This is htop image. The Mem was increased until it is full.

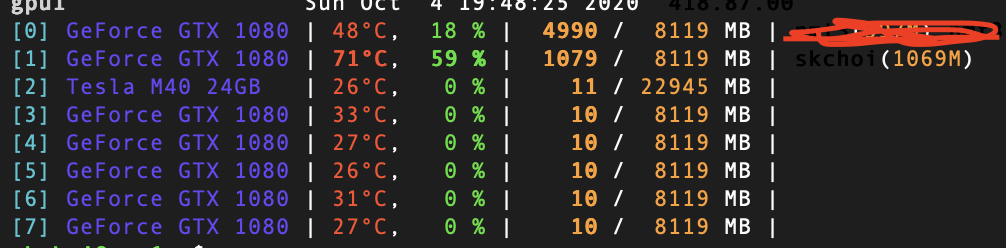
This is my GPU usage image. I’m using only 1 GPU because I tried increasing the number of gpu but the performance didn’t improve and memory was increasing too.
The label and out’s tensor size is (64,1).
And the batch size is 64, num_workers is 32.
However, even though I delete the labels/outs and run training, the memory continues to increase.
Also, I checked the consumed memory with some code. please check this.
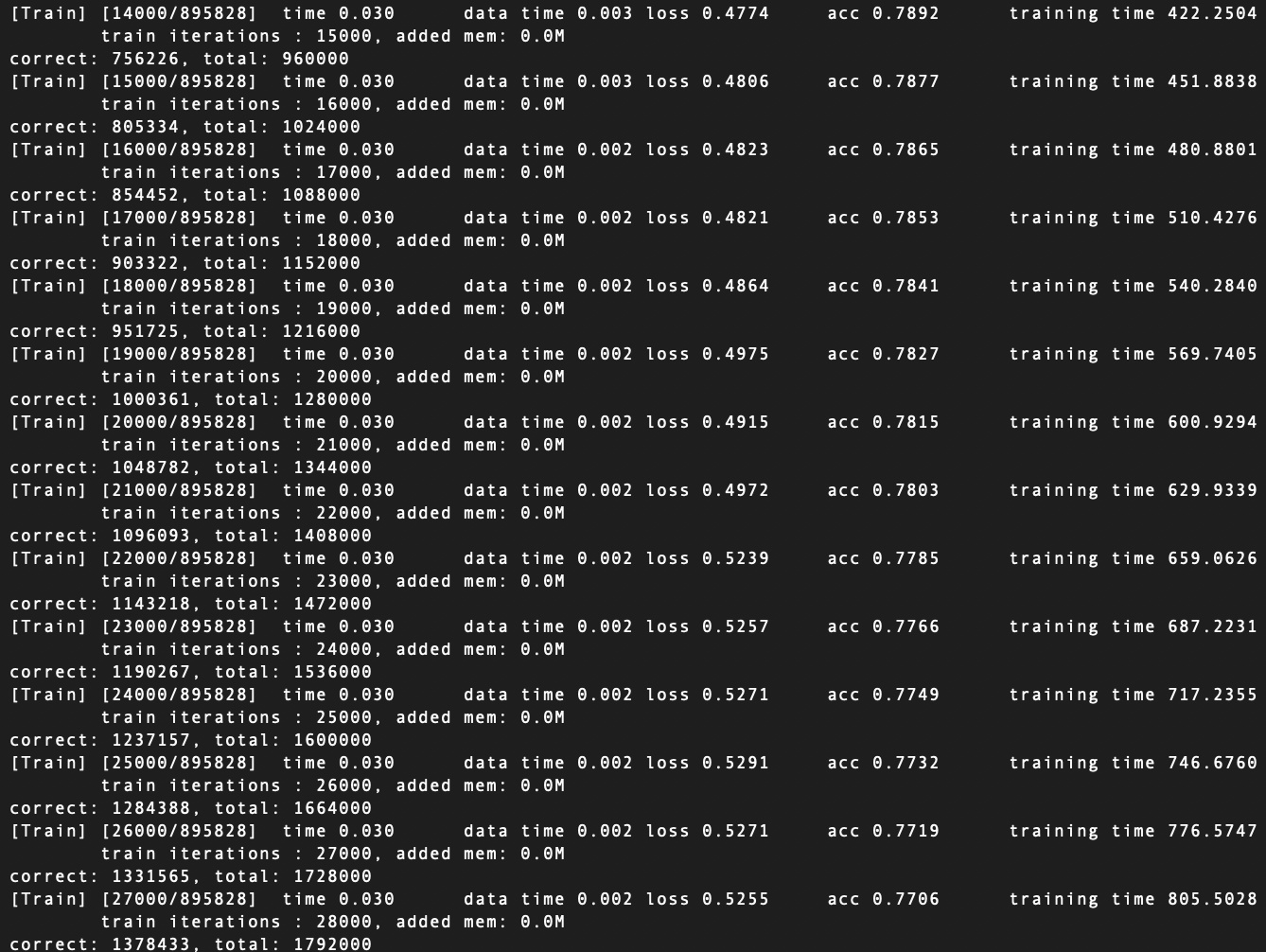
def _train(self, batch_iter, num_iter, num_batches, val_gen):
start_time = time.time()
self._model.train()
losses = 0
num_corrects = 0
num_total = 0
#labels = []
#outs = []
data_time = AverageMeter()
batch_time = AverageMeter()
pid = os.getpid()
prev_mem = 0
end = time.time()
for i, batch in enumerate(batch_iter):
i += 1
data_time.update(time.time() - end)
label, out, pred, train_loss = self._forward(batch)
if i==1:
print(label.size(), ' ', out.size())
#train_loss = self._get_loss(label, out)
losses += train_loss.item()
#compute gradient and do Noam step
self._opt.step(train_loss)
#measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
num_corrects += (pred == label).sum().item()
num_total += len(label)
if i%1000 == 0:
cur_mem = (int(open('/proc/%s/statm'%pid, 'r').read().split()[1])+0.0)/256
add_mem = cur_mem - prev_mem
prev_mem = cur_mem
print(" train iterations : {}, added mem: {}M".format(i, add_mem))
#labels.extend(label.squeeze(-1).data.cpu().numpy())
#outs.extend(out.squeeze(-1).data.cpu().numpy())
acc = num_corrects / num_total
#auc = roc_auc_score(labels, outs)
losses = losses / 1000
training_time = time.time() - start_time
print('correct: {}, total: {}'.format(num_corrects, num_total))
#print('[Train] time: {}, loss: {}, acc: {}, auc: {}'.format(training_time, loss, acc, auc))
print('[Train] [{0}/{1}]\t'
'time {batch_time.avg:.3f}\t'
'data time {data_time.avg:.3f}\t'
'loss {loss:.4f}\t'
'acc {acc:.4f}\t'
'training time {training_time:.4f}\t'.format(
i, num_iter, acc=acc, batch_time=batch_time, data_time=data_time, loss=losses, training_time=training_time
))
losses = 0
if i % 100000 == 0:
self._test('Validation', val_gen, i)
print('Current best weight: {}.pt, best acc: {}'.format(self.max_step, self.max_acc))
cur_weight = self._model.state_dict()
torch.save(cur_weight, '{}{}.pt'.format(self._weight_path, i))
mylist = []
#mylist.append(self.max_auc)
mylist.append(self.max_acc)
mylist.append(i)
with open('output.csv', 'a', newline='') as file:
writer = csv.writer(file)
writer.writerow(mylist)
print('--------------------------------------------------------')