I’ve created a model which takes as input a (tokenized) sequence of length n and predicts a sequence of 0-1 probabilities for each of the n tokens. e.g. [0.0, 0.0, 0.3, 0.72, … , 0.0]. The model is set up to take the output of a pretrained BERT model (size of [batch_sz, 1024, sequence_len]) and feed its output into a group of fully connected layers as such:
class MyModel(nn.Module):
def __init__(self, bert_model):
super(MyModel, self).__init__()
self.bert_model = bert_model
self.linear_1 = nn.Linear(1024, 512)
self.linear_2 = nn.Linear(512, 128)
self.linear_3 = nn.Linear(128, 64)
self.linear_4 = nn.Linear(64, 1)
def forward(self, input_ids, attn_mask):
x = F.relu(self.bert_model(input_ids, attention_mask=attn_mask).last_hidden_state)
x = F.relu(self.linear_1(x))
x = F.relu(self.linear_2(x))
x = F.relu(self.linear_3(x))
x = torch.flatten(torch.sigmoid(self.linear_4(x)))
return x
What I’m finding, however is when evaluating, all outputs for the sequences are the same value with very slight differences. The model does in fact learn, and it does so rather quickly, but also quickly converges to these type of predictions:
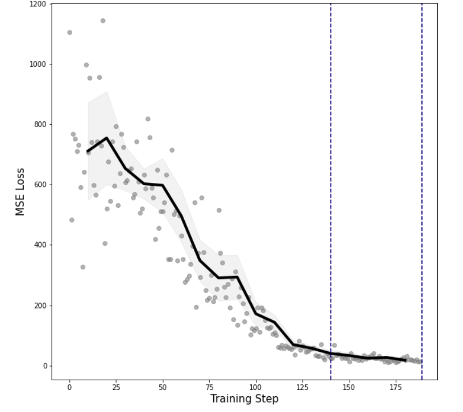
This trend continues long after step 175 shown in the above image. When evaluating (every 5000 steps on a test dataset) on a dataset of 1000 unique sequences, varying lengths (around ~500) on average we see that the model has learned to predict a single value for every position in the output (e.g. [0.07, 0.07, … ,0.07]) for every sequence evaluated:
trianing_steps, maximum_prediction, minimum_prediction, difference
5000 0.078548 0.078548 8.94E-08
10000 0.079725 0.079725 7.45E-08
15000 0.082846 0.082846 7.45E-08
20000 0.082651 0.082651 7.45E-08
25000 0.067803 0.067803 3.73E-08
Examining the predictions in the training loop, we can see that this phenomenon occurs even in the training dataset. It’s not always the case, as predictions in the beginning of the training loop do in fact differ (by up to 50% in some cases), but converge to all being nearly identical as time goes on. This leads me to believe that the data processing is correct and the issue is either in the way I’m using the loss function, or in the way the model is set up. The training loop is written as follows:
protbert_model = BertModel.from_pretrained(model_name)
model = MyModel(protbert_model)
model.to(device)
mask_domains = True
optimizer = AdamW(model.parameters(), lr = 0.00001)
loss_fct = nn.MSELoss(reduction="sum")
model.train()
for step, batch in enumerate(train_data_loader):
labels = torch.from_numpy(np.asarray(batch["labels"], dtype=np.float32)).cuda()
inputs = batch["input_ids"].cuda()
attn_mask = batch["attention_mask"].cuda()
outputs = model(inputs, attn_mask).cuda()
# create mask to exclude the padding tokens in loss calculation
# making the outputs and labels 0 shouldn't affect loss value
# due to reduction = "sum"
loss_mask = torch.where(labels == -100.0, 0, 1).cuda()
# apply the mask for padding tokens
labels = torch.mul(labels, loss_mask)
outputs = torch.mul(outputs, loss_mask)
#creating mask to exclude additional tokens we don't want in our calculation
if mask_domains:
domains = np.asarray(batch["domains"])
# making the outputs and labels 0 shouldn't affect loss value
# due to reduction = "sum"
domains_mask = np.where(domains == -1, 0, 1)
domains_mask = torch.from_numpy(domains_mask).cuda()
labels = torch.mul(labels, domains_mask)
outputs = torch.mul(outputs, domains_mask)
loss = loss_fct(outputs, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
As of now I’m using a batch size of just 1. It also should be noted that even after applying the masks in the loss function, my data is quite imbalanced with most of the labels being 0.0 (histogram). When excluding the values that are 0.0, there is a solid range in the labels (histogram)
{kind=link}
Any help or advice you all have is greatly appreciated. Thanks