I have been extracting the bounding box from masks to give and train segment anything model, I have a 16 uint datatype image,masks are also 16 uint image.
class segmentationdataset(Dataset):
def __init__(self, csv, augmentation =None, transform_image = None, transform_label = None,transform_bbox= None):
self.df=pd.read_csv(csv)
self.ids = self.df["file_ids"]
self.transform_image = transform_image
self.transform_label = transform_label
self.transform_bbox = transform_bbox
self.augmentation = augmentation
def __getitem__(self,idx):
image=np.array(Image.open("/kaggle/input/nucleus-data-c-elegans/nucleus_data/features/F"+self.ids[idx]))
mask=np.array(Image.open("/kaggle/input/nucleus-data-c-elegans/nucleus_data/segmentation_maps/L"+self.ids[idx]))
b_box=np.array(Image.open("/kaggle/input/nucleus-data-c-elegans/nucleus_data/segmentation_maps/L"+self.ids[idx]))
if self.augmentation is not None:
augmented=self.augmentation(image=image,mask=mask,b_box=b_box)
image = augmented["image"]
mask = augmented["mask"]
b_box = augmented["b_box"]
image = self.transform_image(image)
mask = self.transform_label(mask)
b_box = self.transform_bbox(b_box)
b_box = np.array(b_box, dtype=np.uint8) # Convert PIL Image to NumPy array
b_box = torch.as_tensor(b_box)
obj_ids = torch.unique(b_box)
obj_ids = obj_ids[1:]
b_boxes = b_box == obj_ids[:, None, None]
boxes = masks_to_boxes(b_boxes)
return image.float(), mask.float(), boxes.float()
def __len__(self):
return len(self.ids)
this is dataset class
here are data augmentation which , I am doing
full_dataset = segmentationdataset(csv = "file_ids.csv",
augmentation = Compose([
#GridDistortion(p=0.5),
Transpose(p=0.5),
VerticalFlip(p=0.5),
HorizontalFlip(p=0.5),
RandomRotate90(p=0.5),
ShiftScaleRotate(p=0.1),
OpticalDistortion(distort_limit=0.3, shift_limit=0.3, p=1),
]),
transform_image = transforms.Compose([
transforms.ToPILImage(),
ToTensor(),
transforms.RandomApply([AddGaussianNoise( mean = 0.5,std= 0.05)], p=0.5)
]),
transform_label = transforms.Compose([
transforms.ToPILImage(),
ToTensor(),
]),
transform_bbox = transforms.Compose([
transforms.ToPILImage(),
ToTensor()
]))
train_batch_size = 32
train_size = int(0.8* len(full_dataset)) ## 80/20 split
test_size = len(full_dataset) - train_size
train_dataset, test_dataset = random_split(full_dataset, [train_size, test_size])
train_loader = DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(dataset=test_dataset, batch_size= 4, shuffle = True)
print(len(train_loader), "batches ")
print(len(val_loader), " batches ")
for image, mask, bboxes in train_loader:
# img_embed: (B, 256, 64, 64), gt2D: (B, 1, 256, 256), bboxes: (B, 4)
print(f"{image.shape=}, {mask.shape=}, {bboxes.shape=}")
break

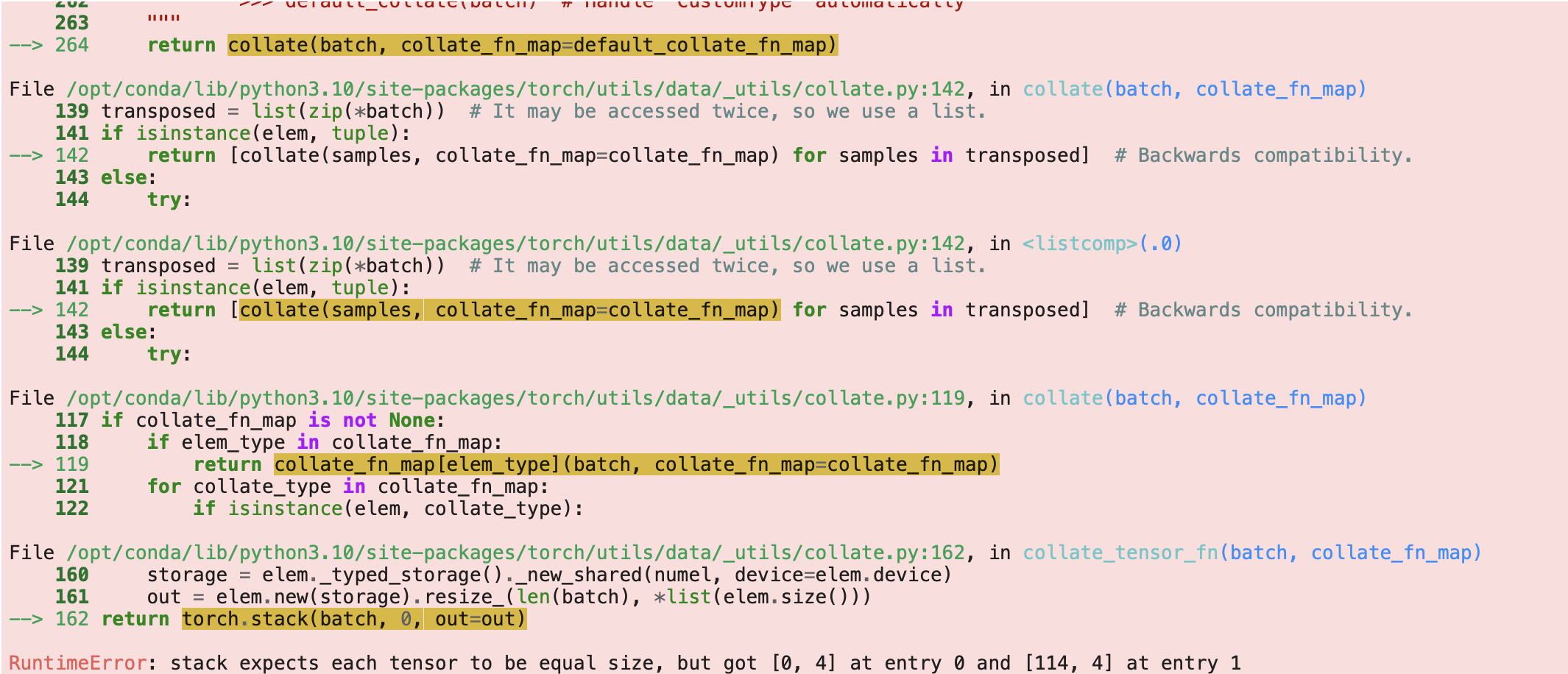
When I tried to extract the shapes of the image, mask, and bounding_box ,I encountered this error. What does the error mean??
This is what my mask looks like!

thanks in advance