Hi guys,
I have a huge dataset of about 500GB, and since all of that cannot be fit into the RAM, I have written DataLoader for train and test sets in such a way that it brings 10 files of training data into memory, trains on those ten files and brings the next 10 train files, trains on those 10 files and so on.After the training is complete the same thing happens with test files where 10 files are tested at a time…
Here’s the code for that
for epoch in tqdm(range(num_epochs)):
model.train()
loss_list_train = []
loss_list_test = []
total_train = 0
equals_train = 0
total_test = 0
num0_train = 0
num1_train = 0
num0_test = 0
num1_test = 0
equals_test = 0
TP_train = 0
FP_train = 0
TN_train = 0
FN_train = 0
TP_test = 0
FP_test = 0
TN_test = 0
FN_test = 0
for k in tqdm(range(0,len(train_ind),10)):
list_of_datasets_train_data = np.array([[0]*300])
list_of_datasets_train_labels=np.array([0])
for z in range(k,k+10):
if k<len(train_ind):
datum,labelss=training_set[z]
list_of_datasets_train_data=np.append(list_of_datasets_train_data,datum,axis=0)
list_of_datasets_train_labels=np.append(list_of_datasets_train_labels,labelss,axis=0)
else:
break
list_of_datasets_train_data=np.delete(list_of_datasets_train_data,0,axis=0)
list_of_datasets_train_labels=np.delete(list_of_datasets_train_labels,0,axis=0)
list_of_datasets_train_data=list_of_datasets_train_data.reshape(-1,WINDOW+1,1)
list_of_datasets_train_labels=list_of_datasets_train_labels.reshape(-1,1)
trainz = torch.utils.data.TensorDataset(torch.from_numpy(list_of_datasets_train_data), torch.from_numpy(list_of_datasets_train_labels))
train_loader = torch.utils.data.DataLoader(trainz, batch_size = batch_size, shuffle = True)
# Train
# for i, (inputs, targets) in enumerate(train_loader):
for i, (inputs, targets) in enumerate(train_loader):
train = Variable(inputs.type(torch.FloatTensor).cuda())
targets = Variable(targets.type(torch.FloatTensor).cuda())
optimizer.zero_grad()
outputs = model(train)
loss = error(outputs, targets)
loss_list_train.append(loss.item())
loss.backward()
# loss.backward(retain_graph=True)
optimizer.step()
t = np.where(targets.cpu().detach().numpy() > 0.5, 1, 0)
o = np.where(outputs.cpu().detach().numpy() > 0.5, 1, 0)
total_train += t.shape[0]
equals_train += np.sum(t == o)
num0_train += np.sum(t == 0)
num1_train += np.sum(t == 1)
TP_train += np.sum(np.logical_and(t == 1, o==1))
FP_train += np.sum(np.logical_and(t == 1, o==0))
TN_train += np.sum(np.logical_and(t == 0, o==0))
FN_train += np.sum(np.logical_and(t == 0, o==1))
tb.save_value('Train Loss', 'train_loss', globaliter, loss.item())
globaliter += 1
tb.flush_line('train_loss')
print(i)
# Test
model.eval()
for k in tqdm(range(0,len(test_ind),10)):
list_of_datasets_test_data = np.array([[0]*300])
list_of_datasets_test_labels=np.array([0])
for z in range(k,k+10):
if k<len(test_ind):
datum,labelss=testing_set[z]
list_of_datasets_test_data=np.append(list_of_datasets_test_data,datum,axis=0)
list_of_datasets_test_labels=np.append(list_of_datasets_test_labels,labelss,axis=0)
else:
break
list_of_datasets_test_data=np.delete(list_of_datasets_test_data,0,axis=0)
list_of_datasets_test_labels=np.delete(list_of_datasets_test_labels,0,axis=0)
list_of_datasets_test_data=list_of_datasets_test_data.reshape(-1,WINDOW+1,1)
list_of_datasets_test_labels=list_of_datasets_test_labels.reshape(-1,1)
testz = torch.utils.data.TensorDataset(torch.from_numpy(list_of_datasets_test_data) , torch.from_numpy(list_of_datasets_test_labels))
test_loader = torch.utils.data.DataLoader(testz , batch_size = batch_size, shuffle = False)
for inputs, targets in test_loader:
inputs = Variable(inputs.type(torch.FloatTensor).cuda())
targets = Variable(targets.type(torch.FloatTensor).cuda())
outputs = model(inputs)
loss = error(outputs, targets)
loss_list_test.append(loss.item())
#print(outputs.cpu().detach().numpy())
t = np.where(targets.cpu().detach().numpy() > 0.5, 1, 0)
o = np.where(outputs.cpu().detach().numpy() > 0.5, 1, 0)
total_test += t.shape[0]
equals_test += np.sum(t == o)
num0_test += np.sum(t == 0)
num1_test += np.sum(t == 1)
TP_test += np.sum(np.logical_and(t == 1, o==1))
FP_test += np.sum(np.logical_and(t == 0, o==1))
TN_test += np.sum(np.logical_and(t == 0, o==0))
FN_test += np.sum(np.logical_and(t == 1, o==0))
tb.save_value('Test Loss', 'test_loss', globaliter2, loss.item())
globaliter2 += 1
tb.flush_line('test_loss')
print("------------------------------")
print("Epoch : ", epoch)
print("----- Train -----")
print("Total =", total_train, " | Num 0 =", num0_train, " | Num 1 =", num1_train)
print("Equals =", equals_train)
print("Accuracy =", (equals_train / total_train)*100, "%")
# print("TP =", TP_train / total_train, "% | TN =", TN_train / total_train, "% | FP =", FP_train / total_train, "% | FN =", FN_train / total_train, "%")
print("----- Test -----")
print("Total =", total_test, " | Num 0 =", num0_test, " | Num 1 =", num1_test)
print("Equals =", equals_test)
print("Accuracy =", (equals_test / total_test)*100, "%")
# print("TP =", TP_test / total_test, "% | TN =", TN_test / total_test, "% | FP =", FP_test / total_test, "% | FN =", FN_test / total_test, "%")
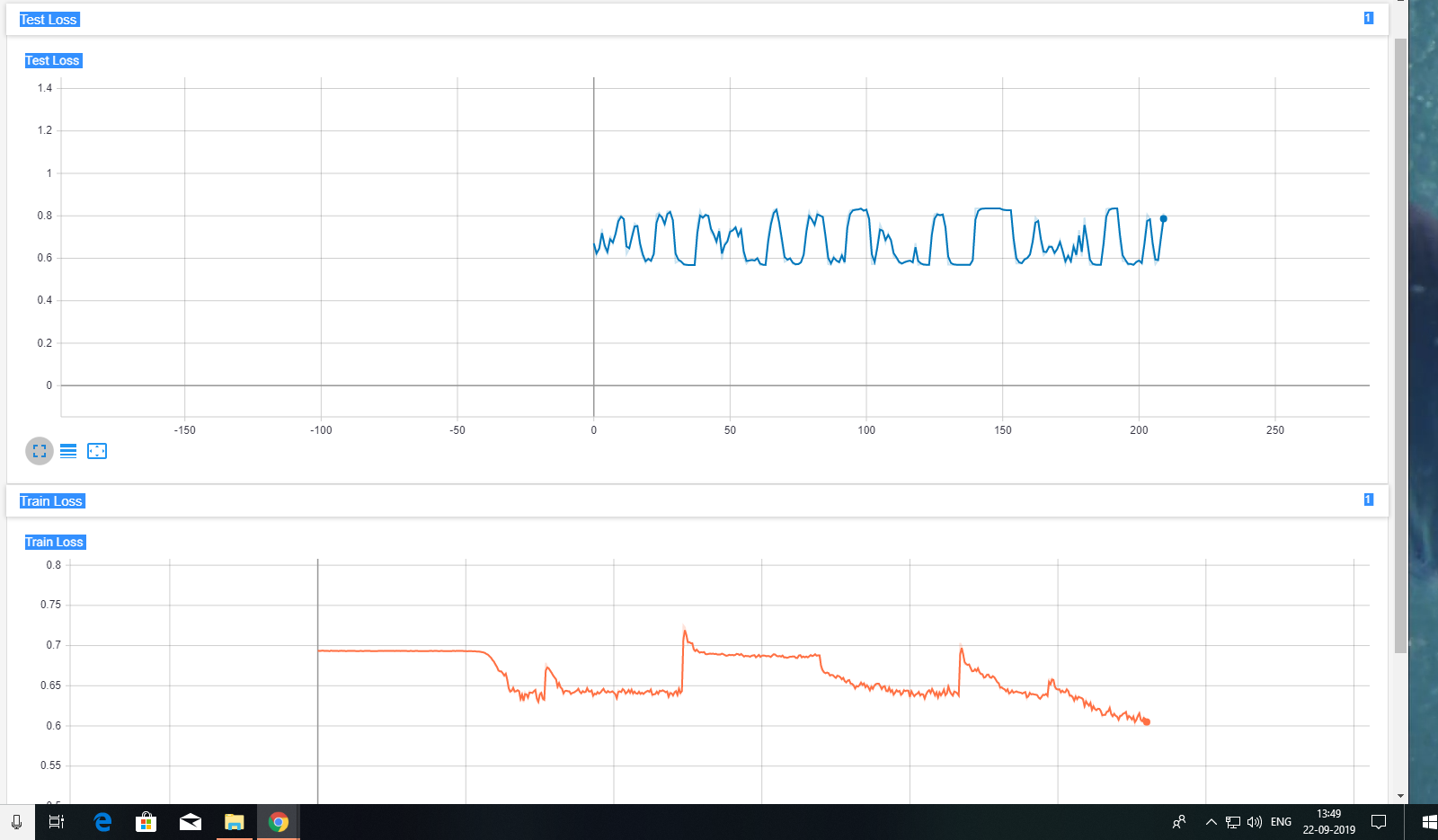
Here’s the problem when I train the LSTM model with a limited no. of files the train loss keeps on decreasing until it flattens, but with this approach every time the next 10 files are loaded into the DataLoader, the error bumps up. The Test loss also does not seem to decrease over time even though test accuracy increases with time.
Is something wrong with this approach??
What is causing the weird behavior of the train and test accuracy??
Here’s a Picture depicting train and test losses over time
Edit-Typos