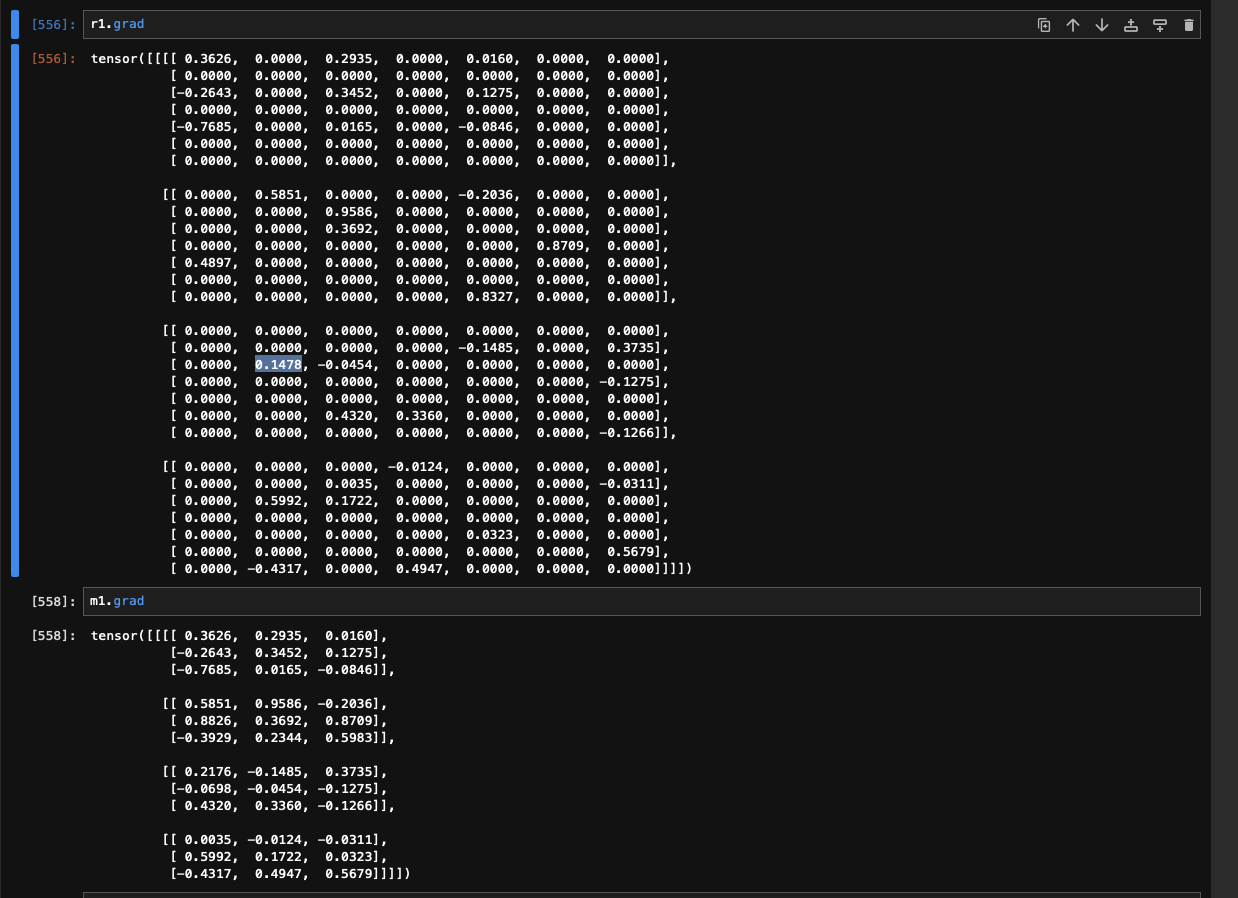
Hi there! I guess there might be a bug in MaxPool2d backward pass.
I have m1 = F.max_pool2d(r1, kernel_size=3, stride=2).
I expect r1.grad to be filled with values from m1.grad, but there is one value that is taken from nowhere (highlighted on screenshot)
This is expected since you are using overlapping windows which will accumulate the gradient into duplicated values.
E.g. take a look at this random example using your shapes:
import torch
import torch.nn.functional as F
r1 = torch.randn(1, 3, 7, 7, requires_grad=True)
print(r1)
# tensor([[[[-1.4727, 0.9768, -0.3311, 0.8737, 0.0744, -2.0515, 0.7500],
# [ 1.3699, 1.1092, 0.1827, 0.6149, -1.2941, -0.8750, -0.8603],
# [-0.0599, -0.6267, 0.7734, -0.3923, -0.9799, 0.6560, -0.9698],
# [-1.7298, -2.7498, 0.0206, 2.0452, 0.3059, -1.3612, -0.2122],
# [ 0.6241, 3.4831, -0.0442, 1.9328, -0.3648, 2.7771, -0.1683],
# [ 0.0857, -0.2046, 2.1729, -1.7988, -2.1140, -0.4294, 1.2538],
# [-0.4254, -2.8631, 0.6067, 1.1106, -1.0001, -0.3954, 0.6482]],
# [[-0.3228, 1.4671, -0.1583, -0.0143, 0.6897, -0.1155, -1.1501],
# [-0.9122, 0.7400, 1.4444, 1.5633, 0.8384, 0.2486, -1.1106],
# [ 2.1963, -0.6138, -1.1844, 1.2009, 0.7253, -0.4287, 0.6641],
# [-1.6240, 1.1937, -0.5235, 2.1328, 0.8682, -1.3029, 0.6951],
# [-0.9053, -0.2419, -0.3201, -0.9616, 0.8365, -1.9191, 0.9880],
# [ 1.7853, 1.4329, -0.2436, -0.9494, -0.5477, -0.0317, 1.4060],
# [ 0.2019, 1.8628, -0.6363, 0.6255, 0.0776, -0.2312, 0.3852]],
# [[ 0.5682, -1.0610, -0.3535, -0.4028, -3.1006, 0.8192, 0.8052],
# [-0.2114, -1.0538, 1.0613, -0.2747, 0.2004, 0.2594, 1.9385],
# [ 0.3455, 0.9690, -1.2378, 0.6012, -0.1848, 1.8598, -0.8459],
# [ 0.2934, -0.1465, 0.0372, -0.4022, -0.1241, -1.5513, 0.5390],
# [ 0.0278, -0.9802, 0.9465, 1.6141, -1.7087, -1.1682, -0.5648],
# [ 1.5077, 0.6494, -0.3490, -0.1972, 0.3168, -1.1350, -0.1763],
# [-2.6766, 0.8964, 0.5659, -0.2317, 0.5457, 0.6722, 1.3882]]]],
# requires_grad=True)
m1 = F.max_pool2d(r1, kernel_size=3, stride=2)
print(m1)
# tensor([[[[1.3699, 0.8737, 0.7500],
# [3.4831, 2.0452, 2.7771],
# [3.4831, 2.1729, 2.7771]],
# [[2.1963, 1.5633, 0.8384],
# [2.1963, 2.1328, 0.9880],
# [1.8628, 0.8365, 1.4060]],
# [[1.0613, 1.0613, 1.9385],
# [0.9690, 1.6141, 1.8598],
# [1.5077, 1.6141, 1.3882]]]], grad_fn=<MaxPool2DWithIndicesBackward0>)
m1.retain_grad()
m1.mean().backward()
print(m1.grad)
# tensor([[[[0.0370, 0.0370, 0.0370],
# [0.0370, 0.0370, 0.0370],
# [0.0370, 0.0370, 0.0370]],
# [[0.0370, 0.0370, 0.0370],
# [0.0370, 0.0370, 0.0370],
# [0.0370, 0.0370, 0.0370]],
# [[0.0370, 0.0370, 0.0370],
# [0.0370, 0.0370, 0.0370],
# [0.0370, 0.0370, 0.0370]]]])
print(r1.grad)
# tensor([[[[0.0000, 0.0000, 0.0000, 0.0370, 0.0000, 0.0000, 0.0370],
# [0.0370, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0370, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0741, 0.0000, 0.0000, 0.0000, 0.0741, 0.0000],
# [0.0000, 0.0000, 0.0370, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
# [[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0370, 0.0370, 0.0000, 0.0000],
# [0.0741, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0370, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0370, 0.0000, 0.0370],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0370],
# [0.0000, 0.0370, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
# [[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0741, 0.0000, 0.0000, 0.0000, 0.0370],
# [0.0000, 0.0370, 0.0000, 0.0000, 0.0000, 0.0370, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0741, 0.0000, 0.0000, 0.0000],
# [0.0370, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0370]]]])
Now look for duplicates in the output m1 and you will find e.g. 3.4831 in the first channel which is picked as the max value in two windows. This value can be found in r1[0, 0, 4, 1] and you will see that r1.grad[0, 0, 4, 1] was accumulated (i.e. doubled in this example).
Got it! Thank you very much for your help