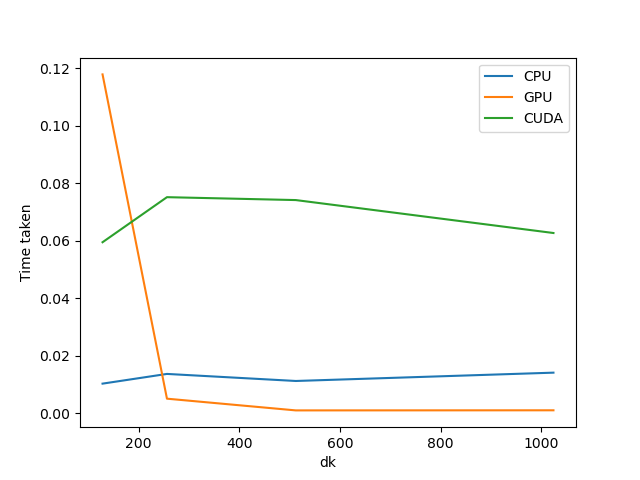
I have been computing the times taken by some python torch scripts to compare them to other implementations for example in plain c or cuda. The implementation in particular is the one for the Attention block where I use the function masked_fill to set the values of the triangular upper submatrix in the attention matrix to -inf. This is I think one of the most typical ways to do it, at least as far as I’ve seen (seen in nanoGPT, that must be why).
The code itself is relatively straight fordward, some matmul and stuff I’m wrapping inside a loop, where I change the size of the inputs, to check the time spent vs those sizes. The first gpu loop takes a while, but the others happen blazing fast.
Here I show some ugly graph I made quickly. I checked each function separately and it is the masked_fill waht causes everything, any insights on this? Is some kind of cache taking care of futures fills?
This might point to a synchronization issue and you should make sure to properly add warmup iterations as well as to synchronize the code before starting and stopping host timers as CUDA operations are executed asynchronously.
I don’t know what this means, but note that masked_fill will synchronize your code:
torch.cuda.set_sync_debug_mode("warn")
x = torch.randn(10, device="cuda")
mask = torch.randint(0, 2, (10,), device="cuda").to(torch.bool)
x.masked_fill_(mask, 1.)
# /torch/_tensor_str.py:137: UserWarning: called a synchronizing CUDA operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:150.)
# nonzero_finite_vals = torch.masked_select(
# /torch/_tensor_str.py:151: UserWarning: called a synchronizing CUDA operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:150.)
# if value != torch.ceil(value):
# /torch/_tensor_str.py:173: UserWarning: called a synchronizing CUDA operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:150.)
# nonzero_finite_max / nonzero_finite_min > 1000.0
# /torch/_tensor_str.py:174: UserWarning: called a synchronizing CUDA operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:150.)
# or nonzero_finite_max > 1.0e8
# /torch/_tensor_str.py:175: UserWarning: called a synchronizing CUDA operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:150.)
# or nonzero_finite_min < 1.0e-4
# /torch/_tensor.py:988: UserWarning: called a synchronizing CUDA operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:150.)
# return self.item().__format__(format_spec)
# /torch/_tensor_str.py:253: UserWarning: called a synchronizing CUDA operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:150.)
# data = [_val_formatter(val) for val in self.tolist()]
If you are using host timers without proper syncs, this operation will accumulate the runtime of previous kernels and your profiling would be invalid.