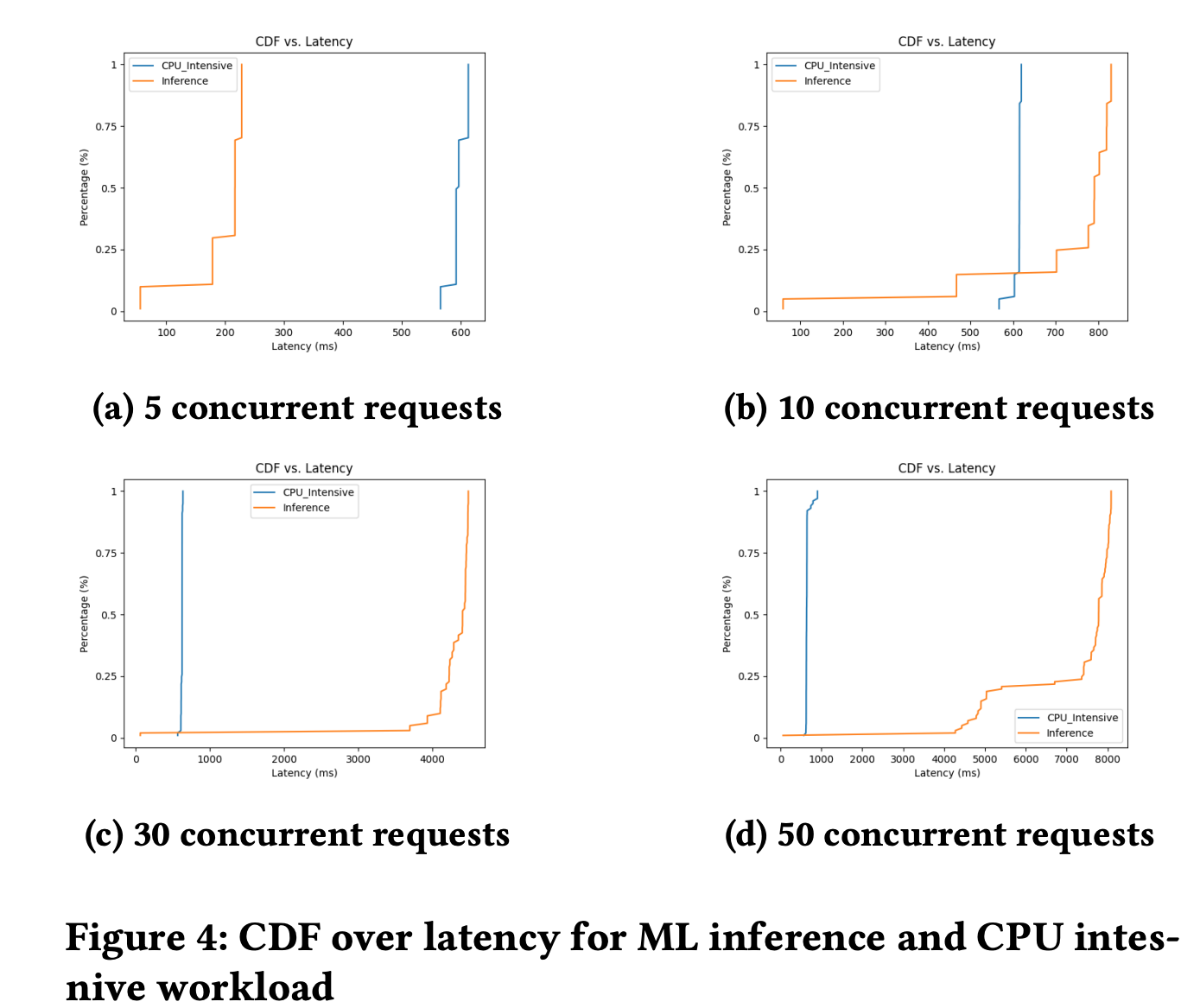
I’ve created a C++ web server which performs ML inference using Torch, and I’m using a BERT model for prediction. In my experiments, I found that my server is not scaling as expected. For one request, it takes 50 ms, but for 10 parallel requests, it is taking about 500 ms per request. I’ve tested my C++ server with other CPU-intensive workloads, and my results are good, but for ML inference, the server does not scale well. My C++ server creates one thread per connection, and I have 50 cores, so I am expecting my inference server to run 10 requests in parallel. Please find the below CDF for 5, 10, 30, 50 requests.
It would be great if someone can tell me what I’m doing wrong.
1.) Is it even possible to do C++ inference with multi threading that scales well or is there something in ML inference that is stopping me from doing so.
2.) I’m using multi threading to reduce model memory duplication and to avoid model loading times.
I think one potential issue is that numerical CPU backends used by PyTorch such as MKL/oneDNN may already use more than one thread per process by default. Do you see scaling behavior that is closer to what is expected when setting e.g., OMP_NUM_THREADS=1 and MKL_NUM_THREADS=1?
I am using torch module in C++, but the link suggests a modification in Python. So, can you please point me to how to do the same in C++? Also, it would be great if you could point me to any production C++ inference system which uses multi-threading. Thanks for taking the time to reply to my query.