I’m trying to train an simple encoder-decoder translation model, but after 3 to 4 epochs it is overfitting on the token (in this case 3) below are the code reference, can any one help me in understanding what is happening and how to improve the model performance.
Encoder Model
class LSTMEncoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(LSTMEncoder, self).__init__()
self.embed = nn.Embedding(input_size, hidden_size,)
self.rnn_unit = nn.LSTM(hidden_size, hidden_size,
dropout=0.2, num_layers=2, batch_first=True)
self.rnn_unit2 = nn.LSTM(hidden_size, hidden_size,
dropout=0.2, num_layers=2, batch_first=True)
self.batch_norm = nn.BatchNorm1d(hidden_size)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
"""
Args:
x (tensor): _description_
Returns:
out: final output from LSTM
h_n: hidden layer output from LSTM
c_n: context vector of LSTM
"""
x = self.embed(x)
x = relu(x)
out, (h_n, c_n) = self.rnn_unit(x)
out = self.batch_norm(out)
out, (h_n, c_n) = self.rnn_unit2(out)
return out, h_n, c_n
Decoder Model
class LSTMDecoder(nn.Module):
def __init__(self, input_size, hidden_size, target_vocab_size):
super(LSTMDecoder, self).__init__()
self.embed = nn.Embedding(input_size, hidden_size,)
self.rnn_unit = nn.LSTM(hidden_size, hidden_size,
dropout=0.3, num_layers=2, batch_first=True)
self.rnn_unit2 = nn.LSTM(hidden_size, hidden_size,
dropout=0.3, num_layers=2, batch_first=True)
self.final_layer = nn.Linear(hidden_size, target_vocab_size)
self.batch_normal = nn.BatchNorm1d(hidden_size)
self.batch_normal2 = nn.BatchNorm1d(target_vocab_size)
self.drop_out = nn.Dropout(0.5)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, x, h_n, c_n):
x = self.embed(x)
x = relu(x)
out, (h_n, c_n) = self.rnn_unit(x, (h_n, c_n))
# out = self.drop_out(out)
out = self.batch_normal(out)
out, (h_n, c_n) = self.rnn_unit2(out, (h_n, c_n))
out = relu(out)
out = self.final_layer(out)
out = self.batch_normal2(out)
out = self.softmax(out)
return out, h_n, c_n
Batch Training Loop
def __lstm_iter_each_batch__(self, data_point, iter_for='train'):
x = data_point[0]
y = data_point[1]
encoding_h_n = None
encoding_c_n = None
batch_decoder_outputs = torch.ones_like(y) * PAD_TOKEN_INDEX
batch_decoder_outputs[:, 0] = SOS_TOKEN_INDEX
enc_out = torch.ones(LoadAndData.MAX_SENT_LEN, 5) * PAD_TOKEN_INDEX
for e_w in range(0, x.shape[1]):
# Iterating each word and tringing the encoder
en_inp = x[:, e_w]
encoding_out, encoding_h_n, encoding_c_n = self.encoding_model(en_inp)
enc_out[e_w] = encoding_out[0,0]
d_h_n = encoding_h_n
d_c_n = encoding_c_n
d_inp = y[:, 0]
batch_loss = 0
for d_w in range(1, y.shape[1]):
d_out, d_h_n, d_c_n = self.decoding_model(d_inp, d_h_n, d_c_n)
batch_loss += self.loss_fun(d_out, y[:, d_w])
d_inp = y[:, d_w]
topv, topi = d_out.data.topk(1)
batch_decoder_outputs[:, d_w] = topi.squeeze()
if iter_for == 'train':
# Backpropagation
batch_loss.backward()
score = self.calculate_score(y, batch_decoder_outputs)
self._batch_loss = batch_loss
return round(batch_loss.item() / y.shape[1], 30), score
Literally the output after 3 or 4 epochs is as shown below
[[‘0 33 34 35 36 37 38 1’]] → [‘0 1 3 1 1 1 1 1’]
output at starting of 1st epoch
[[‘0 69 70 18 3 3 3 1’]] → [‘0 90 142 172 159 88 159 90’]
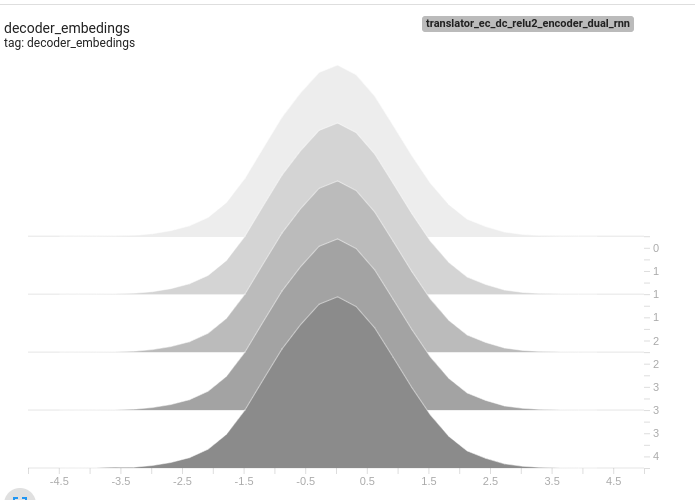
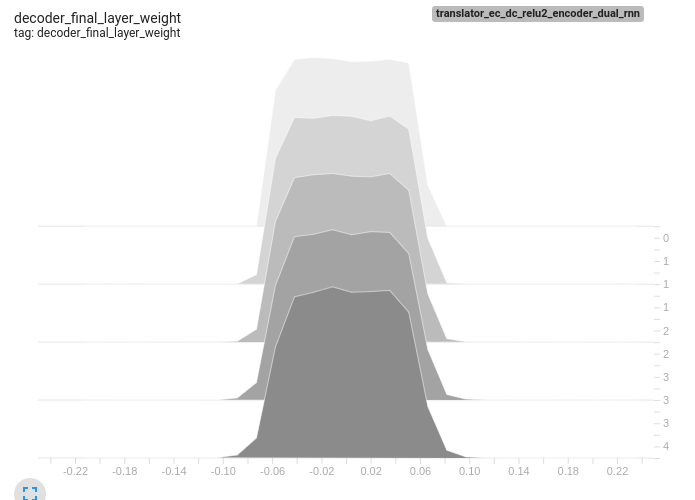
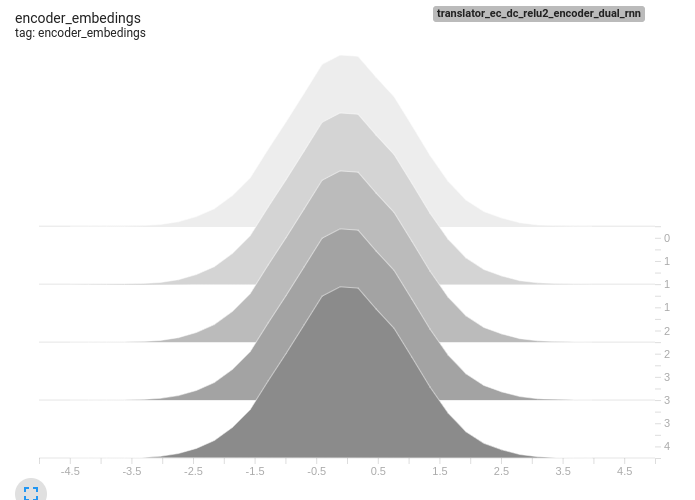
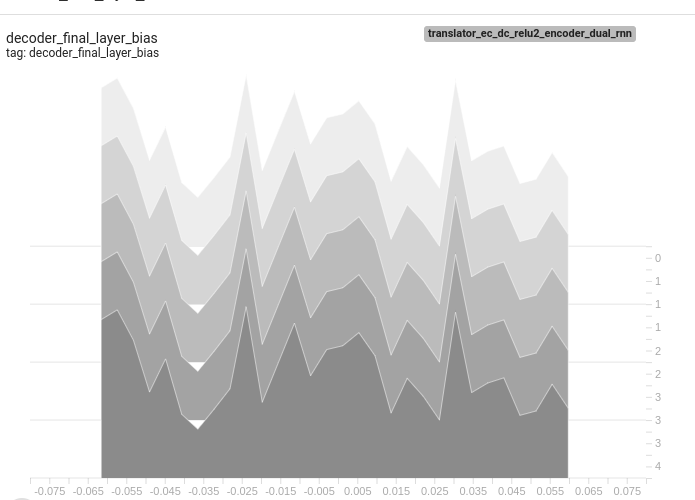
Also attaching few tensor board histograms of weights for better understanding