Hi, I am trying to train a single non-local block (as described in [1711.07971] Non-local Neural Networks), but the network seems not converge at all.
The general idea is (i) taking a batch of extracted features (bs, c, t, h, w) from customized video clips as input (I use ResNet 3D as the backbone), (ii) forwarding the input into a non-local block, (iii) output a score between [0, 1] as a regression task.
I trained the model with 5-fold cross validation, 60 epochs, batch size 16, initial learning rate 0.001 and reduced by 0.1 every 20 epochs, loss function MSE, optimizer Adam.
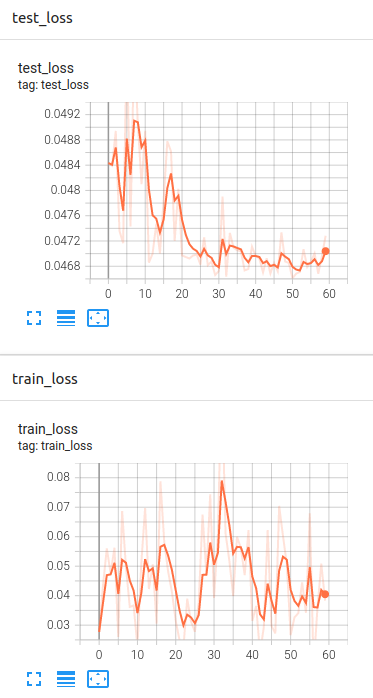
I got the averaged loss on test set being 0.047283. However, the plotted loss figures seem indicating the training does not learn anything… The training loss doesn’t decrease at all. I tried to change the batch size to 32, learning rate start from 0.0001, the results are very similar.
I am not sure if my codes have errors or any steps got wrong. ![]()
# training code
def train(data):
k_folds = 5
results = {}
kfold = KFold(n_splits=k_folds, shuffle=True)
loss_func = nn.MSELoss()
for fold, (train_ids, test_ids) in enumerate(kfold.split(data)):
train_subsampler = SubsetRandomSampler(train_ids)
test_subsampler = SubsetRandomSampler(test_ids)
train_loader = DataLoader(data,
batch_size=16,
sampler=train_subsampler)
test_loader = DataLoader(data,
batch_size=16,
sampler=test_subsampler)
net = Nonlocal()
if torch.cuda.is_available():
net = nn.DataParallel(net)
net.cuda()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
scheduler = StepLR(opt, step_size=20, gamma=0.1)
for epoch_index in range(60):
torch.set_grad_enabled(True)
net.train()
for train_batch_index, (img_batch,
label_batch) in enumerate(train_loader):
if torch.cuda.is_available():
img_batch = img_batch.cuda().float()
label_batch = label_batch.cuda().float()
predict = net(img_batch)
loss = loss_func(predict, label_batch)
net.zero_grad()
loss.backward()
opt.step()
torch.set_grad_enabled(False)
net.eval()
total_loss = []
total_sample = 0
for test_batch_index, (img_batch,
label_batch) in enumerate(test_loader):
if torch.cuda.is_available():
img_batch = img_batch.cuda().float()
label_batch = label_batch.cuda().float()
predict = net(img_batch)
loss = loss_func(predict, label_batch)
total_loss.append(loss)
total_sample += img_batch.size(0)
net.train()
mean_loss = sum(total_loss) / total_loss.__len__()
results[fold] = mean_loss
print(f'(Test) loss:{mean_loss.item():4f}')
scheduler.step()
fold_loss = 0.0
for key, value in results.items():
fold_loss += value
# Network
class Nonlocal(nn.Module):
def __init__(self):
super(Nonlocal_FC, self).__init__()
self.nl = NONLocalBlock3D(in_channels=1024)
self.maxpool = nn.MaxPool3d(kernel_size=(4, 7, 7))
self.avgpool = nn.AdaptiveAvgPool3d((1, 1, 1))
self.fc = nn.Sequential(nn.Linear(in_features=1024, out_features=1))
def forward(self, x):
batch_size = x.size(0)
x = self.nl(x)
x = self.avgpool(x).view(batch_size, -1)
x = self.fc(x)
return x
# 3D Non-local block
# The code from https://github.com/AlexHex7/Non-local_pytorch/blob/master/lib/non_local_gaussian.py is used.