Hi, I am writing a simple MLP model, but the output of the model is always the same no matter what the input is, and also each element of the output vector approaches zero.
Here is my model:
class MLP(torch.nn.Module):
def __init__(self, D_in, D_out):
super(MLP, self).__init__()
self.linear_1 = torch.nn.Linear(D_in, 1000)
self.linear_2 = torch.nn.Linear(1000, 1500)
self.linear_3 = torch.nn.Linear(1500, 1000)
self.linear_4 = torch.nn.Linear(1000, 750)
self.linear_5 = torch.nn.Linear(750, 500)
self.linear_6 = torch.nn.Linear(500, 250)
self.linear_7 = torch.nn.Linear(250, D_out)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear_1(x))
x = self.sigmoid(self.linear_2(x))
x = self.sigmoid(self.linear_3(x))
x = self.sigmoid(self.linear_4(x))
x = self.sigmoid(self.linear_5(x))
x = self.sigmoid(self.linear_6(x))
y_pred = self.linear_7(x)
return y_pred
I tried normalized my data before feeding them into model, I also tried make the model simpler, but it is still not working… my input dimension is 450 and output dimension is 120.
Can anyone give any suggestions?
I have tested my data with the MLP model integrated in scikit-learn package, it worked fine, so the problem is not with my data, but the model I built…anyone has suggestions?..
That’s a “brute force” network, so with this depth it will be learning slowly by design, even when everything is correct. But here your problem is likely the use of saturating Sigmoid, try non-saturating functions: [leaky_]relu, selu (aka self-normalizing network).
Hi, thanks for your reply, actually I tried Relu as activation as well as reducing the depth of the network, but this still happened, I am thinking about whether I am getting this weird output due to the high dimensions of my output. Any comments?
make sure to pass all of your model’s parameters to the optimizer: optimizer = torch.optim.SGD(model.parameters(), lr = 0.01, momentum=0.9) as an example.
make sure to clear the optimizer at the start of running each batch: optimizer.zero_grad()
hyperparameters
make sure your hyperparameters have an appropriate size: learning rate, batch size, weight decay, etc, and when in doubt use the defaults. If you’re using L1/L2 regularization, make sure your weight decay value is not set too high. If it is, your model might instead be optimizing for reducing the values of its parameters to 0 instead of achieving good predictions.
loss function
make sure you’re using the correct loss function for your use case (MSELoss I imagine).
monitor the gradient, see if it is not vanishing/exploding.
Hi stroncea, thanks for detailed explanation! Yes I am using MSE as my loss function, and I checked my code many times to make sure the optimizer is set correctly and the gradients are cleared at beginning of each batch.
I have 3500 training points in total and I set my batch size to 100. I also have a validation set which contains 750 data points.
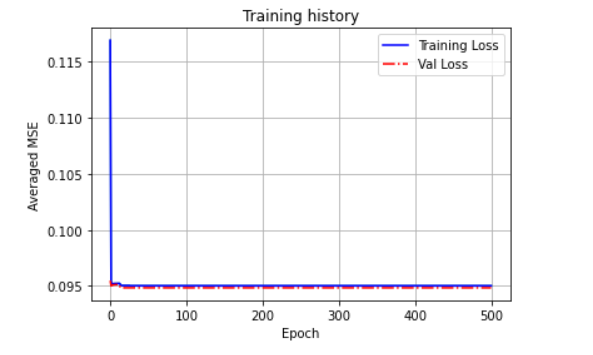
Below is the training history:
You can see that the loss quickly dropped to around 0.1 and it seems after this the model’s weights did not change anymore (so the output is always the same for all inputs).
Another thing I notice is that, if I creat a matrix A and calculate the MSE between A and y_test_true, the result is about 0.1, so this explained that all my outputs are approching zero (the model is being lazy and just set its weights to make all the outputs zero). But I have no idea how to improvee this.
loss_function = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
# optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(total_epoch_number):
loss_array_for_current_epoch = []
overall_training_loss_for_current_epoch = 0
for batch_num in range(number_of_training_data // N):
current_batch_training_input = training_set_input[batch_num*100:batch_num*100+100, :].to(device)
y_pred = model(current_batch_training_input)
# Compute loss for current batch
current_batch_training_output = training_set_output[batch_num*100:batch_num*100+100, :].to(device)
loss = loss_function(y_pred, current_batch_training_output)
# Zero gradients, perform a backward pass, and update the weights.
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_array_for_current_epoch.append(loss.item())
# Use the average loss of all batch as the overall training loss for this epoch.
overall_training_loss_for_current_epoch = np.average(loss_array_for_current_epoch)
# Validation process at current epoch
with torch.no_grad():
y_pred_val = model(validation_set_input)
val_loss = loss_function(y_pred_val, validation_set_output)
I did try this with MLPRegressor in scikit-learn package, the result is similar… (testing outputs remain same no matter what input is)
Yes, I tried adding dropout layer after activation layer and the results improve a little but not so much, and also when applying the dropout layer, the MSE loss, as expected, is a little higher compared with no dropout.
Have you tried using a single hidden layer (perhaps wider)? If that works better, the problem is with excessive depth (so gradients are either tiny or move in all directions by mini-batches). If not, either optimizer needs tweaking or there is some error (loop looks ok though).
You should be able to overfit a single layer MLP, by increasing width and/or learning rate. Then revert towards your deep model and you’ll see how it stops working.
Hi, do you mean increase the number of neurons in the hidden layer? In the model I originally used, it had 1000 neurons in the first hidden layer, if I build a MLP which contains only one hidden layer, should I increase this number even larger?
Thanks.
Yea, use a lot of neurons (10-100k maybe) to verify that your training loss can approach zero (overfit), which would indicate no coding errors and adequate optimizer params. Regarding optimizers, try Adadelta or Rprop to avoid lr tuning.