Before posting a query, check the FAQs - it might already be answered!
Hi I am trying to create a Encoder -Decoder Model with No attention involved and I have trained the data on 15 epochs the Loss doesn’t converge right from the 1st epoch to the last epoch What mistake I might be making For Ref. I am attaching my code
class EncoderLSTM(nn.Module):
def init(self,input_size,hidden_size,dropout_p=0.5):
super(EncoderLSTM,self).init()
self.hidden_size=hidden_size
self.embedding=nn.Embedding(input_size,hidden_size,device=device)
self.LSTM=nn.LSTM(hidden_size,hidden_size,num_layers=2,batch_first=True)
self.dropout=nn.Dropout(dropout_p)
def forward(self,input):
embedding=self.dropout(self.embedding(input))
#print(embedding.shape)
out,(hide,cs)=self.LSTM(embedding)
return out,(hide,cs)
def predict(self,input):
z1=vocab.lookup_indices(input.split(’ ‘))
z1.insert(0,vocab[’‘])
z1.append(vocab[’'])
out,(hide,cs)=EncoderLSTM.forward(self,input=torch.tensor(z1).view(1,len(z1)).to(device))
return out,(hide,cs)
class DecoderLSTM(nn.Module):
def init(self,hidden_size,output_size,encoder):
super(DecoderLSTM,self).init()
self.Embedding=nn.Embedding(output_size,hidden_size)
self.LSTM=nn.LSTM(hidden_size,hidden_size,num_layers=2,batch_first=True)
self.out1=nn.Linear(hidden_size,output_size3)
self.out2=nn.Linear(output_size3,output_size)
self.grelu=nn.GELU()
self.relu=nn.ReLU()
self.encoder=encoder
def forward(self,encoder_output,encoder_hidden,target_tensor=None):
batch_size=encoder_output.size(0)
decoder_input=torch.empty(batch_size,1,dtype=torch.long,device=device).fill_(sos_tensor)
decoder_hidden=encoder_hidden
decoder_outputs=
for i in range(8):
decoder_output,decoder_hidden=self.forward_step(decoder_input,decoder_hidden)
decoder_outputs.append(decoder_output)
if target_tensor is not None:
#print(target_tensor[:,i].shape)
decoder_input=target_tensor[:,i].unsqueeze(1)
#print(decoder_input.shape)
else:
,topi=decoder_output.topk(1)
decoder_input=topi.squeeze(-1).detach()
decoder_outputs=torch.cat(decoder_outputs,dim=1)
return decoder_outputs,decoder_hidden,None
def forward_step(self,input,hidden):
output=self.Embedding(input)
output,(hidden_new,cell_state_new)=self.LSTM(output,hidden)
output=self.grelu(self.out1(output))
output=self.relu(self.out2(output))
return output,(self.grelu(hidden_new),self.grelu(cell_state_new))
def predict(self,encoderpredict):
encoder_output,encoder_hidden=encoderpredict
d_o,d_h,=DecoderLSTM.forward(self,encoder_output,encoder_hidden,None)
z=torch.argmax(d_o,dim=2)
z=z.view(-1,z.shape[1])
z=z.tolist()
z1=vocab.lookup_tokens(z[0])
return z1
encoder=EncoderLSTM(256,128)
encoder_optimizer=torch.optim.Adam(encoder.parameters(),1e-3,weight_decay=0.09)
encoder.to(device)
decoder=DecoderLSTM(128,len(vocab),encoder)
loss_fn_decoder=torch.nn.CrossEntropyLoss()
decoder_optimizer=torch.optim.Adam(decoder.parameters(),learning_rate,weight_decay=0.09)
decoder.to(device)
for i in range(epochs):
encoder.train()
decoder.train()
train_loss=0
for batch in tqdm(train_dataloader,desc=‘Training’):
data,labels=batch
decoder_optimizer.zero_grad()
encoder_optimizer.zero_grad() data.to(device)
output_encoder,hidden_encoder=encoder(data.to(device))
output_decoder,hidden,none=decoder(encoder_output=output_encoder.to(device),encoder_hidden=hidden_encoder,target_tensor=labels.to(device))
loss=loss_fn_decoder(output_decoder.view(-1,output_decoder.shape[-1]).to(device),labels.view(-1).to(device))
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
train_loss+=loss
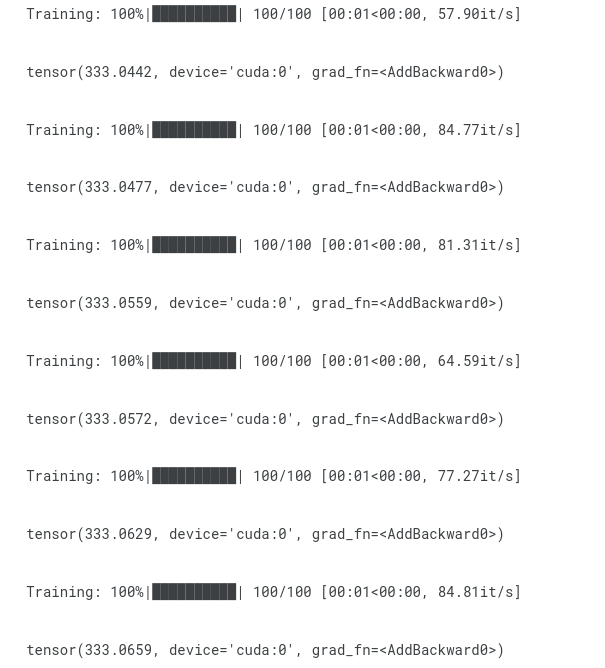
print(train_loss)
!
the next Image is for the Loss