Here is my training loop code:
train_loader = torch.utils.data.DataLoader(MeshLoader("./train_mesh/", input_npoints=1024, output_npoints=2048), batch_size=batch_size, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(MeshLoader("./test_mesh/", input_npoints=1024, output_npoints=2048), batch_size=batch_size, num_workers=num_workers)
model = PointNet_Upsample(npoint=1024, up_ratio_per_expansion=2, nstage=1).cuda()#PointNet(up_ratio=2, use_normal=False).cuda()
optimizer = torch.optim.Adam(model.parameters(),lr=0.0001)
count_train = 1
chamferDist = ChamferDistance()
model.train()
loss_array = []
for epoch in range(100):
for step, (input_pt, target_pt) in enumerate(train_loader):
optimizer.zero_grad()
input_pt = input_pt.cuda().float()
target_pt = target_pt.cuda().float()
preds = model(input_pt)
loss = chamferDist(target_pt, preds, bidirectional=True)
print("Epoch", epoch+1, ":", loss.detach().cpu().item()//input_pt.shape[0])
loss.backward()
optimizer.step()
count_train = count_train + input_pt.shape[0]
However, when training, here is my training loss.
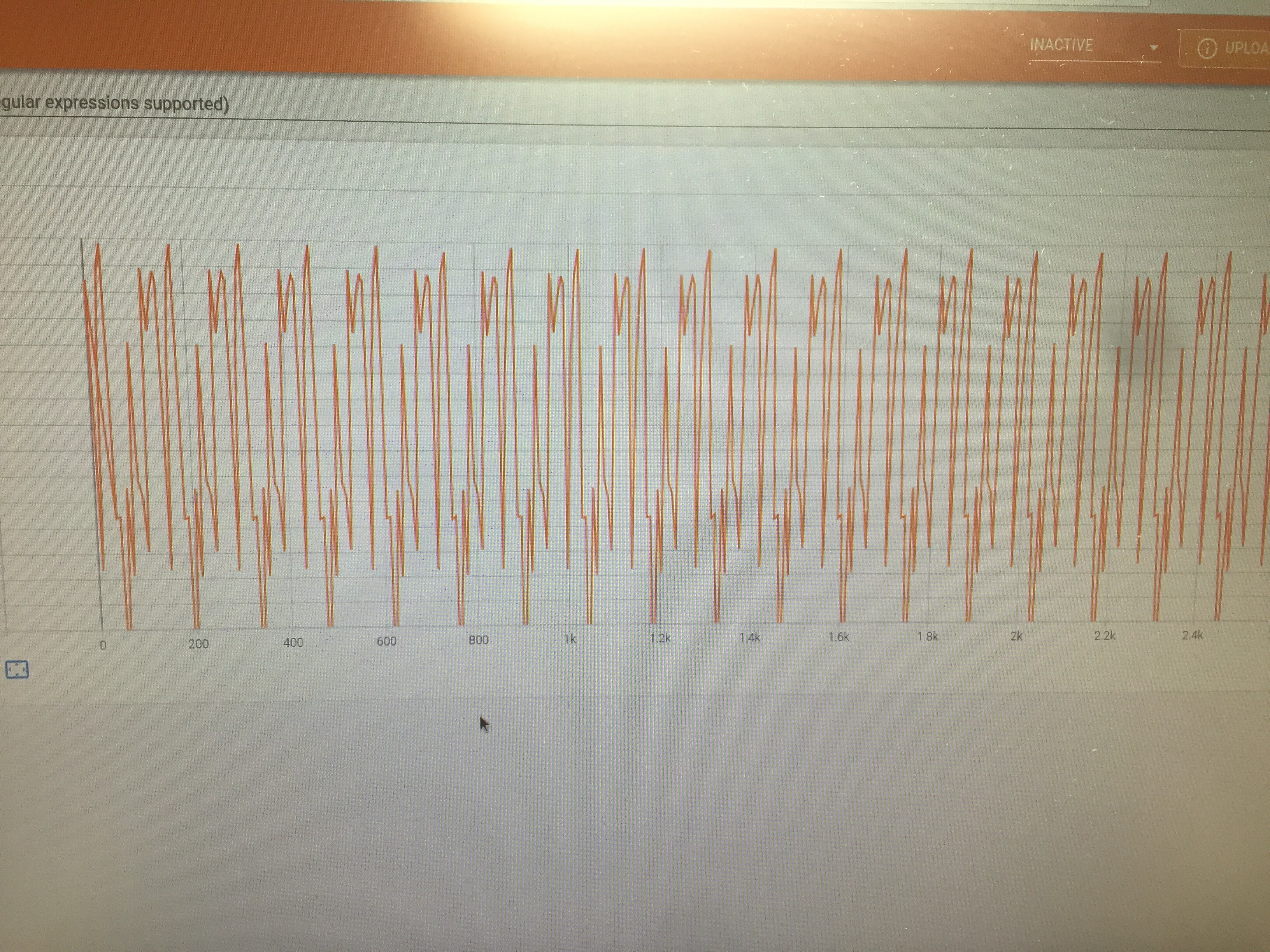
The repeated pattern in loss seems to indicate that the model is not training and that their is an issue with the training loop in particular, because even an incorrect model would still see variance in the loss over time. I am using chamfer’s distance from this repo chamfer’s distance repo link. It returns the sum of the distance between the closest points for each point, and I tried to use it the same way that MSE loss would be used, but it seems like the chamfers distance is not interchangeable. The examples.py in the repo: chamferdist/example.py at master · krrish94/chamferdist · GitHub, seems to indicate that it should be used the same way:
# Backprop using this loss!
cdist.backward()
but, it does not seem to work. Could someone help me with this issue? I have tried many ways to fix this, but the issue still persists, so I was hoping someone here could help me. Thank you!