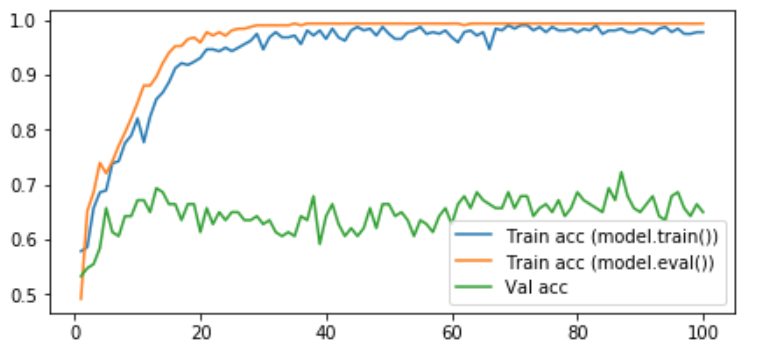
If my model includes BatchNorm or Dropout layers, do I need to set my model in evaluation mode before computing the training accuracy?
def accuracy(batch, model):
x, y = batch
y_pred = (model.predict(x)).type(torch.FloatTensor)
y = y.unsqueeze(1)
correct = (y_pred == y).type(torch.FloatTensor)
return correct.mean()
def train(data, model, optimizer, criterion, epochs):
train_dl, val_dl = data
train_epoch_loss = []
train_epoch_acc = []
val_epoch_loss = []
val_epoch_acc = []
for epoch in range(epochs): # start training
# start epoch
train_batch_loss = []
train_batch_acc = []
val_batch_loss = []
val_batch_acc = []
for batch in train_dl:
# start train batch
model.train() # enter train mode
x, y = batch
y = torch.unsqueeze(y, 1)
y_pred = model.forward(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_batch_loss.append(loss)
model.eval() # enter evaluation mode
with torch.no_grad():
train_batch_acc.append(accuracy(batch, model)) # evaluate mini-batch train accuracy in evaluation
# train_batch_acc.append(accuracy(batch, model)) # evaluate mini-batch train accuracy in train mode
train_epoch_loss.append(torch.tensor(train_batch_loss).mean())
train_epoch_acc.append(torch.tensor(train_batch_acc).mean())
model.eval() # enter evaluation mode
with torch.no_grad():
for batch in val_dl:
# start validation batch
x, y = batch
y = torch.unsqueeze(y, 1)
y_pred = model.forward(x)
loss = criterion(y_pred, y)
val_batch_loss.append(loss)
val_batch_acc.append(accuracy(batch, model))
val_epoch_loss.append(torch.tensor(val_batch_loss).mean())
val_epoch_acc.append(torch.tensor(val_batch_acc).mean())