Hi,
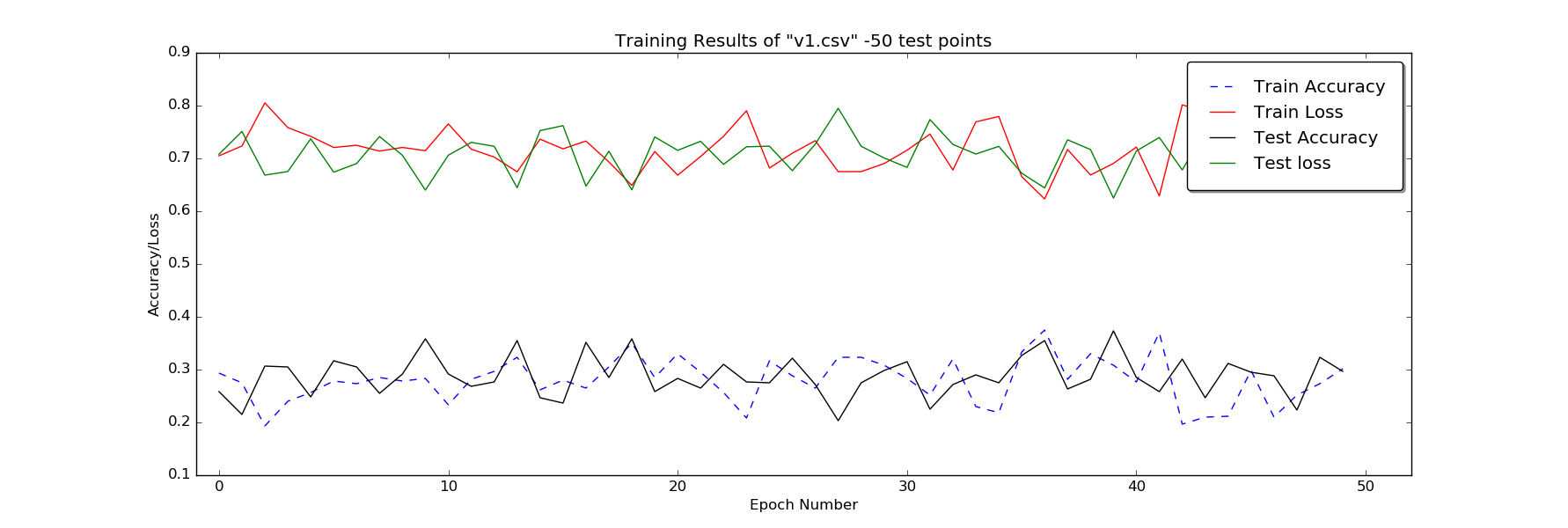
I am using Pytorch for train my model however it is not learning. I have written my own loss function. Can anyone please review the code and the steps I am taking for training? A plot showing loss and accuracy is attached in the end. Thank you.
def train(EPOCHS):
BATCH_SIZE = 5
best_acc = 0.0
train_dataset, train_data_loader, test_dataset, test_data_loader = load_data_set(BATCH_SIZE) # receiving only second parameter
print("Number of train samples: ", len(train_dataset))
print("Number of test samples: ", len(test_dataset))
print("Epoch Train Accuracy TrainLoss Test Accuracy Test Loss")
for epoch in range(EPOCHS):
#print("epoch: ", epoch)
model.train()
train_acc = 0.0
train_loss = 0.0
# 25 random points (x,y) on image for evaluation
points = torch.randint(0, 32, ([100, 2]), dtype=torch.int)
batch_count = 0
for i, (images, gt) in enumerate(train_data_loader):
batch_count += 1
# Move images and labels to gpu if available
if cuda_avail:
images_tensor = Variable(images[0].cuda())
gt_tensor = Variable(gt[0])
# Clear all accumulated gradients
optimizer.zero_grad()
# Predict classes using images from the train set
output_lines = model(images_tensor)
# pdb.set_trace() #TODO need to remove
h_matrix = output_lines.view(len(images_tensor), 25, 3)
gt_no = 0
batch_loss = 0 # calculate loss of every batch
batch_acc = 0 # calculate accuracy of every batch
for hyper_lines in h_matrix: # pick all lines of single image
gt_img = np.array(gt_tensor[gt_no][0]) # select GT w.r.t. selected image
gt_no += 1 # for next GT
image_loss = 0
image_acc = 0
for point in range(points.size()[0]): # pick one test point at a time
x = points[point] # considering 1 point
estimated_value = indicator_functions.estimatedPosition(hyper_lines, x.double())
calculated_value = indicator_functions.calculated_Position(gt_img, x)
loss = (calculated_value - estimated_value) ** 2
# Calculate training loss and training accuracy
image_loss += loss.cpu().item()
if loss.cpu().item() < 0.5:
image_acc += 1.0
# pdb.set_trace() #TODO need to remove
# Compute the average acc and loss over all 25 lines of a single convex image and add in batch loss/acc
batch_loss += image_loss / points.size()[0]
batch_acc += image_acc / points.size()[0]
# pdb.set_trace() #TODO need to remove
train_loss += batch_loss / h_matrix.size()[0]
train_acc += batch_acc / h_matrix.size()[0]
### Making the loss tensor
train_loss_tensor = Variable(torch.tensor(train_loss), requires_grad=True)
# Backpropagate the loss
train_loss_tensor.backward()
# Adjust parameters according to the computed gradients
optimizer.step()
# pdb.set_trace() # TODO need to remove
# Compute the average acc and loss over all 50000 training images
train_loss = train_loss / batch_count
train_acc = train_acc / batch_count
# pdb.set_trace() # TODO need to remove
### Evaluate on the test set
test_acc, test_loss = test(test_data_loader, test_dataset)
### Save the model if the test acc is greater than our current best
if test_acc > best_acc:
save_models(epoch)
best_acc = test_acc
# Print the metrics
print("{} {} {} {} {}".format(epoch, train_acc, train_loss, test_acc, test_loss))
# Backpropagate the loss
train_loss_tensor = Variable(torch.tensor(train_loss), requires_grad=True)
When you are making a Variable, you are removing all gradient information from the tensor, hence you see no training improvement, since it doesn’t know its origins.
Try this code:
a = torch.randn(2, 3, requires_grad=True)
a = a*2
print(a.grad_fn)
# <MulBackward0 object at 0x7f1819cf3518>
a = Variable(a, requires_grad=True)
print(a.grad_fn)
# None
Thanks for reply Krish. Previously I was calculating loss in float variable. I have updated the a part of code such that now loss is a tensor. Here are the details of the loss updates;
Initially I am calculating loss which is a tensor;
The first line of the error suggests that there is a device mismatch. Are you moving the loss to the cpu midway?
And make sure the loss is a result of differentiable functions on the input, else the training won’t work. I don’t know if the indicator_functions are.
Hi Krish,
Thanks for your reply.
Yes, the problem has been slightly solved. Now the model is training but it is not achieving the desired results. This is not related to the model or learning.
As you suggested before, the error was in gradients as they were removing before back tracking. Now, after creating all the torch variable on cuda, the model has started training. Thanks for your help.