Hi there!,
I am trying to develop an algorithm that given an speed limit and height profile yields the most efficient speed. I am planning on trying reinforcement learning in a later stage to get the optimal point but first I want my model to learn to replicate the speed limit on its output since it will be nearer to the final result and therfore fine tunning will take less time.
For that I have developed a very basic code where I generate a random series of data as input. In the first step height is fixed to zero and speed is random data between an interval. I expect the model to output the very same speed vector as it was in the input
For that I planned to use transformers, the model I developed is quite simple:
class TorchformerAC (nn.Module):
def __init__(self,padding_dim,emb_dim,dict_size, device,length,dim_model=3):
super().__init__()
self.padding_dim=padding_dim
self.emb_dim=emb_dim
self.Embedding_Actor=nn.Embedding(dict_size,emb_dim).to(device)
self.Embedding_Critic=nn.Embedding(dict_size,emb_dim).to(device)
#self.positionalEncoding=PositionEncoding(padding_dim, emb_dim)
self.Transf_actor=nn.Transformer(d_model=dim_model, nhead=2, num_encoder_layers=8,
num_decoder_layers=8, dim_feedforward=256,
dropout=0.1,
custom_encoder=None, custom_decoder=None,
layer_norm_eps=1e-05, batch_first=True,
norm_first=False, device=None, dtype=None).to(device)
self.Transf_critic=nn.Transformer(d_model=dim_model, nhead=2, num_encoder_layers=8,
num_decoder_layers=8, dim_feedforward=256,
dropout=0.1,
custom_encoder=None, custom_decoder=None,
layer_norm_eps=1e-05, batch_first=True,
norm_first=False, device=None, dtype=None).to(device)
self.actor = nn.Linear(dim_model, dict_size)
self.critic = nn.Linear(dim_model, 1)
self.Soft=nn.Softmax(1)
self.apply(self._init_weights)
self.length=length
self.dropout = nn.Dropout(p=0.1)
self.dim_model=dim_model
def forward (self,Encoder_inputs,Decoder_inputs,tgt_mask,src_key_padding_mask,positional_encoding=True,Embedding=True):
x=Encoder_inputs.unsqueeze(0) #Batch x Seq_length
y=Decoder_inputs.unsqueeze(0) #Batch x Seq_length
x=self.Embedding_Actor(x.type(torch.int32)) * math.sqrt(self.dim_model)
y=self.Embedding_Actor(y.type(torch.int32)) * math.sqrt(self.dim_model)
if positional_encoding:
xpe=torch.tensor(PositionEncoding(self.padding_dim, self.emb_dim)).unsqueeze(0)
ype=torch.tensor(PositionEncoding(len(y[0]), self.emb_dim)).unsqueeze(0) #(y.shape[-2], self.emb_dim))
x=self.dropout(torch.add(x,xpe))
y=self.dropout(torch.add(y,ype))
x = self.Transf_actor(x.type(torch.float32),y.type(torch.float32) ,tgt_mask=tgt_mask, src_key_padding_mask=src_key_padding_mask.unsqueeze(0))
x=self.dropout(x)
out =Categorical(self.Soft(self.actor(x))) #Categorical
return out
And for the training I use (I added up the acuracy to the loss since eventually seemed to help in the training):
def train (agent, optimizer, nepisodes,writer):
# TRY NOT TO MODIFY: start the game
i_episode = 0
SOS_token = torch.tensor([0]).to(device)
agent.train()
real_loss=torch.tensor(0)
loss_ = nn.CrossEntropyLoss()
success=0
adaptative_lr=False
for i_episode in range(1, n_episodes):
print (i_episode,n_episodes)
# Annealing the rate if instructed to do so.
cmpl=2 #int(random.random()*5)
env.reset(new_Data=True,plot=False)
maxlr=1e-3
lrnow = learning_rate #+(maxlr-learning_rate)*i_episode/n_episodes
optimizer.param_groups[0]["lr"] = lrnow
tgt_mask=create_tgt_mask(env.length+1)
logits = agent.forward(env.table[:,1].to(device),env.table[0:env.length+1,1].to(device),tgt_mask, env.src_key_padding_mask)
#### Cross entropy real loss ####
real_loss=loss_(logits.probs[0] ,env.table[:,1][1:env.length+2].to(device).long())
outputs=logits.sample() #torch.tensor([np.argmax(a.detach()) for a in logits.probs[0]])
accuracy=(abs(outputs-env.table[:,1][1:env.length+2]).to(device).long()).numpy().mean()
if i_episode>15000:
real_loss=real_loss+accuracy
else:
real_loss=real_loss+accuracy/10 #*i_episode/n_episodes
optimizer.zero_grad()
real_loss.backward()
nn.utils.clip_grad_norm_(agent.parameters(), 0.5)
optimizer.step()
env.close()
writer.close()
Hyperparameters are:
learning_rate=1e-5
padding_dim=8
dict_size=10 #Interval within speed limit values are generated
emb_dim = 8 #Since the application is simple I chose a low value
model_size=emb_dim
However, I do not manage the model to correctly learn to replicate the input. The application should be fairly simple.
I am not very familiar with transformers and there could be some misunderstanding or errors in my code. Could someone help me understand what is happening?
Pd.
Loss evolution seems to be fine, at lease formy knowledge:
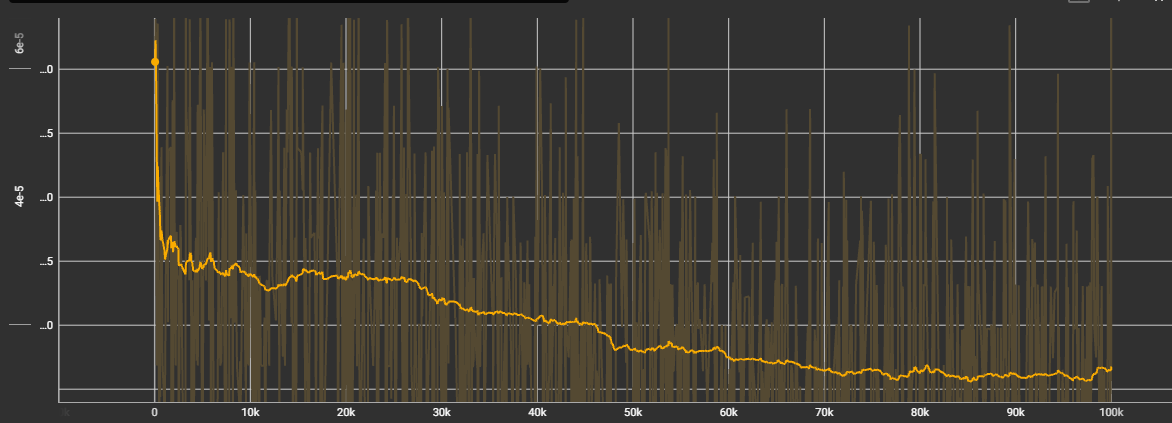
But the learning evolution does not improve