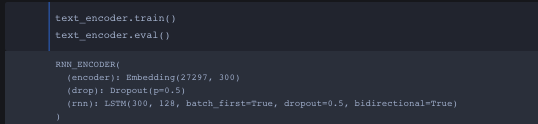
It looks like there’s something wrong with the input dimensions since I’m getting a message that I’m out of bound based on this forum post (Embeddings index out of range error)
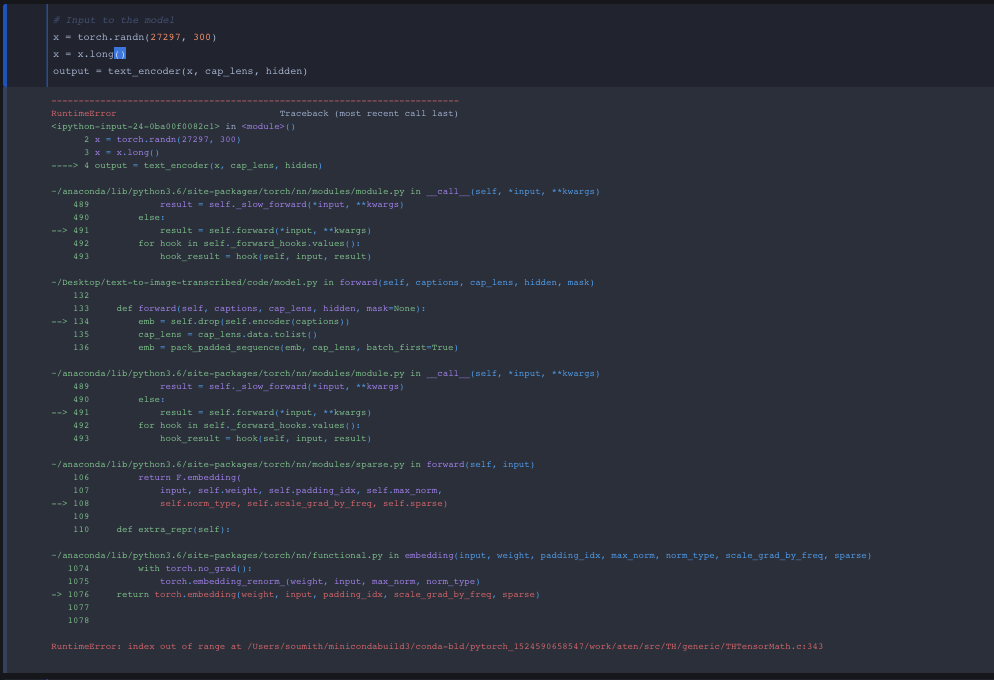
I honestly thought the first layer from the bottom picture was the required dimension. Unless I need to make my random torch input into some sort of embedding format that I’m not self aware of.