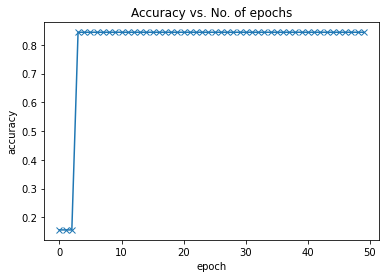
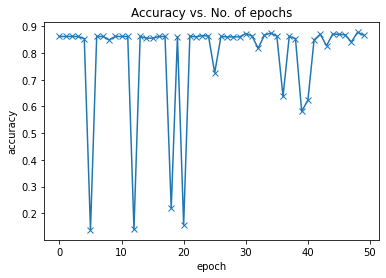
My code for a custom model based on the transformer encoder layer of the Vision Transformer is not converging with the binary classification task as shown below, while the multi-class classification is converging with 50 epochs and SGD optimizer with a learning rate of 0.005. I tried with both cross-entropy and binary cross-entropy loss functions, but both didn’t work. What might be the issues here?
The code for the model is as follows
class ViT(ImageClassificationBase):
def __init__(self,
img_size=224, # from Table 3
num_channels=3,
patch_size=16,
embedding_dim=768, # from Table 1
dropout=0.1,
num_transformer_layers=6, # from Table 1
num_heads=16,
num_classes=2)
super().__init__()
self.layers = num_transformer_layers
# Assert image size is divisible by patch size
assert img_size % patch_size == 0, "Image size must be divisble by patch size."
assert embedding_dim % num_heads == 0, "Embedding dimension should be divisible by num_heads."
# 1. Create patch embedding
self.patch_embedding = PatchEmbedding(in_channels=num_channels,
patch_size=patch_size,
embedding_dim=embedding_dim)
# 2. Create class token
self.class_token = nn.Parameter(torch.randn(1, 1, embedding_dim),
requires_grad=True)
# 3. Create positional embedding
num_patches = (img_size * img_size) // patch_size**2 # N = HW/P^2
self.positional_embedding = nn.Parameter(torch.randn(1, num_patches+1, embedding_dim))
self.embedding_dropout = nn.Dropout(p=dropout)
self.transformer_encoder_layer = MyDenseBlock(embedding = embedding_dim,n_heads=num_heads,mlp = 4*embedding_dim)
# 7. Create MLP head
self.mlp_head = nn.Sequential(
nn.LayerNorm(normalized_shape=embedding_dim),
nn.Linear(in_features=embedding_dim,
out_features=num_classes)
)
def forward(self, x):
batch_size = x.shape[0]
# Create the patch embedding
x = self.patch_embedding(x)
init_patch = x
# First, expand the class token across the batch size
class_token = self.class_token.expand(batch_size, -1, -1)
# Prepend the class token to the patch embedding
x = torch.cat((class_token, x), dim=1)
# Add the positional embedding to patch embedding with class token
x = self.positional_embedding + x
# Dropout on patch + positional embedding
x = self.embedding_dropout(x)
# Pass embedding through Transformer Encoder stack
for l in range(self.layers):
encoder_feat = self.transformer_encoder_layer(x)
x = encoder_feat[:,1:]+init_patch
x= torch.cat((encoder_feat[:,0].unsqueeze(1),x),dim=1)
# Pass 0th index of x through MLP head
x = self.mlp_head(x[:, 0])
return x