I made a simple model to see if using my GPU would improve speed, it did not. I want to understand if my GPU works correctly or whether I need to change settings to have more benefit from GPU.
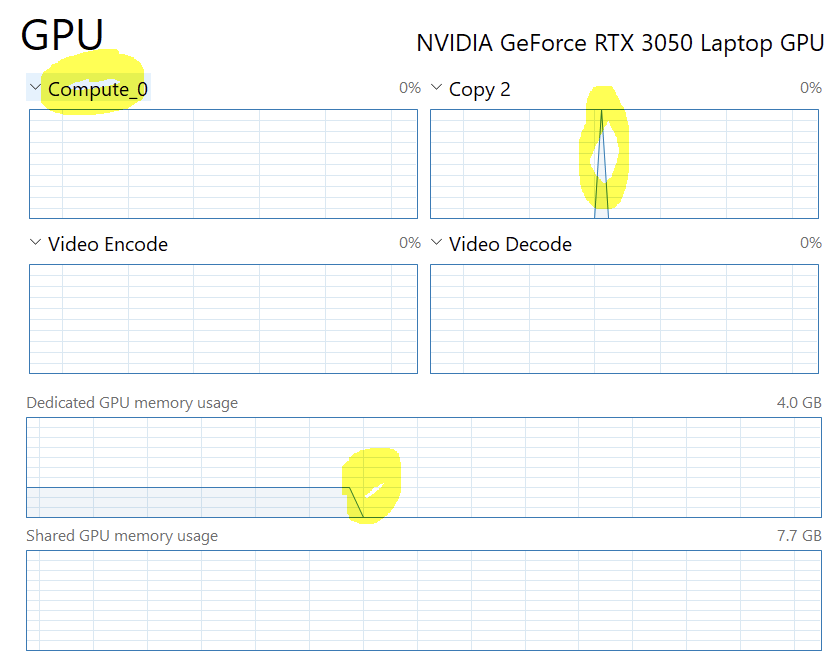
My GPU is recognized, but… in the task manager it seems to be never busy.
Would my GPU have more benefit if I changed settings (like batch size, or larger model, or more data)?
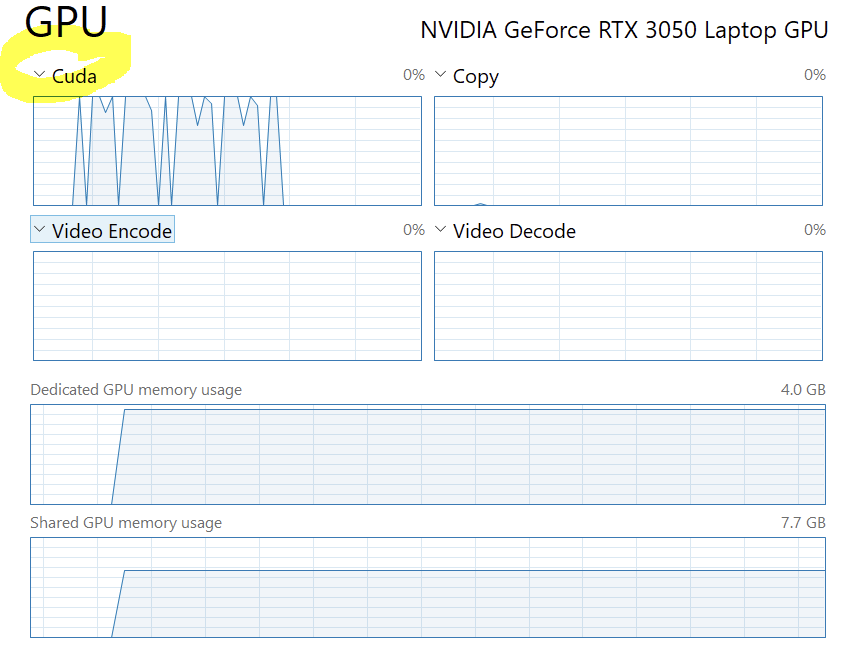
You would need to select the compute view in Windows’ Task Manager as the default view won’t show the utilization of compute applications.
Yes, increasing the workload should increase the utilization as your current use case might be CPU-limited. If you want to use this small model, you might want to use CUDA Graphs as it will reduce the CPU workload.
Thanks @ptrblck . I tried the compute view in the task manager but that doesn’t show anything.
I ran a different code snippet this time (see below), which maybe doesn’t show in compute? I only see a spike when I close/restart the python kernel in one or two of the Copy views.
nvidia-smi in cmd gives me most hope that my GPU is doing something. Temperature increases from 45 to 76 Celsius and the Volatile GPU-Util goes from 0% to 100%
import torch
import time
device = "cuda"
x = torch.randn(10000, 10000)
## CPU version
start_time = time.time()
_ = torch.matmul(x, x)
end_time = time.time()
print(f"CPU time: {(end_time - start_time):6.5f}s")
for _ in range(10):
## GPU version
x = x.to(device)
_ = torch.matmul(x, x) # First operation to 'burn in' GPU
# CUDA is asynchronous, so we need to use different timing functions
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
_ = torch.matmul(x, x)
end.record()
torch.cuda.synchronize() # Waits for everything to finish running on the GPU
print(f"GPU time: {0.001 * start.elapsed_time(end):6.5f}s") # Milliseconds to seconds
# CPU time: 20.77174s
# GPU time: 0.59403s
Thanks for your reply. And indeed, I see that with a larger model and/or larger batch size, GPU is faster.
Besides the speed of blasting through samples, there is the performance, and from what I read online, a smaller batch size is considered to generalize better right? So, that’s one reason to not go overboard with an extremely large batch size, I guess.
It’s quite the opposite. Larger batch size is better for generalization. Usually memory constraints are the reason for smaller batches. But accumulating gradients before backprop across batches can mimic a larger batch size.
" It is often reported that when increasing the batch size for a problem, there exists a threshold after which there is a deterioration in the quality of the model. This behavior can be observed for the F2 and C1 networks in Figure 4. In both of these experiments, there is a batch size (≈ 15000 for F2 and ≈ 500 for C1) after which there is a large drop in testing accuracy."
In other words, accuracy increases up to a certain point as batch size increases, until around 15,000 and 500 respectively in these given models and datasets. If your batch size is 32, you’re probably still well below that threshold.
Recently, while working on my project, I trained a neural network with approximately 10K parameters. Initially, I used a batch size of 128, and the network converged quickly. To better utilize my GPU, I increased the batch size to 2048, but to my surprise, the convergence rate slowed down compared to 128.
May be do I need to reduce my learning rate, if I increase my batch size or vice versa for small batch sizes ?
One thing I learned is that larger batch sizes often lead to better generalization, while smaller batch sizes tend to result in faster convergence. How do I know which one to follow.
The paper shared earlier by @Eardrum7 suggested that larger batch size(as in 10% or more of the total training data) showed a consistently lower performance drop.
However, I don’t know of any definitive studies that show how this behavior scales based on total dataset size. That would be interesting to see.
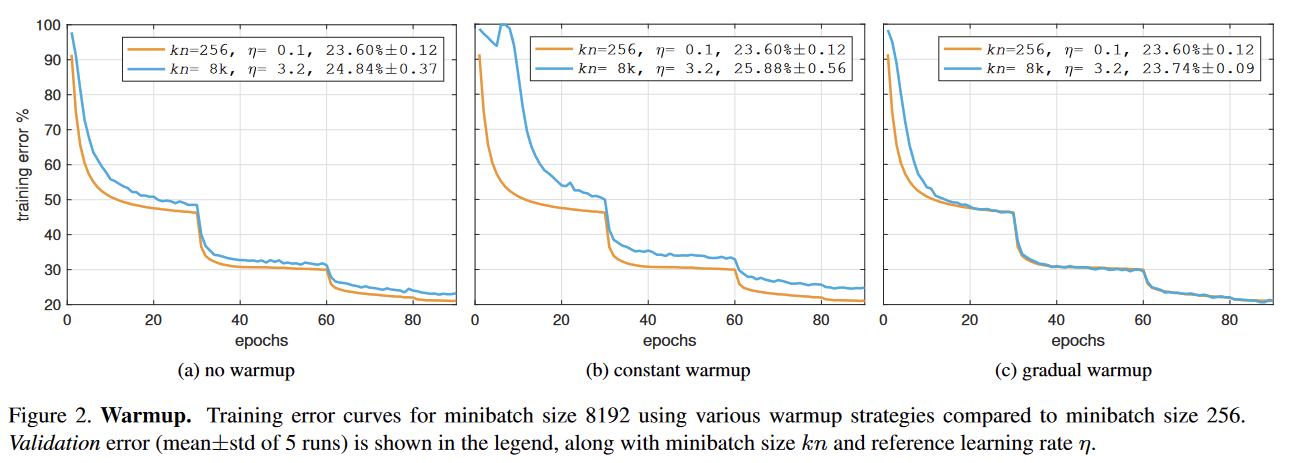
With a larger batch size, you have fewer update steps per epoch. So, with the same learning rate you converge slower. If you want to use a larger batch size you can increase the learning rate and have the same convergence speed. See this paper.
They show that you can have the same convergence speed, but due to larger batch size, much faster computation, resulting in less total time. You do have to be careful with the first updates, see Figure 2.