Hi,
My data is in the shape of (11423, 2, 10, 34). I am dealing with sports data, where each instance is a matchup of two teams, with 10 players each, and 34 stats per player. I have data from 11423 matchups.
I want to use a 1D convolutional filter that is 10x1, to slide to the right across the 34 statistics for all 10 players on the two channels.
My target variable is the point differential for the game.
Here is what I have so far:
# Split up data - training set and testing set
X_train, X_test, y_train, y_test = train_test_split(matchup_features, targets, test_size=0.2)
print("X_train shape:", X_train.shape,
"\nX_test shape:", X_test.shape,
"\ny_test shape:", y_train.shape,
"\ny_train shape:", y_test.shape)

class PlayerBoxScoreMatchupsDataset(Dataset):
def __init__(self, matchup_features, targets):
self.targets = targets
self.matchup_data = matchup_features
def __len__(self):
return len(self.matchup_data)
def __getitem__(self, index):
X = self.matchup_data[index]
y = self.targets[index]
return X, y
# Create DataSet and DataLoaders
training_set = PlayerBoxScoreMatchupsDataset(X_train, y_train)
validation_set = PlayerBoxScoreMatchupsDataset(X_test, y_test)
train_loader = DataLoader(training_set, batch_size=100, shuffle=False)
val_loader = DataLoader(validation_set, batch_size=100, shuffle=False)
print(training_set[0][0].shape, training_set[0][1])
![]()
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv1d(2, 2, kernel_size=(10,1), stride=1)
self.fc1 = nn.Linear(68, 64)
self.fc2 = nn.Linear(64, 16)
self.fc3 = nn.Linear(16, 1)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
x = F.relu(self.conv1(x))
# print("shape after conv1:", x.shape)
x = x.reshape(-1, 68)
x = self.dropout(x)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
net = Net()
print(net)
import torch.optim as optim
net = Net()
loss_function = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=0.03)
epochs = 30
for e in range(epochs):
train_loss = 0
val_loss = 0
net.train()
for data, target in train_loader:
optimizer.zero_grad()
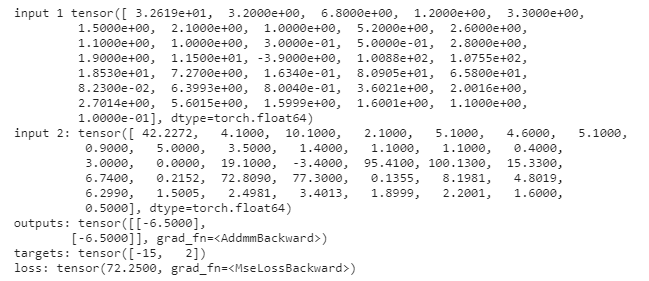
output = net(data.float())
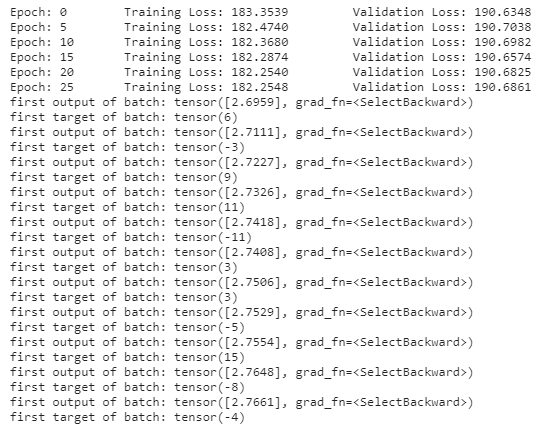
if e == 29:
print("first output of batch:", output[0])
print("first target of batch:", target[0])
loss = loss_function(output, target.float())
loss.backward()
optimizer.step()
train_loss += loss.item() * data.size(0)
net.eval()
for data, target in val_loader:
output = net(data.float())
loss = loss_function(output, target.float())
val_loss += loss.item()*data.size(0)
train_loss = train_loss / len(train_loader.sampler)
val_loss = val_loss / len(val_loader.sampler)
print('Epoch: {} \tTraining Loss: {:.4f} \tValidation Loss: {:.4f}'.format(
e, train_loss, val_loss))

As you can see, the model barely learns, and worse, it predicts about the same thing for every example (even in the training set! - about 2.7, even if that is no where near the actual target).
I’ve tried adjusting the learning rate, and it did not change anything. I’m thinking something may be wrong with the
conv1d(2, 2, kernel_size=(10,1), stride=1) part because that part is most hazy to me.
What mistake am I making? Thanks for your help!