I’m building a model which puts Embedding table in CPU while computes activations in GPU. So I move the embedding vectors to GPU in the forward pass, and as far as I know, the autograd engine would put the gradients w.r.t embedding vectors back to CPU. The transferred activations and gradients should be of the same size.
When I profiled the training process, I found that the Memcpy HtoD, which corresponds to moving activations to GPU in the forward pass, was much more faster than Memcpy DtoH (copying gradients back to CPU) in the backward pass.
Here this is the screenshot of the tensorboard profile:
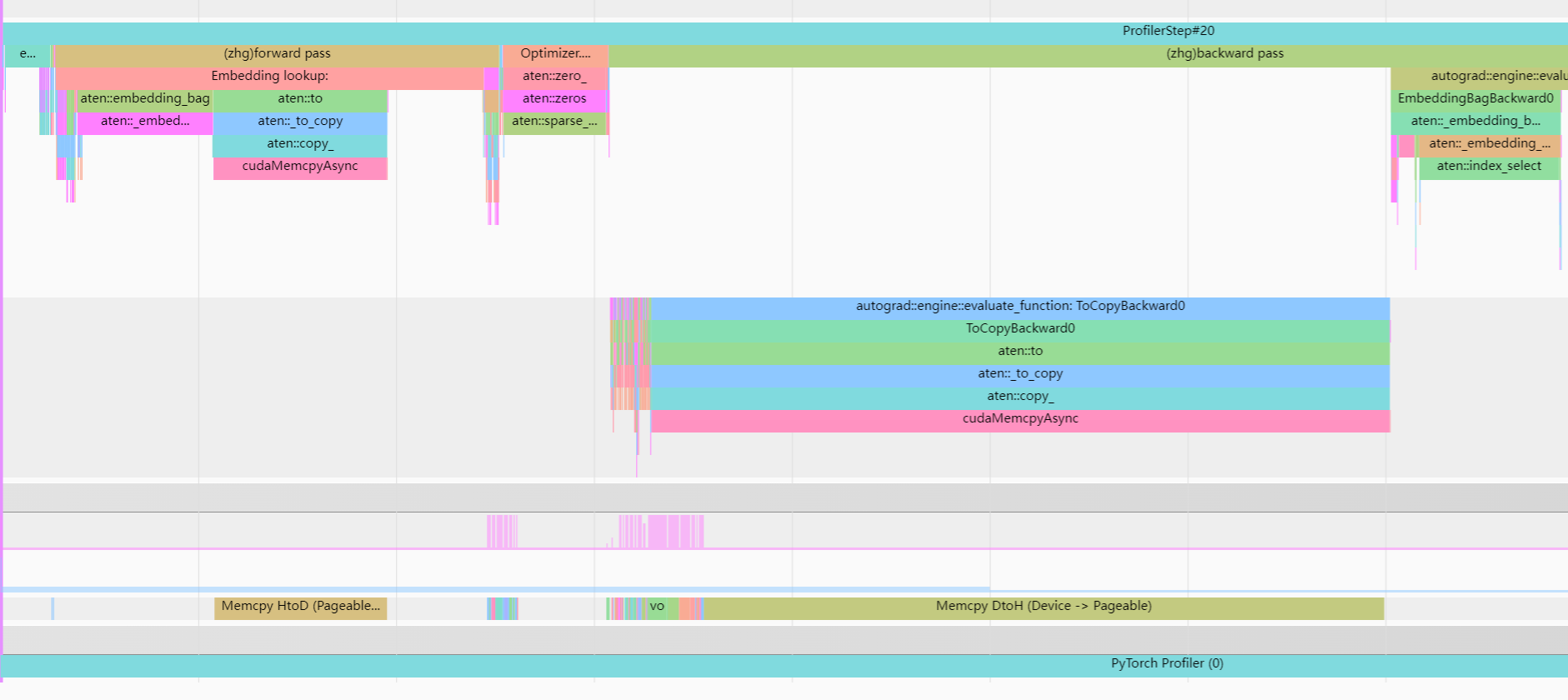
Does anyone have any idea why Memcpy DtoH was slower than HtoD? How can I avoid this problem and improve the speed of DtoH in the backward pass?