Hi everyone! Preparing to deploy a trained model to AWS (code below). Not sure how to configure Model.eval() to take in simulated user-input and provide an output.
This is what I’ve got so far:
model.eval()
with torch.no_grad():
y_val = model(inputColumns, inputNumColumns)
loss = loss_function(y_val, test_outputs)
print(f'Loss: {loss:.8f}')
inputColumns are categorical and inputNumColumns are numerical.
print(inputColumns.shape)
print(inputNumColumns.shape)
torch.Size([3, 1])
torch.Size([3, 1])
I am getting this error:
IndexError: index 1 is out of bounds for dimension 1 with size 1
Any help would be much appreciated!
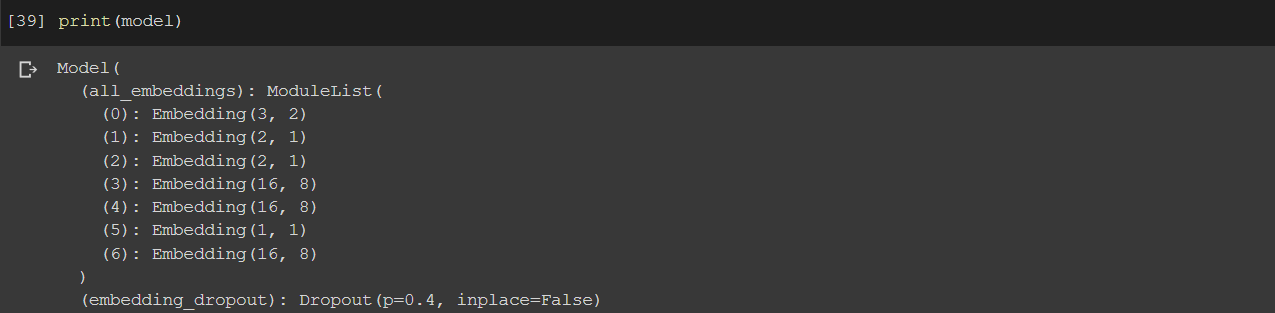
This is the model:
class Model(nn.Module):
def __init__(self, embedding_size, num_numerical_cols, output_size, layers, p=0.4):
super().__init__()
self.all_embeddings = nn.ModuleList([nn.Embedding(ni, nf) for ni, nf in embedding_size])
#ni is number of embeddings
#nf is the embedding dimensions(or number of features)
self.embedding_dropout = nn.Dropout(p) # p is the dropout rate
self.batch_norm_num = nn.BatchNorm1d(num_numerical_cols) #Only applied to the numerical column
all_layers = []
num_categorical_cols = sum((nf for ni, nf in embedding_size))
input_size = num_categorical_cols + num_numerical_cols
for i in layers:
all_layers.append(nn.Linear(input_size, i))
all_layers.append(nn.ReLU(inplace=False))
all_layers.append(nn.BatchNorm1d(i))
all_layers.append(nn.Dropout(p))
input_size = i
all_layers.append(nn.Linear(layers[-1], output_size))
self.layers = nn.Sequential(*all_layers)
def forward(self, x_categorical, x_numerical):
embeddings = []
for i,e in enumerate(self.all_embeddings):
embeddings.append(e(x_categorical[:,i]))
x = torch.cat(embeddings, 1)
x = self.embedding_dropout(x)
x_numerical = self.batch_norm_num(x_numerical) #Inputs the batch normalized numbers
x = torch.cat([x, x_numerical], 1)
x = self.layers(x)
return x
I assume the error is thrown in these lines of code:
for i,e in enumerate(self.all_embeddings):
embeddings.append(e(x_categorical[:,i]))
Could you check the shape of self.all_embeddings?
Based on your input, if should be only 1, to be able to index x_categorical at dim1.
@ptrblck Thank you for taking a look! I just recently started working with embeddings so I want to make sure I understand your comment.
In the model.train() section (below) the
for i,e in enumerate(self.all_embeddings):
embeddings.append(e(x_categorical[:,i]))
takes in embeddings of these sizes
In the model.eval() section, the embeddings are this size
torch.Size([3, 1])
Is there a different way to check the shape of self.all_embeddings?
Based on the code x_categorical should have the shape [batch_size, len(self.all_embeddings), *], since you are indexing this tensor in dim1.
If you are passing x_categorical as a tensor with the shape [3, 1], self.all_embeddings can only contain a single nn.Embedding layer.
Could you explain your use case a bit more and how you would like to use the for loop?
@ptrblck I have used this open source model as the basis for mine. From the description:
Inside the constructor, a few variables are initialized. Firstly, the all_embeddings variable contains a list of ModuleList objects for all the categorical columns. The embedding_dropout stores the dropout value for all the layers. Finally, the batch_norm_num stores a list of BatchNorm1d objects for all the numerical columns.
Next, to find the size of the input layer, the number of categorical and numerical columns are added together and stored in the input_size variable. After that, a for loop iterates and the corresponding layers are added into the all_layers list. The layers added are:
-
Linear : Used to calculate the dot product between the inputs and weight matrixes
-
ReLu : Which is applied as an activation function
-
BatchNorm1d : Used to apply batch normalization to the numerical columns
-
Dropout : Used to avoid overfitting
After the for loop, the output layer is appended to the list of layers. Since we want all of the layers in the neural networks to execute sequentially, the list of layers is passed to the nn.Sequential class.
Next, in the forward method, both the categorical and numerical columns are passed as inputs. The embedding of the categorical columns takes place in the following lines.
embeddings = []
for i, e in enumerate(self.all_embeddings):
embeddings.append(e(x_categorical[:,i]))
x = torch.cat(embeddings, 1)
x = self.embedding_dropout(x)
The batch normalization of the numerical columns is applied with the following script:
x_numerical = self.batch_norm_num(x_numerical)
Finally, the embedded categorical columns x and the numeric columns x_numerical are concatenated together and passed to the sequential layers .
This main issue is that this model was not designed with a model.eval() mode. Thank you in advance for your help!
So, the solution is: came from the shape of your tensors being correct. In order for the tensor to be valid it must have a valid length, and in this case the same columns as the training data. So in our case we would want the tensor for categorical data to be (1,7) and (1,8) for numerical data
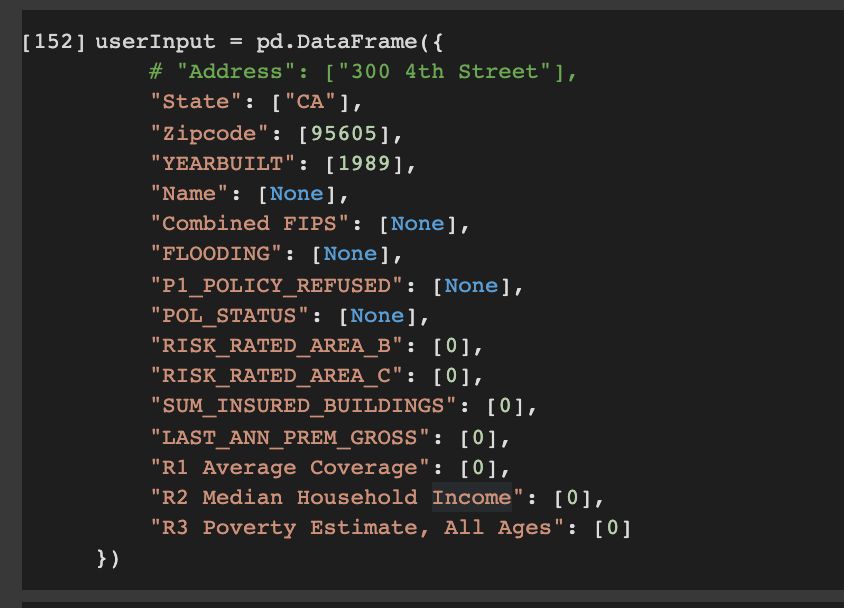
This is the data I used to mock it, keeping the columns we had in the original training dataset that was stacked, but just setting them to 0 and null
Thanks for the update.
Based on your description you are missing some categorical features during evaluation.
Replacing them with a zero or invalid value might yield bad performance or invalid outputs (e.g. NaNs).
You could try to replace the missing values with the mean or median from your training set for this particular feature.
Hi @ptrblck - duly noted! Since last post, I’ve made alot of progress (saved my models weights using torch.save(model.state_dict(), ‘.pth’) and have been able to load it in .eval() in a new file).
I am confused how to change my eval (formerly training loop) to iterate over the new data set just one time to produce a binary prediction? Any advice you could give is greatly appreciated. Cheers!
epochs = 1
aggregated_losses = []
for x in range(epochs):
x += 1
y_pred = model(inputCatColumns, inputNumColumns)
single_loss = loss_function(y_pred, train_outputs)
aggregated_losses.append(single_loss)
if x%25 == 1:
print(f'epoch: {x:3} loss: {single_loss.item():10.8f}')
optimizer.zero_grad()
single_loss.backward()
optimizer.step()
#scheduler.step(x)
print(f'epoch: {x:3} loss: {single_loss.item():10.10f}')
with torch.no_grad():
y_val = model(inputCatColumns, inputNumColumns)
loss = loss_function(y_val, test_outputs)
print(f'Loss: {loss:.8f}')
That sounds like a great progress!
I assume your model outputs a single logit, since you are dealing with a binary prediction?
If that’s the case, this dummy code might be a good starter:
model.eval()
preds = []
with torch.no_grad():
y_val = model(inputCatColumns, inputNumColumns)
preds.append(y_val > 0.) # if y_val are logits
loss = loss_function(y_val, test_outputs)
print(f'Loss: {loss:.8f}')
preds = torch.stack(preds)
Let me know, if that helps or if I misunderstood your question.
@ptrblck That dummy code looks like a great start. When I run it, I get this an error. Should I not be converting my new data set to tensors like I had to for the model training? If so, would I just pass the values in ‘raw’ so to speak?
['POL_STATUS', 'P1_POLICY_REFUSED', 'FLOODING', 'Zipcode', 'Combined FIPS', 'State', 'Name']
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-62-c9aa9c799384> in <module>()
1 preds = []
2 with torch.no_grad():
----> 3 y_val = model(inputCatColumns, inputNumColumns)
4 preds.append(y_val > 0.) # if y_val are logits
5 loss = loss_function(y_val, test_outputs)
1 frames
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
530 result = self._slow_forward(*input, **kwargs)
531 else:
--> 532 result = self.forward(*input, **kwargs)
533 for hook in self._forward_hooks.values():
534 hook_result = hook(self, input, result)
<ipython-input-35-5bbeaf977447> in forward(self, x_categorical, x_numerical)
28 print(x_categorical)
29 for i,e in enumerate(self.all_embeddings):
---> 30 print(x_categorical[:,i])
31 embeddings.append(e(x_categorical[:,i]))
32
TypeError: list indices must be integers or slices, not tuple
Ah, yeah sure. You would have to process the data in the same way.
@ptrblck Great, thats what I am currently doing. The only difference between training the model, and eval mode is now I am only passing in a single row of data (but still preprocessing the same way). Is this the right construction of the eval loop or should I be doing it differently?
Also, to load in the single row, should I be using the DataLoader?
Cheers!
The code looks good.
Yes, you could use the DataLoader as a convenient method.
@ptrblck Thanks for that suggestion! The new prediction block is running into this error - I found this solve for it but am confused because the data being used has already been converted into a numpy array
name = userInput['Name'].cat.codes.values
inputColumns = np.stack([name, etc...], 1)
and then converted over to tensors.
inputColumns = torch.tensor(inputColumns, dtype=torch.int64)
Is there something wrong in this process that would cause this error? The same process worked for the
model.train() function.
['POL_STATUS', 'P1_POLICY_REFUSED', 'FLOODING', 'Zipcode', 'Combined FIPS', 'State', 'Name']
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-62-4fec13edb637> in <module>()
1 preds = []
2 with torch.no_grad():
----> 3 newY_val = model(inputCatColumns, inputNumColumns)
4 preds.append(newY_val > 0.) # if y_val are logits
5 loss = loss_function(newY_val, test_outputs)
1 frames
<ipython-input-35-5bbeaf977447> in forward(self, x_categorical, x_numerical)
28 print(x_categorical)
29 for i,e in enumerate(self.all_embeddings):
---> 30 print(x_categorical[:,i])
31 embeddings.append(e(x_categorical[:,i]))
32
TypeError: list indices must be integers or slices, not tuple
What does print(x_categorical) return?
The indexing should work, if it’s a tensor.