can update its own weights based on the summed losses from models 1 through N.
My main question, which I think I didn’t ask very well, was how should I update the loss manually while not change the computational graph. Which I did using this way:
#data.x are all the data used to train models 1 through N. They are disjoint by nature.
model_loss = loss(model(data.x), data.y)
with torch.no_grad():
model_loss.set_(torch.Tensor([summed_losses]).to(device)[0])
This is definitely the right way to change the value of the Tensor without changing the graph.
Just to be sure we understand each other. Here is a code sample that shows what this does (most likely nothing).
import torch
# The loss is given by the sum operation.
# The backward of this op does not use the output value
def my_fn(x, modify_res=False):
loss = (2*x).sum(0, keepdim=True)
if modify_res:
with torch.no_grad():
loss[0] = 10
return loss
inp = torch.rand(1, requires_grad=True)
my_fn(inp).backward()
print("base")
print(inp.grad)
inp.grad.zero_()
my_fn(inp, modify_res=True).backward()
print("modified")
print(inp.grad)
Hello,
I met the same problem.
I wanna ask what my_fn and inp and modify_res means here, and why is loss[0] = 10?
If I want to use loss calculated from a network to update another network, what should I do?
Thanks in advance.