Can I do anything about this, while training a model I am getting this cuda error:
RuntimeError: CUDA out of memory. Tried to allocate 30.00 MiB (GPU 0; 2.00 GiB total capacity; 1.72 GiB already allocated; 0 bytes free; 1.74 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Reduced batch_size from 32 to 8, Can I do anything else with my 2GB card
Hi there im new here and i hope im doing this right. I am getting that error in google colabs and it suggests “See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF”
im not sure what the solution could be despite trying a number of things. im using the stability ai diffusion colab and have a pro account w google. im using a single batch file and the default image size 512x there is no reason i can think of for this error… other than maybe a cache that needs to be cleared since ive been using the colab for most of the morning and changed my workflow several times
Does it mean the script was working before and is crashing without any changes?
The general error is of course raised because you are running out of memory on the GPU. Setting the allocator config to another value could help if a lot of fragmentation is happening, but I also don’t know which values would then be recommended (I wasn’t lucky to actually fix a valid OOM using it).
I have also met this problem. The taining process chould work sucessfully a few days ago. But after I saved the checkpoints( I don’t know if it’s the real reason), the memory of GPU will rise to almost full state immediately every time I want to restar the training. It may be sloved by cleaning the memory or device of this model or create another file as same as before. However, so far I didn’t find the best way to solve this problem.
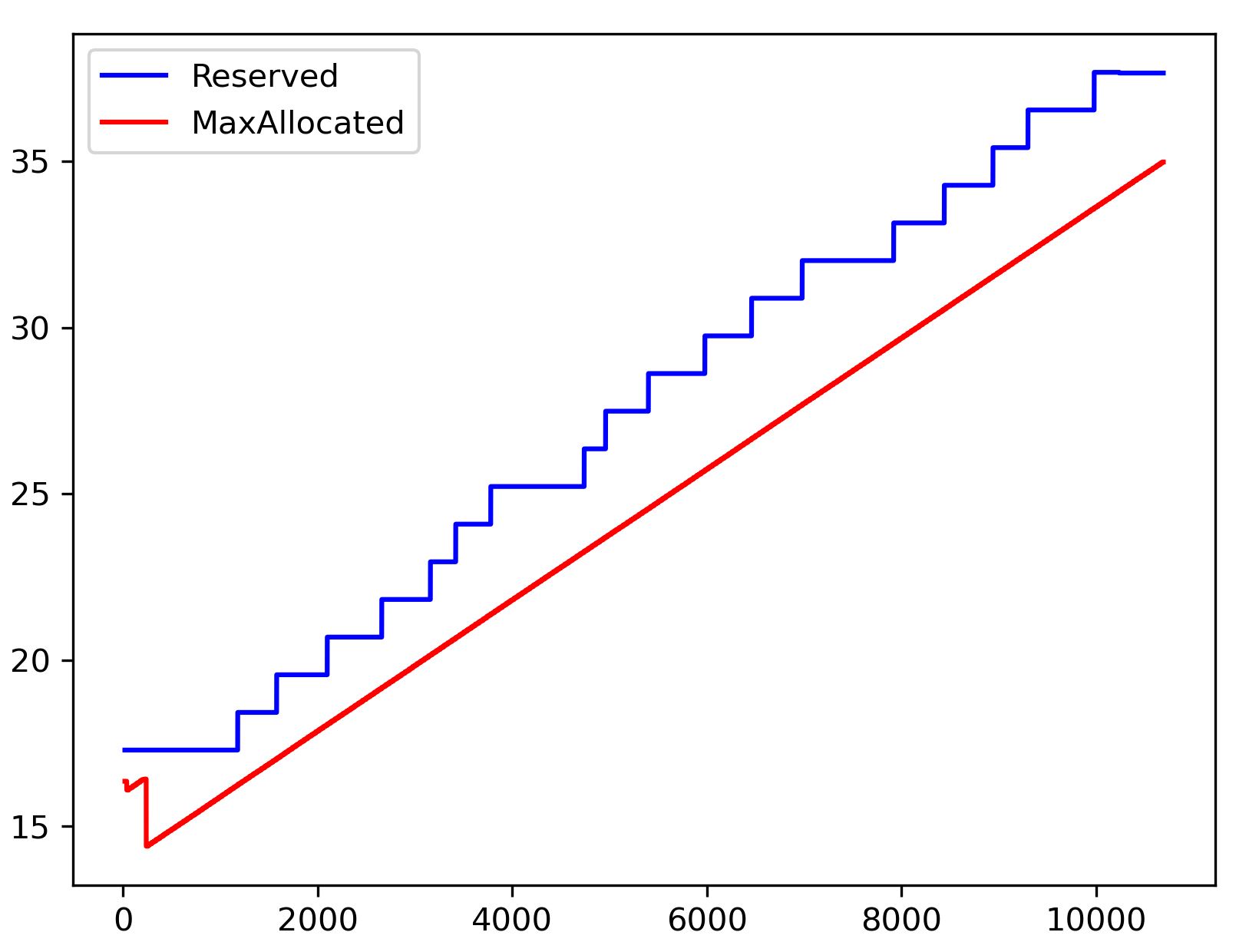
I also get this error and don’t understand what is the probel. Can it be because of memory leak? I am asking this because when I running my training loop this error happens after a few thousand iteration. Here is a plot showing max allocated memory and max reserved memory with iterations.
Usually an increase in memory usage is not caused by a leak (i.e. the memory stays allocated and cannot be freed anymore), but is caused by storing tensors attached to a computation graph by mistake and is thus expected.
This can happen e.g. if you are accumulating the outputs of your model or the loss via:
running_loss += loss
without detaching the loss tensor beforehand or by storing these tensors in e.g. a list.
Check your code if this could be the case, too.
Thank you very much for your help. The problem was to append one of the loss term to a list without detaching it. I spent a lot of time trying different thing, but a simple mistake caused it. Thanks a lot
SO heres the thing, I am facing the same issue, what should i do
CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 4.00 GiB total capacity; 3.46 GiB already allocated; 0 bytes free; 3.49 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
You are running out of memory as 0 bytes are free on your device and would need to reduce the memory usage e.g. by decreasing the batch size, using torch.utils.checkpoint to trade compute for memory, etc.
i am getting this error while training spacy ner model for cv parser
Aborting and saving the final best model. Encountered exception:
OutOfMemoryError(‘CUDA out of memory. Tried to allocate 354.00 MiB (GPU 0; 14.62
GiB total capacity; 12.11 GiB already allocated; 153.38 MiB free; 13.55 GiB
reserved in total by PyTorch) If reserved memory is >> allocated memory try
setting max_split_size_mb to avoid fragmentation. See documentation for Memory
Management and PYTORCH_CUDA_ALLOC_CONF’)
i have reduced batch size to 1 in config. cfg file, still not working what to do ?
You would need to further reduce the memory usage e.g. by changing the model architecture, by using torch.utils.checkpoint, by decreasing the spatial size of the input image (if applicable), etc.
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 100.00 MiB (GPU 0; 8.00 GiB total capacity; 3.91 GiB already allocated; 2.47 GiB free; 3.96 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CON
Do you know why I am running out of memory despite having 2.47GiB free?
Hi, I got these error but I have a 16GB card, and the xformers, sooo I don’t think I should having these problem, en about the code “torch.utils.checkpoint” I am so new to this, where should I write???
I am also facing similar problem while running Deep learning model with GPU.
OutOfMemoryError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 14.58 GiB total capacity; 14.36 GiB already allocated; 1.31 MiB free; 14.44 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
I have tried changing the suggested solution set 'PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512, 256
Also tried with smaller batch_size. But still getting same error.Please do let me know how can I resolve this
I have also tried the same model with configuration 16 vCPUs, 60 GB RAM, NVIDIA V100 (4 GPU).
But am getting the below error.
RuntimeError: Lightning can’t create new processes if CUDA is already initialized. Did you manually call torch.cuda.* functions, have moved the model to the device, or allocated memory on the GPU any other way? Please remove any such calls, or change the selected strategy. You will have to restart the Python kernel.
@ptrblck please do let me know if you have any suggestion to overcome this issue