Did you check the suggestions from the error message? It seems you are trying to initialize multiple CUDA contexts which fails.
I am not explicitly using any command for CUDA initialization. I can share the code if that helps.
@ptrblck .. adding the code to create the data and run the model. Please do let me know if I am doing anything wrong in CUDA initialization while working with multiple GPUs(4).
import pandas as pd
import numpy as np
from darts.dataprocessing import Pipeline
from darts.metrics import mape, smape, rmse
from darts.utils.statistics import check_seasonality, plot_acf, plot_residuals_analysis
from darts.utils.timeseries_generation import linear_timeseries
from darts.datasets import MonthlyMilkDataset, MonthlyMilkIncompleteDataset
from darts.models import NBEATSModel
#from statsmodels.tools.eval_measures import rmse
from sklearn.preprocessing import MaxAbsScaler
new_arry = np.array(np.random.randint(1000,size=(365,10000)))
new_data = pd.DataFrame(new_arry)
new_data.columns = [‘col_’ + str(i) for i in new_data.columns]
new_data[‘col_dt’] = pd.date_range(start=‘1/1/2022’, periods=len(new_data), freq=‘D’)
pvt_samp2 = TimeSeries.from_dataframe(new_data,‘col_dt’,new_data.columns[:10000].tolist())
filler = MissingValuesFiller(fill = ‘auto’)
pvt_samp2 = filler.transform(pvt_samp2)
transformer = Scaler(scaler=MaxAbsScaler())
pvt_samp2 = transformer.fit_transform(pvt_samp2)
new_cov = new_data.copy()
new_cov[‘day’] = new_cov.col_dt.dt.day
new_cov[‘month’] = new_cov.col_dt.dt.month
new_cov = new_cov[[‘col_dt’,‘day’,‘month’]]
new_cov = TimeSeries.from_dataframe(new_cov,‘col_dt’,new_cov.columns[1:].tolist())
scaler_dt_cov = Scaler()
final_cov = scaler_dt_cov.fit_transform(new_cov)
train, val = pvt_samp2.split_after(pd.Timestamp(“20221221”))
train_cov, val_cov = final_cov.split_after(pd.Timestamp(“20221221”))
from darts.models import TFTModel
import torch
my_model = TFTModel(
input_chunk_length=90,
output_chunk_length=10,
hidden_size=32,
lstm_layers=1,
num_attention_heads=3,
dropout=0.2,
batch_size=500,
n_epochs=4,
add_relative_index=False,
add_encoders=None,
likelihood=None,
#likelihood=QuantileRegression(
quantiles=quantiles
#), # QuantileRegression is set per default
loss_fn=torch.nn.MSELoss(),
random_state=42,
)
my_model.fit(train, future_covariates=final_cov, verbose=True)
I don’t see any obvious issues, but am also not familiar enough with lightning to know what’s exactly happening inside the higher-level API. Do you see the same issue if a pure PyTorch model is used?
Yes sir, Other pytorch models are working fine. I have multiple time uninstall and installed it for different versions its not working. Can I download cuda 11 torch from website, will it work with cuda 12?
Your locally installed CUDA toolkit won’t be used unless you build PyTorch from source or a custom CUDA extension. The PyTorch binaries ship with their own CUDA dependencies and you would need to install a proper NVIDIA driver only to execute PyTorch workloads. The NVIDIA driver shipping with CUDA 12.x will work using the PyTorch binaries using CUDA 11.x.
Hello @ptrblck_de, I am facing the same issue.
I am trying to replicate the results from MotionBERT a 3D human pose estimation.
I am running the code in an high performace computer (HPC), where I have multiple nodes with high RAM avaliable.
My sh configuration is:
#!/bin/sh
#BSUB -q gpua100
#BSUB -J motionBERT
#BSUB -W 23:00
#BSUB -B
#BSUB -N
#BSUB -gpu "num=1:mode=exclusive_process"
#BSUB -n 4
#BSUB -R "span[hosts=1]"
#BSUB -R "rusage[mem=4GB]"
#BSUB -o logs/%J.out
#BSUB -e logs/%J.err
module load cuda/11.6
module load gcc/10.3.0-binutils-2.36.1
source /zhome/c0/a/164613/miniconda3/etc/profile.d/conda.sh
conda activate /work3/s212784/conda/env/motionbert
python train.py --config configs/pose3d/MB_train_h36m.yaml --checkpoint checkpoint/pose3d/MB_train_h36m
Which gives me the following resources:
CPU time : 29.94 sec.
Max Memory : 80 MB
Average Memory : 80.00 MB
Total Requested Memory : 16384.00 MB
Delta Memory : 16304.00 MB
Max Swap : 16 MB
Max Processes : 4
Max Threads : 5
Run time : 152 sec.
Turnaround time : 119 sec.
The output error that I am facing is the following:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 260.00 MiB (GPU 0; 79.15 GiB total capacity; 75.23 GiB already allocated; 159.25 MiB free; 77.77 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
I have tried to change the max_split_size_mb with the following line in the jobscript.sh (before python run… ) :
export PYTORCH_CUDA_ALLOC_CONF=“max_split_size_mb=512”
Although I am reaching the same problem, I can see that the memory usage, average and mean are increasing:
Resource usage summary:
CPU time : 30.63 sec.
Max Memory : 2057 MB
Average Memory : 1391.67 MB
Total Requested Memory : 16384.00 MB
Delta Memory : 14327.00 MB
Max Swap : 16 MB
Max Processes : 4
Max Threads : 8
Run time : 145 sec.
Turnaround time : 122 sec.
Nevertheless, when increasing the value too much it drops again…
export PYTORCH_CUDA_ALLOC_CONF=“max_split_size_mb=1024”
Resource usage summary:
CPU time : 30.63 sec.
Max Memory : 2057 MB
Average Memory : 1391.67 MB
Total Requested Memory : 16384.00 MB
Delta Memory : 14327.00 MB
Max Swap : 16 MB
Max Processes : 4
Max Threads : 8
Run time : 145 sec.
Turnaround time : 122 sec.
Therefore, I am not sure if this might be the problem…
Aditionally, (I don’t know if relevant) before changing the max_split_size_mb, I thought that it was a problem from resources in the HPC so tried to run it multiple times. One thing that I notieced it’s that the allocated memory was not always the same:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 518.00 MiB (GPU 0; 15.77 GiB total capacity; 13.82 GiB already allocated; 275.06 MiB free; 14.30 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
I am in the right path? Is the fragmentation causing the problem? Is there a way to know the exact number it should be there?
Thank you very much,
Best Regards,
Alex Abades
Does this mean the memory usage is increasing in each iteration?
If so, you might need to check if you are storing tensors, e.g. in a list, which are still attached to a computation graph. In this case you might want to .detach() them before storing.
I don’t think so as the reserved memory is close to the allocated one and it seems your workload just requires too much memory. Did you try to reduce the workload e.g. by reducing the batch size?
Hello @ptrblck
Thaks for your fast reply, I really appreciate it.
After looking with fresh eyes the code, and knowing that the fragmentation shouldn’t be the problem, I tried to decrease the network and monitor the use of the GPU. Effectively, the problem was indeed the memory usage. I am dealing with 3d poses and I am using attention mechanisms. The problem is that due to the network specifications, the amount of memory usage at some point was higher than the need it.
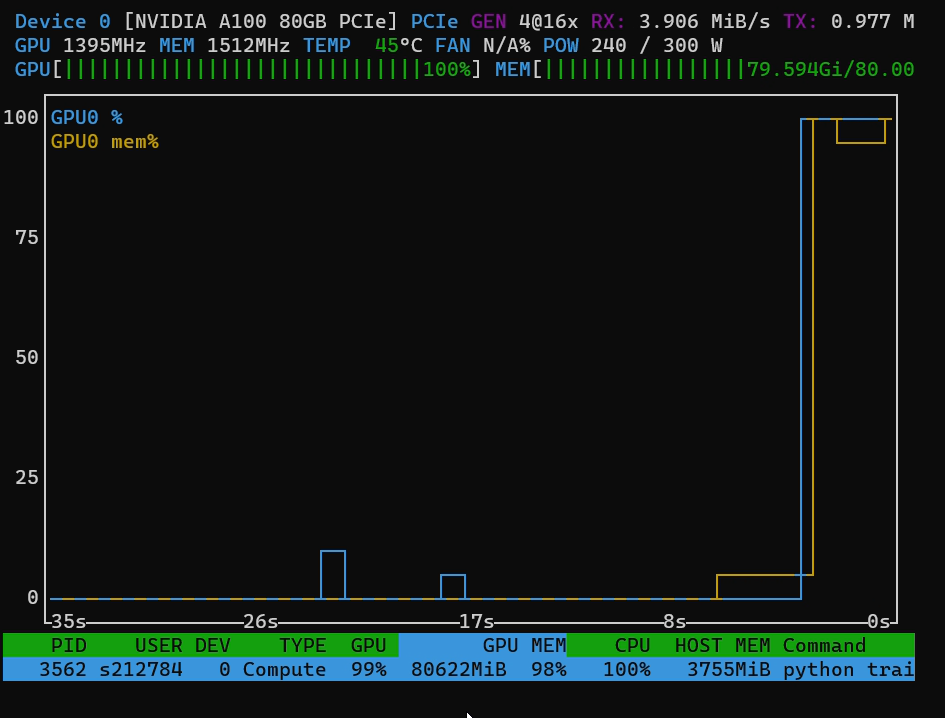
I have to check how can I see the amount of memory need it to train the model with the standard configuration and see how much memory I should need to do so.
Thanks again,
Best,
Alex,
this solution right here worked for me, thanks!
I’m having the same memory issues while trying to train the fcn_resnet50 model in a segmentation vision application within AWS. I get the error message: “CUDA out of memory. Tried to allocate 860.00 MiB (GPU 0; 21.99 GiB total capacity; 21.35 GiB already allocated”. Im training on AWS and grabbed a 24gb GPU but still get memory errors when I try to load the images and masks. It seems no matter what size GPU I use, the model takes up the full GPU. Can PYTORCH_CUDA_ALLOC_CONF or anything else help me train this model? I have added a snippet of my training code below where it is failing. Also, my batch size set to 5 images currently.
from torchvision.models.segmentation import fcn_resnet50, FCN_ResNet50_Weights
model = fcn_resnet50(weights=FCN_ResNet50_Weights.DEFAULT)
model.classifier[4] = torch.nn.Conv2d(512, 2, kernel_size=(1,1), stride=(1,1))
if model.aux_classifier is not None:
model.aux_classifier[4] = torch.nn.Conv2d(256, 2, kernel_size=(1,1), stride=(1,1))
# set up training parameters
epochs = args.epochs
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = model.to(device)
for i in range(epochs):
for batch_idx, (images, masks) in enumerate(trainloader):
images = images.to(device)
masks = masks.to(device)
outputs = model(images)["out"]
I doubt that’s the case. Which GPUs did you use and what was the max. available GPU memory?

That’s the same device you’ve used before, which seems to be too small.
I’m thus unsure how to understand the previous quote as you were indicating different (and potentially larger GPUs) are always running OOM. If that’s not the case, either reduce the memory requirement for your training by e.g. lowering the batch size, use mixed-precision training, or activation checkpointing, or use a larger GPU.
Is there a way to indicate the required memory to load different models? I believe anything bigger than 24gp of GPU memory just starts adding multiple GPUS
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacty of 23.99 GiB of which 18.87 GiB is free. Of the allocated memory 2.97 GiB is allocated by PyTorch, and 41.78 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF