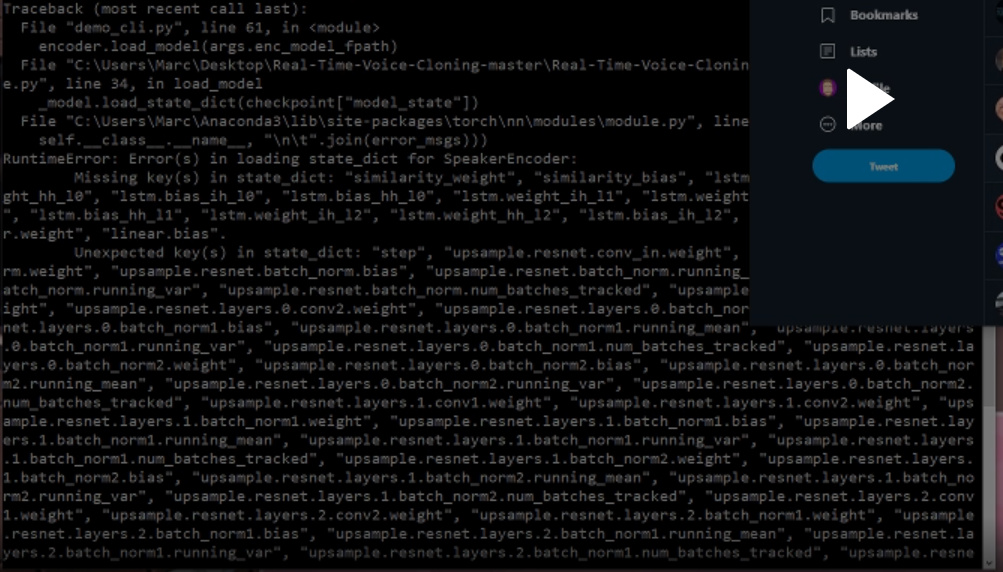
And the full error is:
Preparing the encoder, the synthesizer and the vocoder...
Traceback (most recent call last):
File "demo_cli.py", line 61, in <module>
encoder.load_model(args.enc_model_fpath)
File "C:\Users\Marc\Desktop\Real-Time-Voice-Cloning-master\Real-Time-Voice-Cloning-master\encoder\inference.py", line 34, in load_model
_model.load_state_dict(checkpoint["model_state"])
File "C:\Users\Marc\Anaconda3\lib\site-packages\torch\nn\modules\module.py", line 845, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for SpeakerEncoder:
Missing key(s) in state_dict: "similarity_weight", "similarity_bias", "lstm.weight_ih_l0", "lstm.weight_hh_l0", "lstm.bias_ih_l0", "lstm.bias_hh_l0", "lstm.weight_ih_l1", "lstm.weight_hh_l1", "lstm.bias_ih_l1", "lstm.bias_hh_l1", "lstm.weight_ih_l2", "lstm.weight_hh_l2", "lstm.bias_ih_l2", "lstm.bias_hh_l2", "linear.weight", "linear.bias".
Unexpected key(s) in state_dict: "step", "upsample.resnet.conv_in.weight", "upsample.resnet.batch_norm.weight", "upsample.resnet.batch_norm.bias", "upsample.resnet.batch_norm.running_mean", "upsample.resnet.batch_norm.running_var", "upsample.resnet.batch_norm.num_batches_tracked", "upsample.resnet.layers.0.conv1.weight", "upsample.resnet.layers.0.conv2.weight", "upsample.resnet.layers.0.batch_norm1.weight", "upsample.resnet.layers.0.batch_norm1.bias", "upsample.resnet.layers.0.batch_norm1.running_mean", "upsample.resnet.layers.0.batch_norm1.running_var", "upsample.resnet.layers.0.batch_norm1.num_batches_tracked", "upsample.resnet.layers.0.batch_norm2.weight", "upsample.resnet.layers.0.batch_norm2.bias", "upsample.resnet.layers.0.batch_norm2.running_mean", "upsample.resnet.layers.0.batch_norm2.running_var", "upsample.resnet.layers.0.batch_norm2.num_batches_tracked", "upsample.resnet.layers.1.conv1.weight", "upsample.resnet.layers.1.conv2.weight", "upsample.resnet.layers.1.batch_norm1.weight", "upsample.resnet.layers.1.batch_norm1.bias", "upsample.resnet.layers.1.batch_norm1.running_mean", "upsample.resnet.layers.1.batch_norm1.running_var", "upsample.resnet.layers.1.batch_norm1.num_batches_tracked", "upsample.resnet.layers.1.batch_norm2.weight", "upsample.resnet.layers.1.batch_norm2.bias", "upsample.resnet.layers.1.batch_norm2.running_mean", "upsample.resnet.layers.1.batch_norm2.running_var", "upsample.resnet.layers.1.batch_norm2.num_batches_tracked", "upsample.resnet.layers.2.conv1.weight", "upsample.resnet.layers.2.conv2.weight", "upsample.resnet.layers.2.batch_norm1.weight", "upsample.resnet.layers.2.batch_norm1.bias", "upsample.resnet.layers.2.batch_norm1.running_mean", "upsample.resnet.layers.2.batch_norm1.running_var", "upsample.resnet.layers.2.batch_norm1.num_batches_tracked", "upsample.resnet.layers.2.batch_norm2.weight", "upsample.resnet.layers.2.batch_norm2.bias", "upsample.resnet.layers.2.batch_norm2.running_mean", "upsample.resnet.layers.2.batch_norm2.running_var", "upsample.resnet.layers.2.batch_norm2.num_batches_tracked", "upsample.resnet.layers.3.conv1.weight", "upsample.resnet.layers.3.conv2.weight", "upsample.resnet.layers.3.batch_norm1.weight", "upsample.resnet.layers.3.batch_norm1.bias", "upsample.resnet.layers.3.batch_norm1.running_mean", "upsample.resnet.layers.3.batch_norm1.running_var", "upsample.resnet.layers.3.batch_norm1.num_batches_tracked", "upsample.resnet.layers.3.batch_norm2.weight", "upsample.resnet.layers.3.batch_norm2.bias", "upsample.resnet.layers.3.batch_norm2.running_mean", "upsample.resnet.layers.3.batch_norm2.running_var", "upsample.resnet.layers.3.batch_norm2.num_batches_tracked", "upsample.resnet.layers.4.conv1.weight", "upsample.resnet.layers.4.conv2.weight", "upsample.resnet.layers.4.batch_norm1.weight", "upsample.resnet.layers.4.batch_norm1.bias", "upsample.resnet.layers.4.batch_norm1.running_mean", "upsample.resnet.layers.4.batch_norm1.running_var", "upsample.resnet.layers.4.batch_norm1.num_batches_tracked", "upsample.resnet.layers.4.batch_norm2.weight", "upsample.resnet.layers.4.batch_norm2.bias", "upsample.resnet.layers.4.batch_norm2.running_mean", "upsample.resnet.layers.4.batch_norm2.running_var", "upsample.resnet.layers.4.batch_norm2.num_batches_tracked", "upsample.resnet.layers.5.conv1.weight", "upsample.resnet.layers.5.conv2.weight", "upsample.resnet.layers.5.batch_norm1.weight", "upsample.resnet.layers.5.batch_norm1.bias", "upsample.resnet.layers.5.batch_norm1.running_mean", "upsample.resnet.layers.5.batch_norm1.running_var", "upsample.resnet.layers.5.batch_norm1.num_batches_tracked", "upsample.resnet.layers.5.batch_norm2.weight", "upsample.resnet.layers.5.batch_norm2.bias", "upsample.resnet.layers.5.batch_norm2.running_mean", "upsample.resnet.layers.5.batch_norm2.running_var", "upsample.resnet.layers.5.batch_norm2.num_batches_tracked", "upsample.resnet.layers.6.conv1.weight", "upsample.resnet.layers.6.conv2.weight", "upsample.resnet.layers.6.batch_norm1.weight", "upsample.resnet.layers.6.batch_norm1.bias", "upsample.resnet.layers.6.batch_norm1.running_mean", "upsample.resnet.layers.6.batch_norm1.running_var", "upsample.resnet.layers.6.batch_norm1.num_batches_tracked", "upsample.resnet.layers.6.batch_norm2.weight", "upsample.resnet.layers.6.batch_norm2.bias", "upsample.resnet.layers.6.batch_norm2.running_mean", "upsample.resnet.layers.6.batch_norm2.running_var", "upsample.resnet.layers.6.batch_norm2.num_batches_tracked", "upsample.resnet.layers.7.conv1.weight", "upsample.resnet.layers.7.conv2.weight", "upsample.resnet.layers.7.batch_norm1.weight", "upsample.resnet.layers.7.batch_norm1.bias", "upsample.resnet.layers.7.batch_norm1.running_mean", "upsample.resnet.layers.7.batch_norm1.running_var", "upsample.resnet.layers.7.batch_norm1.num_batches_tracked", "upsample.resnet.layers.7.batch_norm2.weight", "upsample.resnet.layers.7.batch_norm2.bias", "upsample.resnet.layers.7.batch_norm2.running_mean", "upsample.resnet.layers.7.batch_norm2.running_var", "upsample.resnet.layers.7.batch_norm2.num_batches_tracked", "upsample.resnet.layers.8.conv1.weight", "upsample.resnet.layers.8.conv2.weight", "upsample.resnet.layers.8.batch_norm1.weight", "upsample.resnet.layers.8.batch_norm1.bias", "upsample.resnet.layers.8.batch_norm1.running_mean", "upsample.resnet.layers.8.batch_norm1.running_var", "upsample.resnet.layers.8.batch_norm1.num_batches_tracked", "upsample.resnet.layers.8.batch_norm2.weight", "upsample.resnet.layers.8.batch_norm2.bias", "upsample.resnet.layers.8.batch_norm2.running_mean", "upsample.resnet.layers.8.batch_norm2.running_var", "upsample.resnet.layers.8.batch_norm2.num_batches_tracked", "upsample.resnet.layers.9.conv1.weight", "upsample.resnet.layers.9.conv2.weight", "upsample.resnet.layers.9.batch_norm1.weight", "upsample.resnet.layers.9.batch_norm1.bias", "upsample.resnet.layers.9.batch_norm1.running_mean", "upsample.resnet.layers.9.batch_norm1.running_var", "upsample.resnet.layers.9.batch_norm1.num_batches_tracked", "upsample.resnet.layers.9.batch_norm2.weight", "upsample.resnet.layers.9.batch_norm2.bias", "upsample.resnet.layers.9.batch_norm2.running_mean", "upsample.resnet.layers.9.batch_norm2.running_var", "upsample.resnet.layers.9.batch_norm2.num_batches_tracked", "upsample.resnet.conv_out.weight", "upsample.resnet.conv_out.bias", "upsample.up_layers.1.weight", "upsample.up_layers.3.weight", "upsample.up_layers.5.weight", "I.weight", "I.bias", "rnn1.weight_ih_l0", "rnn1.weight_hh_l0", "rnn1.bias_ih_l0", "rnn1.bias_hh_l0", "rnn2.weight_ih_l0", "rnn2.weight_hh_l0", "rnn2.bias_ih_l0", "rnn2.bias_hh_l0", "fc1.weight", "fc1.bias", "fc2.weight", "fc2.bias", "fc3.weight", "fc3.bias".
TerminateHostApis in
TerminateHostApis out
Blockquote