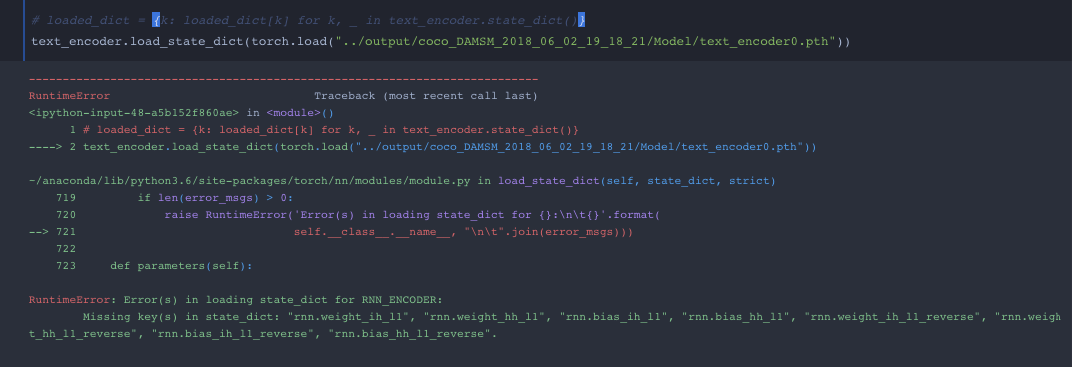
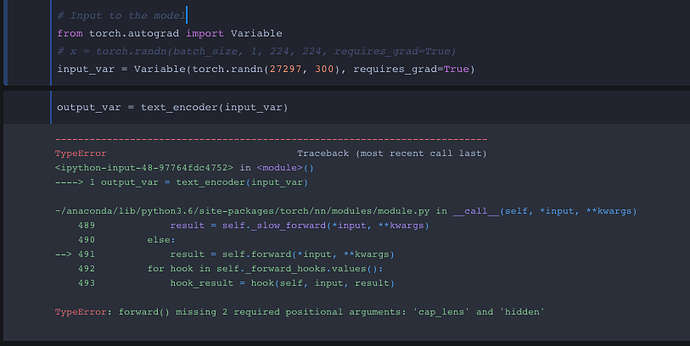
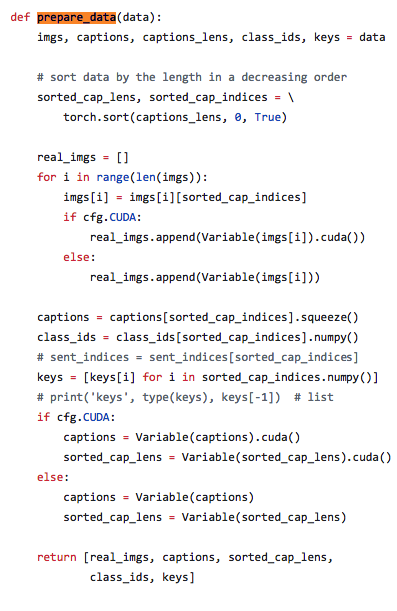
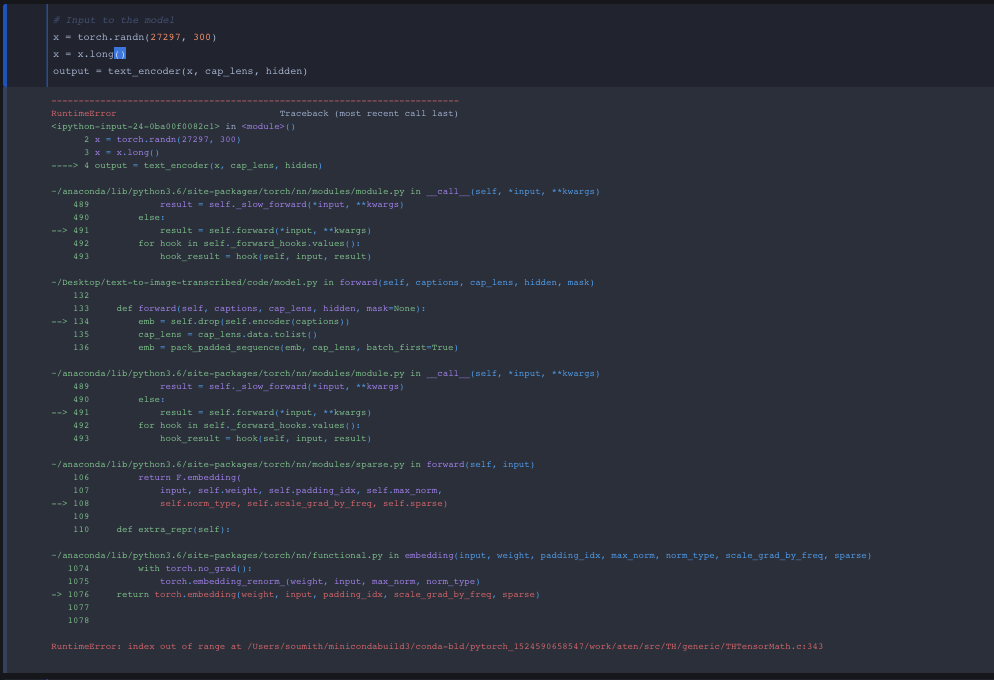
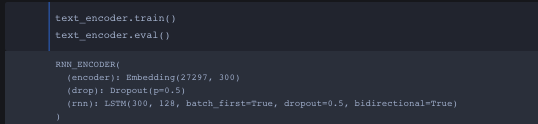
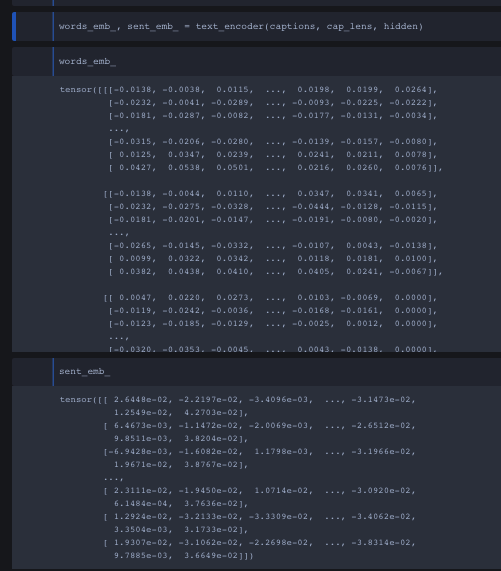
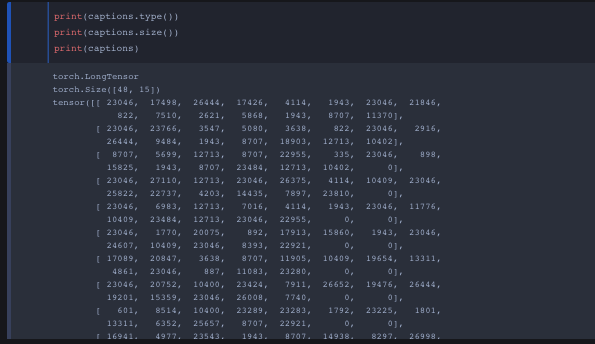
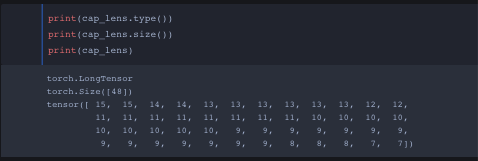
Okay this is my overview of everything I’ve learned from converting a pytorch model to ONNX. Before I converted the pytorch model I wanted to make sure the dimensions for captions, cap_lens and hidden were correct through the forward function and no errors! 
.
However I have a new problem…I get an error from exporting the model using the exact same inputs???
“TypeError: wrapPyFuncWithSymbolic(): incompatible function arguments. The following argument types are supported: (self: torch._C.Graph, arg0: function, arg1: List[torch::jit::Value], arg2: int, arg3: function) → iterator”.
I tried tupling all 3 inputs (captions, cap_lens, hidden) onto the onnx converter yet I get some sort of data type error…Before showing the output terminal from the conversion I want to show how all three inputs look like. I came to a conclusion I need to either convert all three inputs into float or long dtype and idk how to properly convert dtypes.
caption is a (48,15) with torch.LongTensor data type
cap_lens is (48,) with torch.LongTensor data type
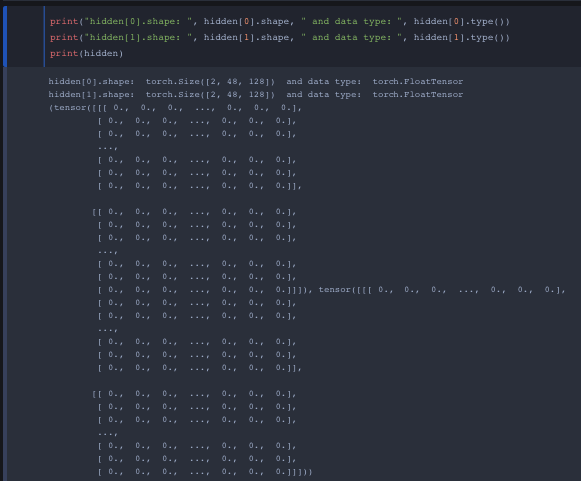
and lastly hidden is a tuple of two (2, 48, 128) with torch.FloatTensor datatype
# Export the model
torch_out = torch.onnx._export(text_encoder, # model being run
(captions_fake_input, cap_lens, hidden), # model input (or a tuple for multiple inputs)
"kol.onnx", # where to save the model (can be a file or file-like object)
export_params=True) # store the trained parameter weights inside the model file
[output]
TypeError Traceback (most recent call last)
in ()
3 (captions_fake_input, cap_lens, hidden), # model input (or a tuple for multiple inputs)
4 “kol.onnx”, # where to save the model (can be a file or file-like object)
----> 5 export_params=True) # store the trained parameter weights inside the model file
~/anaconda/lib/python3.6/site-packages/torch/onnx/init.py in _export(*args, **kwargs)
18 def _export(*args, **kwargs):
19 from torch.onnx import utils
—> 20 return utils._export(*args, **kwargs)
21
22
~/anaconda/lib/python3.6/site-packages/torch/onnx/utils.py in _export(model, args, f, export_params, verbose, training, input_names, output_names, aten, export_type)
132 # training mode was.)
133 with set_training(model, training):
→ 134 trace, torch_out = torch.jit.get_trace_graph(model, args)
135
136 if orig_state_dict_keys != _unique_state_dict(model).keys():
~/anaconda/lib/python3.6/site-packages/torch/jit/init.py in get_trace_graph(f, args, kwargs, nderivs)
253 if not isinstance(args, tuple):
254 args = (args,)
→ 255 return LegacyTracedModule(f, nderivs=nderivs)(*args, **kwargs)
256
257
~/anaconda/lib/python3.6/site-packages/torch/nn/modules/module.py in call(self, *input, **kwargs)
489 result = self._slow_forward(*input, **kwargs)
490 else:
→ 491 result = self.forward(*input, **kwargs)
492 for hook in self._forward_hooks.values():
493 hook_result = hook(self, input, result)
~/anaconda/lib/python3.6/site-packages/torch/jit/init.py in forward(self, *args)
286 _tracing = True
287 trace_inputs = _unflatten(all_trace_inputs[:len(in_vars)], in_desc)
→ 288 out = self.inner(*trace_inputs)
289 out_vars, _ = _flatten(out)
290 _tracing = False
~/anaconda/lib/python3.6/site-packages/torch/nn/modules/module.py in call(self, *input, **kwargs)
487 hook(self, input)
488 if torch.jit._tracing:
→ 489 result = self._slow_forward(*input, **kwargs)
490 else:
491 result = self.forward(*input, **kwargs)
~/anaconda/lib/python3.6/site-packages/torch/nn/modules/module.py in _slow_forward(self, *input, **kwargs)
477 tracing_state._traced_module_stack.append(self)
478 try:
→ 479 result = self.forward(*input, **kwargs)
480 finally:
481 tracing_state.pop_scope()
~/Desktop/text-to-image-transcribed/code/model.py in forward(self, captions, cap_lens, hidden, mask)
153
154 #print("======= Packed emb ====== ")
→ 155 emb = pack_padded_sequence(emb, cap_lens, batch_first=True)
156 #print("emb: ", emb)
157 #print("emb shape: ", emb.shape)
~/anaconda/lib/python3.6/site-packages/torch/onnx/init.py in wrapper(*args, **kwargs)
71
72 symbolic_args = function._unflatten(arg_values, args)
—> 73 output_vals = symbolic_fn(tstate.graph(), *symbolic_args, **kwargs)
74
75 for var, val in zip(
~/anaconda/lib/python3.6/site-packages/torch/nn/utils/rnn.py in _symbolic_pack_padded_sequence(g, input, lengths, batch_first, padding_value, total_length)
144 outputs = g.wrapPyFuncWithSymbolic(
145 pack_padded_sequence_trace_wrapper, [input, lengths], 2,
→ 146 _onnx_symbolic_pack_padded_sequence)
147 return tuple(o for o in outputs)
148
TypeError: wrapPyFuncWithSymbolic(): incompatible function arguments. The following argument types are supported:
1. (self: torch._C.Graph, arg0: function, arg1: List[torch::jit::Value], arg2: int, arg3: function) → iterator
Invoked with: graph(%0 : Long(48, 15)
%1 : Long(48)
%2 : Float(2, 48, 128)
%3 : Float(2, 48, 128)
%4 : Float(27297, 300)
%5 : Float(512, 300)
%6 : Float(512, 128)
%7 : Float(512)
%8 : Float(512)
%9 : Float(512, 300)
%10 : Float(512, 128)
%11 : Float(512)
%12 : Float(512)) {
%13 : Float(48, 15, 300) = aten::embedding[padding_idx=-1, scale_grad_by_freq=0, sparse=0](%4, %0), scope: RNN_ENCODER/Embedding[encoder]
%16 : Float(48, 15, 300), %17 : Handle = ^Dropout(0.5, False, False)(%13), scope: RNN_ENCODER/Dropout[drop]
%15 : Float(48, 15, 300) = aten::slicedim=0, start=0, end=9223372036854775807, step=1, scope: RNN_ENCODER/Dropout[drop]
%14 : Float(48, 15, 300) = aten::as_stridedsize=[48, 15, 300], stride=[4500, 300, 1], storage_offset=0, scope: RNN_ENCODER/Dropout[drop]
%18 : Long(48) = prim::Constantvalue=, scope: RNN_ENCODER
%76 : Float(502, 300), %77 : Long(15), %78 : Handle = ^PackPadded(True)(%16, %18), scope: RNN_ENCODER
%19 : Float(15!, 48!, 300) = aten::transposedim0=0, dim1=1, scope: RNN_ENCODER
%21 : Long() = aten::selectdim=0, index=47, scope: RNN_ENCODER
%20 : Long() = aten::as_stridedsize=[], stride=[], storage_offset=47, scope: RNN_ENCODER
%22 : Byte() = aten::leother={0}, scope: RNN_ENCODER
%24 : Float(7!, 48!, 300) = aten::slicedim=0, start=0, end=7, step=1, scope: RNN_ENCODER
%23 : Float(7!, 48!, 300) = aten::as_stridedsize=[7, 48, 300], stride=[300, 4500, 1], storage_offset=0, scope: RNN_ENCODER
%25 : Float(7, 48, 300) = aten::clone(%24), scope: RNN_ENCODER
%26 : Float(336, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%28 : Float(1!, 48!, 300) = aten::slicedim=0, start=7, end=8, step=1, scope: RNN_ENCODER
%27 : Float(1!, 48!, 300) = aten::as_stridedsize=[1, 48, 300], stride=[300, 4500, 1], storage_offset=2100, scope: RNN_ENCODER
%30 : Float(1!, 46!, 300) = aten::slicedim=1, start=0, end=46, step=1, scope: RNN_ENCODER
%29 : Float(1!, 46!, 300) = aten::as_stridedsize=[1, 46, 300], stride=[300, 4500, 1], storage_offset=2100, scope: RNN_ENCODER
%31 : Float(1, 46, 300) = aten::clone(%30), scope: RNN_ENCODER
%32 : Float(46, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%34 : Float(1!, 48!, 300) = aten::slicedim=0, start=8, end=9, step=1, scope: RNN_ENCODER
%33 : Float(1!, 48!, 300) = aten::as_stridedsize=[1, 48, 300], stride=[300, 4500, 1], storage_offset=2400, scope: RNN_ENCODER
%36 : Float(1!, 43!, 300) = aten::slicedim=1, start=0, end=43, step=1, scope: RNN_ENCODER
%35 : Float(1!, 43!, 300) = aten::as_stridedsize=[1, 43, 300], stride=[300, 4500, 1], storage_offset=2400, scope: RNN_ENCODER
%37 : Float(1, 43, 300) = aten::clone(%36), scope: RNN_ENCODER
%38 : Float(43, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%40 : Float(1!, 48!, 300) = aten::slicedim=0, start=9, end=10, step=1, scope: RNN_ENCODER
%39 : Float(1!, 48!, 300) = aten::as_stridedsize=[1, 48, 300], stride=[300, 4500, 1], storage_offset=2700, scope: RNN_ENCODER
%42 : Float(1!, 29!, 300) = aten::slicedim=1, start=0, end=29, step=1, scope: RNN_ENCODER
%41 : Float(1!, 29!, 300) = aten::as_stridedsize=[1, 29, 300], stride=[300, 4500, 1], storage_offset=2700, scope: RNN_ENCODER
%43 : Float(1, 29, 300) = aten::clone(%42), scope: RNN_ENCODER
%44 : Float(29, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%46 : Float(1!, 48!, 300) = aten::slicedim=0, start=10, end=11, step=1, scope: RNN_ENCODER
%45 : Float(1!, 48!, 300) = aten::as_stridedsize=[1, 48, 300], stride=[300, 4500, 1], storage_offset=3000, scope: RNN_ENCODER
%48 : Float(1!, 20!, 300) = aten::slicedim=1, start=0, end=20, step=1, scope: RNN_ENCODER
%47 : Float(1!, 20!, 300) = aten::as_stridedsize=[1, 20, 300], stride=[300, 4500, 1], storage_offset=3000, scope: RNN_ENCODER
%49 : Float(1, 20, 300) = aten::clone(%48), scope: RNN_ENCODER
%50 : Float(20, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%52 : Float(1!, 48!, 300) = aten::slicedim=0, start=11, end=12, step=1, scope: RNN_ENCODER
%51 : Float(1!, 48!, 300) = aten::as_stridedsize=[1, 48, 300], stride=[300, 4500, 1], storage_offset=3300, scope: RNN_ENCODER
%54 : Float(1!, 12!, 300) = aten::slicedim=1, start=0, end=12, step=1, scope: RNN_ENCODER
%53 : Float(1!, 12!, 300) = aten::as_stridedsize=[1, 12, 300], stride=[300, 4500, 1], storage_offset=3300, scope: RNN_ENCODER
%55 : Float(1, 12, 300) = aten::clone(%54), scope: RNN_ENCODER
%56 : Float(12, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%58 : Float(1!, 48!, 300) = aten::slicedim=0, start=12, end=13, step=1, scope: RNN_ENCODER
%57 : Float(1!, 48!, 300) = aten::as_stridedsize=[1, 48, 300], stride=[300, 4500, 1], storage_offset=3600, scope: RNN_ENCODER
%60 : Float(1!, 10!, 300) = aten::slicedim=1, start=0, end=10, step=1, scope: RNN_ENCODER
%59 : Float(1!, 10!, 300) = aten::as_stridedsize=[1, 10, 300], stride=[300, 4500, 1], storage_offset=3600, scope: RNN_ENCODER
%61 : Float(1, 10, 300) = aten::clone(%60), scope: RNN_ENCODER
%62 : Float(10, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%64 : Float(1!, 48!, 300) = aten::slicedim=0, start=13, end=14, step=1, scope: RNN_ENCODER
%63 : Float(1!, 48!, 300) = aten::as_stridedsize=[1, 48, 300], stride=[300, 4500, 1], storage_offset=3900, scope: RNN_ENCODER
%66 : Float(1!, 4!, 300) = aten::slicedim=1, start=0, end=4, step=1, scope: RNN_ENCODER
%65 : Float(1!, 4!, 300) = aten::as_stridedsize=[1, 4, 300], stride=[300, 4500, 1], storage_offset=3900, scope: RNN_ENCODER
%67 : Float(1, 4, 300) = aten::clone(%66), scope: RNN_ENCODER
%68 : Float(4, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%70 : Float(1!, 48!, 300) = aten::slicedim=0, start=14, end=15, step=1, scope: RNN_ENCODER
%69 : Float(1!, 48!, 300) = aten::as_stridedsize=[1, 48, 300], stride=[300, 4500, 1], storage_offset=4200, scope: RNN_ENCODER
%72 : Float(1!, 2!, 300) = aten::slicedim=1, start=0, end=2, step=1, scope: RNN_ENCODER
%71 : Float(1!, 2!, 300) = aten::as_stridedsize=[1, 2, 300], stride=[300, 4500, 1], storage_offset=4200, scope: RNN_ENCODER
%73 : Float(1, 2, 300) = aten::clone(%72), scope: RNN_ENCODER
%74 : Float(2, 300) = aten::viewsize=[-1, 300], scope: RNN_ENCODER
%75 : Float(502, 300) = aten::cat[dim=0](%26, %32, %38, %44, %50, %56, %62, %68, %74), scope: RNN_ENCODER
return ();
}
, <function _symbolic_pack_padded_sequence..pack_padded_sequence_trace_wrapper at 0x1c24e95950>, [16 defined in (%16 : Float(48, 15, 300), %17 : Handle = ^Dropout(0.5, False, False)(%13), scope: RNN_ENCODER/Dropout[drop]
), [15, 15, 14, 14, 13, 13, 13, 13, 13, 13, 12, 12, 11, 11, 11, 11, 11, 11, 11, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 8, 8, 8, 7, 7]], 2, <function _symbolic_pack_padded_sequence.._onnx_symbolic_pack_padded_sequence at 0x1c1be48378>