Hi there,
I am building a feedforward network for a binary text classification task. Here’s my model:
def __init__(self, output_size, embedding_dim, hidden_size, dropout=0.2):
super(FeedForward, self).__init__()
self.embedding = nn.Embedding.from_pretrained(embedding_matrix)
self.linear_relu_stack = nn.Sequential(
nn.Linear(in_features=embedding_dim, out_features=hidden_size),
nn.ReLU(),
nn.Dropout(p=dropout),
nn.Linear(in_features=hidden_size, out_features=hidden_size//2),
nn.ReLU(),
nn.Dropout(p=dropout),
nn.Linear(in_features=hidden_size//2, out_features=output_size),
nn.Sigmoid()
)
def forward(self, input):
emb = self.embedding(input)
emb = torch.sum(emb, dim=1)
out = self.linear_relu_stack(emb)
return out
model = FeedForward(OUTPUT_SIZE, EMBEDDINGS_DIM, HIDDEN_SIZE, 0.5).to(device)
print(model)
OUTPUT:
(embedding): Embedding(204775, 300)
(linear_relu_stack): Sequential(
(0): Linear(in_features=300, out_features=512, bias=True)
(1): ReLU()
(2): Dropout(p=0.4, inplace=False)
(3): Linear(in_features=512, out_features=256, bias=True)
(4): ReLU()
(5): Dropout(p=0.4, inplace=False)
(6): Linear(in_features=256, out_features=1, bias=True)
(7): Sigmoid()
)
)
I am training using 64-batch. I have 1,276,686 rows in train set and 159,586 rows in validation set. I am using FastText word embeddings, and use loss_function = nn.BCELoss() and
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-7).
Now, the problem is that my model tends to overfit quickly after a few epochs. I have tried training in shuffled mini-batches, decreasing the complexity of the model, add stronger dropout and higher weight decay. But no matter what I do, the model will always overfit once the training accuracy gets to around 81% and the validation loss will go up. The model will not improve and go any further than 81% on validation data. How should I approach this issue?
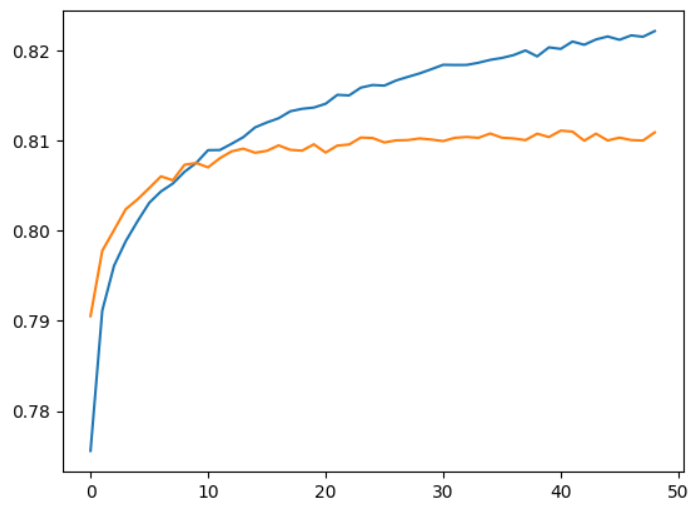
Here is my training graph of loss: (validation is orange, train is blue)
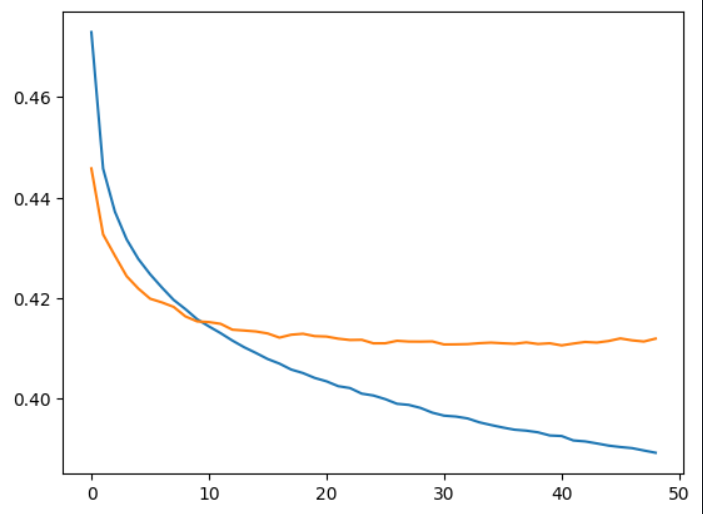
And accuracy: