hi all
I am new in PyTorch and now I am working on semantic segmentation topics
I have a question and I hope I will find the answer
I have an image (RGB.PNG) and mask (contain indices of 5 classes [0, 1, 2, 3, 4]) but has three-channel (.PNG) so:
How can I deal with the mask as input (batch_size x H x W)? can I take the first channel
ex: mask = mask[:,:,0] or how ?
There are a few different ways to tackle this project
If you have time have a look at how its done here:
thank you for replying
I will check your link
my question is exactly
what is the input and output format for images and masks in semantic segmentation models any example?
Depends on the model you’re using. For example if you implement the original UNET from the paper it clearly defines the dimensions for images and masks
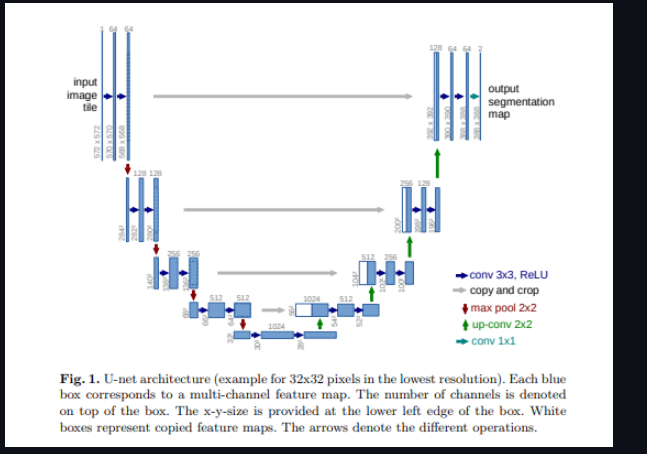
I tried out UNET a while back where i implemented the model from the paper and used it in binary segmentation task. (Have a look at the input and output dimensions)
I haven’t done anything complex in my training and the code is pretty straightforward:
Binary segmentation use case
UNET in pytorch
Hopefully this helps
thank you so much
in the case of multiclass what will be happen?
Only difference i can think of is changing the number of output channels of the model.
Also found a article that might help you
Thank you so much
i appreciate that