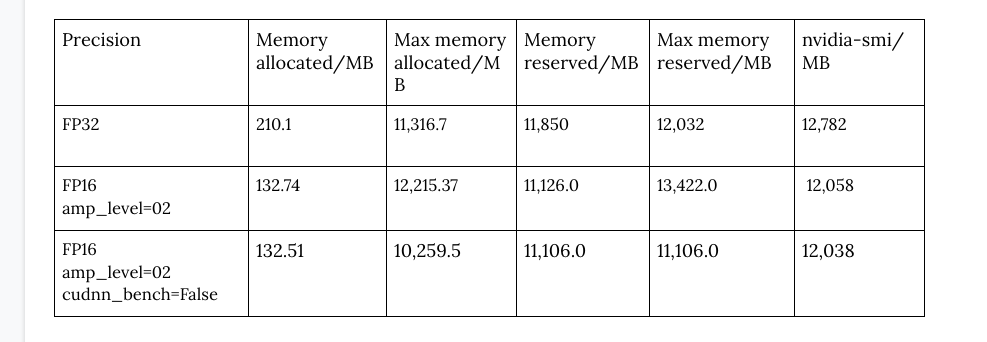
Dear all,
I have upgraded torch to 1.6 to use native mixed precision training.
I am observing some strange behavior that mixed precision training does not seem to have any effect on model memory consumption with cudnn_benchmark=True.
I am using pytorch lightning so i set the mixed precision training as
System
*Pytorch 1.6 *
Pytorch lightning 0.8.1
Linux 18.01
GPU Nvidia Tesla T4
trainer(...., precision=16, amp_level='O2')
Following is output of nvidia-smi with FP16 enabled
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.05 Driver Version: 450.51.05 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 73C P0 64W / 70W | 12230MiB / 15109MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
following is with FP16 disabled
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.05 Driver Version: 450.51.05 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 77C P0 63W / 70W | 12200MiB / 15109MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
I was playing around with other parameters and found out that if i disable cudnn_benchmark
I see ~ 14% memory reduction 12.2 GB → 10.5 GB but by disabling cudnn_benchmark my forward pass time increases significantly.
My model has 12 million trainable parameters.
I was expecting it to reduce much further as the model is quite big so the effect of FP16 should be more evident. My model contains quite some 3D convolutions as well.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.05 Driver Version: 450.51.05 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 56C P0 66W / 70W | 10578MiB / 15109MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
What do you think is the reason of such a behavior?
thanks.