I am currently using PyTorch for self-supervised optic flow training. The new AMP package is very appealing, as it the model runs faster and can use a larger batch size when using FP16 activations. However, I’ve found that the model does not learn anything.
Here is an ugly image, with FP32 on the left and mixed precision on the right. I used identical hyperparameters, and ran for longer than necessary to prove the point.
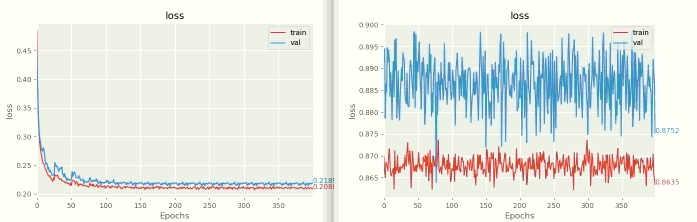
The relevant code was taken straight from the amp example page. Here is the relevant portion copied:
if fp16:
with autocast():
outputs = model(batch)
downsampled_t0, estimated_t0, flows_reshaped = reconstructor(batch, outputs)
loss, loss_components = criterion(batch, downsampled_t0, estimated_t0, flows_reshaped)
else:
outputs = model(batch)
downsampled_t0, estimated_t0, flows_reshaped = reconstructor(batch, outputs)
loss, loss_components = criterion(batch, downsampled_t0, estimated_t0, flows_reshaped)
# zero the parameter gradients
optimizer.zero_grad()
# calculate gradients
if fp16:
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
loss.backward()
# step in direction of gradients according to optimizer
optimizer.step()
Things that could be causing the issue
- Using a multi-part loss function. I have multiple image reconstruction losses and a smoothness loss, common in optic flow tasks. The AMP page tells us to scale components of our loss function individually. However, this seems to make little sense to me. The relevant portions of my loss function have been carefully scaled by prior work and my own work, so scaling them individually seems like it would ruin that. Furthermore, having a backwards pass for each component of my loss function would take much longer.
- Spatial transformer networks. I sample from the image at time t+1 to estimate the image at time t using torch.nn.functional.grid_sample. Does this operation not work with mixed precision training?
- Just a bug in torch somewhere (I can open a GitHub issue if so)
Debug info:
- pytorch version: 1.7.0a0+eb47940
- cuda: 11