Hello, currently I’m having the problem of matrix size mismatching for the multiplication. In here I use the x_train with the size of (7304,20) and y_train with the size of (7304,3). I intend to use a AE-Transformer model to pass the input with batch_size through dataloader method equals 128, here is the model:
class Autoencoder(nn.Module):
def __init__(self, input_size, hidden_dim,embed_dim, noise_level):
super(Autoencoder, self).__init__()
self.input_size, self.hidden_dim, self.noise_level = input_size, embed_dim,noise_level
self.embed_dim = embed_dim
self.fc1 = nn.Linear(self.input_size, self.hidden_dim)
self.fc2 = nn.Linear(self.hidden_dim, self.input_size)
def encoder(self,x):
x = self.fc1(x)
h1 = F.relu(x)
return h1
def mask(self,x):
corrupted_x = x + self.noise_level + torch.randn_like(x) # randn_like Initializes a tensor where all the elements are sampled from a normal distribution.
return corrupted_x
def decoder(self, x):
h2 = self.fc2(x)
return h2
def forward (self, x):
out = self.mask(x) # Adding noise to feed the network
encoder = self.encoder(out)
decoder = self.decoder(encoder)
return encoder, decoder
## Transformer
### Positional encoding
class PositionalEncoding(nn.Module):
def __init__(self,d_model, dropout=0.0,max_len=16):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len,d_model)
position = torch.arange(0,max_len, dtype = torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0,d_model,2).float()*(-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(1), :].squeeze(1)
return x
class Net(nn.Module):
def __init__(self,feature_size,num_layers,n_head,dropout,noise_level,embed_dim):
super(Net,self).__init__()
self.embed_dim = embed_dim
self.hidden_dim = 4*embed_dim
self.auto_hidden = int(feature_size / 2)
input_size = self.auto_hidden
self.pos = PositionalEncoding(d_model=input_size, max_len=input_size)
encoder_layers = nn.TransformerEncoderLayer(d_model=input_size, nhead=n_head, dim_feedforward=self.hidden_dim, dropout=dropout)
self.cell = nn.TransformerEncoder(encoder_layers,num_layers=num_layers)
self.linear = nn.Linear(input_size,1)
self.autoencoder = Autoencoder(input_size = feature_size, hidden_dim = self.auto_hidden,embed_dim = embed_dim, noise_level=noise_level)
def forward(self,x):
batch_size,feature_num, feature_size = x.shape
encode, decode = self.autoencoder(x.view(batch_size,-1).float()) # Equals batch_size * seq_len
out = encode.reshape(batch_size,-1,self.auto_hidden)
out = self.pos(out)
out = out.reshape(1,batch_size,-1) #(1,batch_size,feature_size)
out = self.cell(out)
out = out.reshape(batch_size,-1)
out = self.linear(out)
return out, decode
class Autoencoder(nn.Module):
def __init__(self, input_size, hidden_dim,embed_dim, noise_level):
super(Autoencoder, self).__init__()
self.input_size, self.hidden_dim, self.noise_level = input_size, embed_dim,noise_level
self.embed_dim = embed_dim
self.fc1 = nn.Linear(self.input_size, self.hidden_dim)
self.fc2 = nn.Linear(self.hidden_dim, self.input_size)
def encoder(self,x):
x = self.fc1(x)
h1 = F.relu(x)
return h1
def mask(self,x):
corrupted_x = x + self.noise_level + torch.randn_like(x) # randn_like Initializes a tensor where all the elements are sampled from a normal distribution.
return corrupted_x
def decoder(self, x):
h2 = self.fc2(x)
return h2
def forward (self, x):
out = self.mask(x) # Adding noise to feed the network
encoder = self.encoder(out)
decoder = self.decoder(encoder)
return encoder, decoder
## Transformer
### Positional encoding
class PositionalEncoding(nn.Module):
def __init__(self,d_model, dropout=0.0,max_len=16):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len,d_model)
position = torch.arange(0,max_len, dtype = torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0,d_model,2).float()*(-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(1), :].squeeze(1)
return x
class Net(nn.Module):
def __init__(self,feature_size,num_layers,n_head,dropout,noise_level,embed_dim):
super(Net,self).__init__()
self.embed_dim = embed_dim
self.hidden_dim = 4*embed_dim
self.auto_hidden = int(feature_size / 2)
input_size = self.auto_hidden
self.pos = PositionalEncoding(d_model=input_size, max_len=input_size)
encoder_layers = nn.TransformerEncoderLayer(d_model=input_size, nhead=n_head, dim_feedforward=self.hidden_dim, dropout=dropout)
self.cell = nn.TransformerEncoder(encoder_layers,num_layers=num_layers)
self.linear = nn.Linear(input_size,1)
self.autoencoder = Autoencoder(input_size = feature_size, hidden_dim = self.auto_hidden,embed_dim = embed_dim, noise_level=noise_level)
def forward(self,x):
batch_size,feature_num, feature_size = x.shape
encode, decode = self.autoencoder(x.view(batch_size,-1).float()) # Equals batch_size * seq_len
out = encode.reshape(batch_size,-1,self.auto_hidden)
out = self.pos(out)
out = out.reshape(1,batch_size,-1) #(1,batch_size,feature_size)
out = self.cell(out)
out = out.reshape(batch_size,-1)
out = self.linear(out)
return out, decode
Here is some information of the model after passing the data:
Net(
(pos): PositionalEncoding()
(cell): TransformerEncoder(
(layers): ModuleList(
(0-2): 3 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=3652, out_features=3652, bias=True)
)
(linear1): Linear(in_features=3652, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=64, out_features=3652, bias=True)
(norm1): LayerNorm((3652,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((3652,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
(linear): Linear(in_features=3652, out_features=1, bias=True)
(autoencoder): Autoencoder(
(fc1): Linear(in_features=7304, out_features=16, bias=True)
(fc2): Linear(in_features=16, out_features=7304, bias=True)
)
And I got the error:
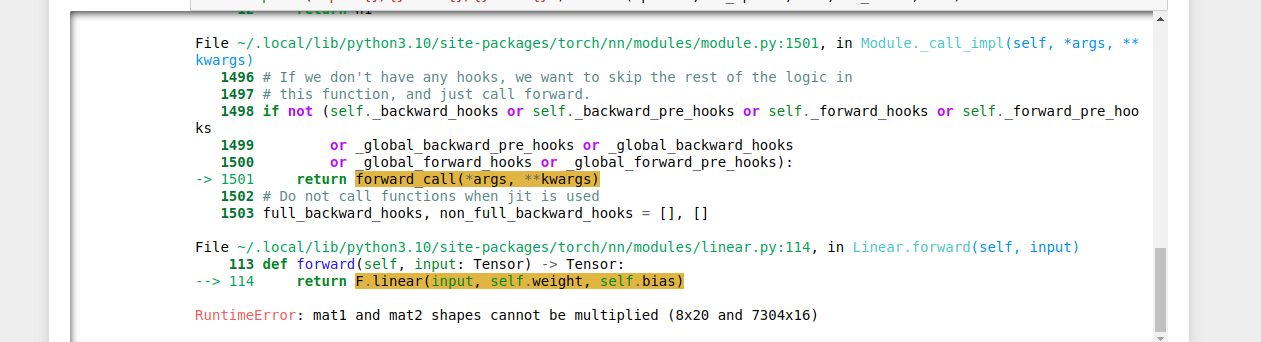
How can I modify the model so that I can address with the matter of data size when passing through the model ?