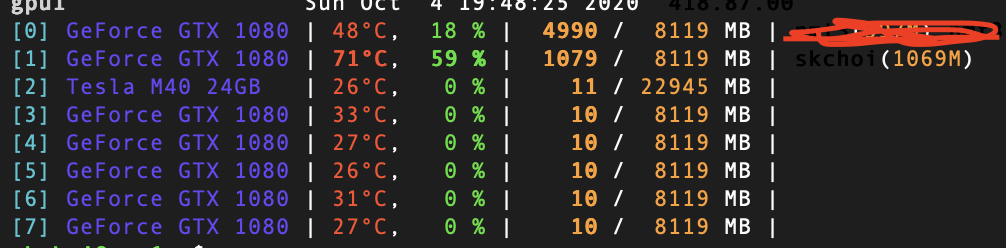
I am having a trouble with increasing memory issue.
From the first data read, the memory starts to grow continuously.
And if I keep watching through htop, the memory continues to increase every time I do training and validating.
Eventually, a dataloader killed error occurs, and the training cannot be completed until the end.
Also, it didn’t use gpu 100%… it only uses 50%~60%…
I changed the loss variable and used all of the cudas, but I don’t know what is the cause.
My training code is here.
def train(self):
train_gen = data.DataLoader(
dataset=self._train_data, shuffle=True,
batch_size=ARGS.train_batch,
num_workers=ARGS.num_workers, pin_memory=True)
val_gen = data.DataLoader(
dataset=self._val_data, shuffle=False,
batch_size=ARGS.test_batch, num_workers=ARGS.num_workers,
pin_memory=True)
# will train self._num_epochs copies of train data
to_train = chain.from_iterable(repeat(train_gen, self._num_epochs))
# consisting of total_steps batches
total_steps = len(train_gen) * self._num_epochs
print("total steps: ", total_steps)
num_steps = 0
self._train(to_train, len(train_gen), num_steps, val_gen)
cur_weight = self._model.state_dict()
torch.save(cur_weight, '{}{}.pt'.format(self._weight_path, self.step))
print('Current best weight: {}.pt, best auc: {}'.format(self.max_step, self.max_auc))
def _forward(self, batch):
#print('device: ', self._device)
batch = {k: t.to(self._device, non_blocking=True) for k, t in batch.items()}
#label = Variable(batch['label']).to(self._device) # shape: (batch_size, 1)
#inputs = Variable(batch['input']).to(self._device)
label = batch['label']
output = self._model(batch['input'], batch['target_id'])
pred = (torch.sigmoid(output) >= self._threshold).long() # shape: (batch_size, 1)
loss = self._loss_fn(output, label.float())
return label, output, pred, loss.mean()
def _get_loss(self, label, output):
loss = self._loss_fn(output, label.float())
return loss.mean()
def _train(self, batch_iter, num_iter, num_batches, val_gen):
start_time = time.time()
self._model.train()
losses = 0
num_corrects = 0
num_total = 0
labels = []
outs = []
data_time = AverageMeter()
batch_time = AverageMeter()
#losses = AverageMeter()
end = time.time()
for i, batch in enumerate(batch_iter):
i += 1
data_time.update(time.time() - end)
label, out, pred, train_loss = self._forward(batch)
#train_loss = self._get_loss(label, out)
losses += train_loss.item()
#compute gradient and do Noam step
self._opt.step(train_loss)
#measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
num_corrects += (pred == label).sum().item()
num_total += len(label)
if i%1000 == 0:
labels.extend(label.squeeze(-1).data.cpu().numpy())
outs.extend(out.squeeze(-1).data.cpu().numpy())
acc = num_corrects / num_total
auc = roc_auc_score(labels, outs)
losses = losses / 1000
training_time = time.time() - start_time
print('correct: {}, total: {}'.format(num_corrects, num_total))
#print('[Train] time: {}, loss: {}, acc: {}, auc: {}'.format(training_time, loss, acc, auc))
print('[Train] [{0}/{1}]\t'
'time {batch_time.avg:.3f}\t'
'data time {data_time.avg:.3f}\t'
'loss {loss:.4f}\t'
'acc {acc:.4f}\t'
'auc {auc:.4f}\t'
'training time {training_time:.4f}\t'.format(
i, num_iter, acc=acc, auc=auc, batch_time=batch_time, data_time=data_time, loss=losses, training_time=training_time
))
losses = 0
if i % 10000 == 0:
self._test('Validation', val_gen, i)
print('Current best weight: {}.pt, best auc: {}'.format(self.max_step, self.max_auc))
cur_weight = self._model.state_dict()
torch.save(cur_weight, '{}{}.pt'.format(self._weight_path, i))
mylist = []
mylist.append(self.max_auc)
mylist.append(self.max_acc)
mylist.append(i)
with open('output.csv', 'a', newline='') as file:
writer = csv.writer(file)
writer.writerow(mylist)
print('--------------------------------------------------------')