I am training a face recognition model with DDP on 8 GPUs, but I am getting loss Nan occasionally. The issue does not happen every time, but at a very high frequency, e.g. 8 out of 10 times, and the occurring time differ from each other (which makes it harder to debug).
The pipeline is: images are first fed into a DDP model for feature extraction, then those features are gathered and input into different classifiers on different GPUs to get the results and finally compute losses.
After debugging, I find that whenever the loss is nan for a certain GPU, the features extracted by this GPU is Nan. I checked the inputs, they are within normal ranges of [-1, +1]. And according to my understanding, the DDP models should be always the same among all the GPUs, it’s weird only one of the GPU outputs Nan while the rest are normal.
What might be the issue? I’ve been checking it for several days but still cannot find the problem.
-----------------------update---------------------
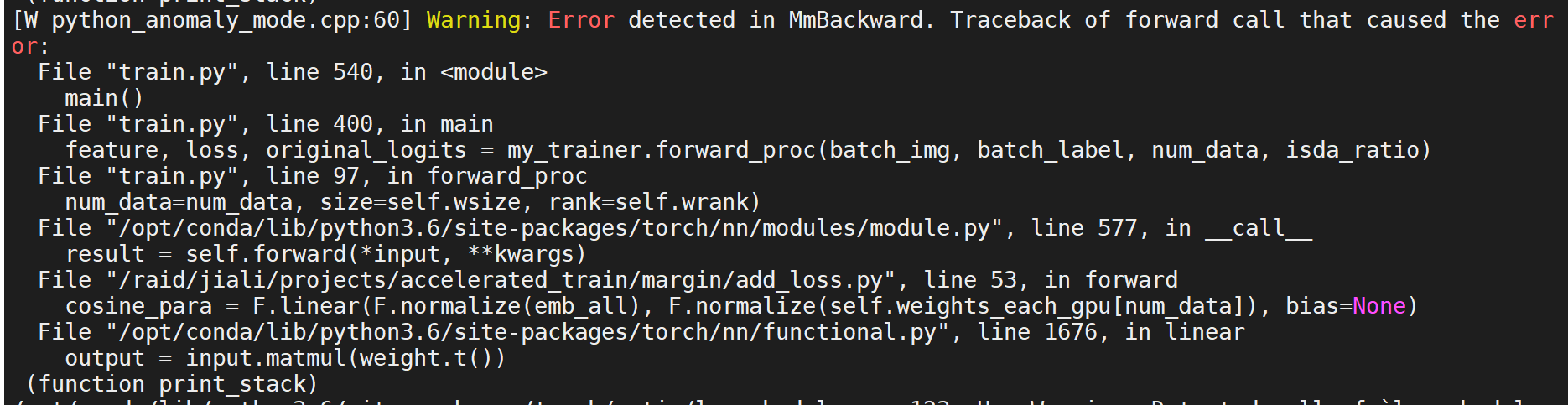
I debugged with torch.autograd.set_detect_anomaly, and the traceback shows ‘MmBackward’ returned nan values in its 0th output:
MMBackward’s input 0 being nan most likely means that your weights contain nan values?
So maybe your optimizer step that makes weights become nan?
What is the loss value before you encounter the issue? Also do you use any function that might lead to nan for special inputs (sqrt at 0 or log at <= 0 etc)?
Thanks for the reply!
I checked the inputs for F.linear, weights is normal and there is no Nan values, but emb_all has Nan. Since emb_all is the concatenation of embs from all 8 GPUs, I am very confused why it happens. All the 8 GPUs should share exactly the same weights of model (under DDP mode), if the input images are normal, then the output embs for all GPUs should also be normal.
The loss value is normal as well, e.g. 40 and I set a small lr, so it is not divergence. There is no 0 div, sqrt 0, or log 0 operations. I’ll double check this anyway.
BTW, is there any other reasons for Mmbackward returning nan? I cannot find many info on this, but overflow is mentioned in this blog: https://github.com/NVIDIA/apex/issues/440
I guess the issue might be related to fp16. I’m using torch.cuda.amp fp16 to accelerate the training process. After I switch to fp32, the training is going on smoothly.
In addition, I’m using 1cycle lr scheduler and encounter the issue, but the code works well with default step-wise lr scheduler.
But I still don’t understand, is fp16 incompatible with 1cycle lr scheduler?
All the 8 GPUs should share exactly the same weights of model (under DDP mode)
Yes they do but if you use these as embedding, each GPU use only a subset depending on the particular input it gets, so you might read some bad values on a GPU and not on another.
fp16 is not incompatible with lr scheduler. but it can lead to instability in quite a few use cases.
That why we actually have the AMP package which is quite complex that is tuned to only use fp16 when it is stable enough.