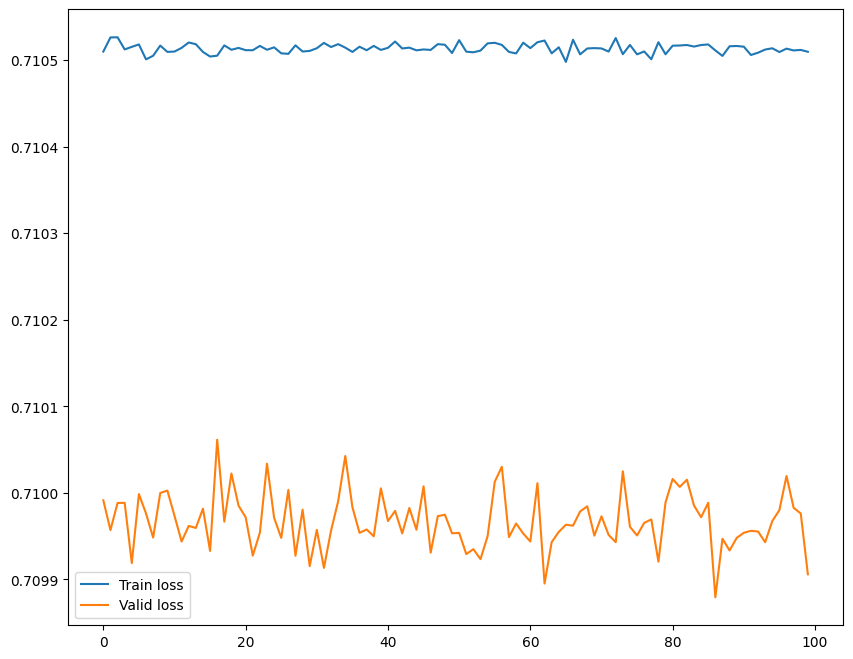
Here is my training loop code:
def train(model, train_dl, valid_dl, loss_fn, optimizer, scheduler, acc_fn, epochs=50):
start = time.time()
model.cuda()
train_loss, valid_loss = [], []
train_acc, valid_acc = [], []
best_acc = 0.0
for epoch in range(epochs):
print('Epoch {}/{}'.format(epoch, epochs - 1))
print('-' * 10)
time_epoch_start = time.time()
for phase in ['train', 'valid']:
if phase == 'train':
model.train(True) # Set trainind mode = true
dataloader = train_dl
else:
model.train(False) # Set model to evaluate mode
dataloader = valid_dl
running_loss = 0.0
running_acc = 0.0
step = 0
for x, y, _ in dataloader:
x = x.cuda()
y = y.cuda()
step += 1
if phase == 'train':
optimizer.zero_grad()
outputs = model(x)
loss = loss_fn(outputs, y)
loss.backward()
optimizer.step()
if scheduler is not None:
scheduler.step()
else:
with torch.no_grad():
outputs = model(x)
loss = loss_fn(outputs, y.long())
acc = acc_fn(outputs, y)
running_acc += acc * dataloader.batch_size
running_loss += loss * dataloader.batch_size
if step % 100 == 0:
print('Current step: {} Loss: {} Acc: {} AllocMem (Mb): {}'.format(step, loss, acc, torch.cuda.memory_allocated()/1024/1024))
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = running_acc / len(dataloader.dataset)
train_loss.append(epoch_loss) if phase=='train' else valid_loss.append(epoch_loss)
train_acc.append(epoch_acc) if phase=='train' else valid_acc.append(epoch_acc)
if phase=='train':
train_loss_print = epoch_loss
train_acc_print = epoch_acc
else:
valid_loss_print = epoch_loss
valid_acc_print = epoch_acc
time_epoch = time.time() - time_epoch_start
print('Epoch {}/{} - TRAIN Loss: {:.4f} TRAIN Acc: {:.4f} - VAL. Loss: {:.4f} VAL. Acc: {:.4f} ({:.4f} seconds - {:.4f} Mb)'.format(epoch, epochs - 1, train_loss_print, train_acc_print, valid_loss_print, valid_acc_print, time_epoch, torch.cuda.memory_allocated()/1024/1024))
time_elapsed = time.time() - start
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
return model, train_loss, valid_loss, train_acc, valid_acc
Here I define the optimizer and learning rate
opt = torch.optim.Adam(modelo.parameters(), lr=hp_lr, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
lr_scheduler = lr_scheduler.StepLR(opt, step_size=10, gamma=0.1)
modelo_trained, train_loss, valid_loss, train_acc, valid_acc = train(modelo, train_dl, valid_dl, loss_fn, opt, lr_scheduler, acc_metric, epochs=num_epochs)
However, when training, here is my training loss