Hi,
I’m facing an overfitting problem, my model get very high accuracy on the training set ~99.8% accuracy
while on the validation set i’m getting worse result ~41% accuracy.
I tried adding more data (30K more images to the training set and validation set) and tried also data augmentation but the model just not improving on the validation set.
Thanks for your reply.
I added Dropout just before the last fc layer which didn’t help much, i’m training resnet50 on my dataset, my dataset contains images 600x600 of jewellery images.
data augmentation didn’t help and plus adding more data didn’t help.
i made sure that i’m using the same preprocessing on my training and my validation images.
not sure what else can i do, and why it’s not converging on my validation set
Look like sth wrong is in your pipeline. If you have > 50k images, over-fitting with Dropout should not be a big problem.
Try pretrained model and learn just last layer (so dont optimize rest of them, just pass model.fc.parameters() to optimizer)
If this also doesn’t help, maybe make again random split between training and validation images (maybe distribution of images in this two sets is too different)
Last part is training without Data-Augmentation, maybe turn it off and see what will happend.
Do you get these bad results for the validation set from the beginning or is it improving a bit?
Could you post your Datasets with all pre-processing code?
How was the data split into training and validation? Was it a random split or was some logic involved?
i get these bad result after a few epochs when the training accuracy becomes ~78%
the data was randomly split into training and validation using sklearn.model_selection.train_test_split method.
This is my Dataset's code with all the pre processing:
Before the training accuracy reaches ~78% the validation accuracy is rising?
Are the validation predictions biased towards some classes the whole time?
The code looks fine, as long as the normalization is performed in the same way for the training and validation data.
Could you check the data stats (mean, std, min, max) for some samples taken from both DataLoaders?
Yup, the validation accuracy is rising and then it starting to drop giving me huge loss.
at the beginning when the validation accuracy rising the predictions are spread on the whole classes but when
the training accuracy rises the validation predictions are biased towards 1-2 classes (not the same class every epoch - for example in epoch 12 the validation predictions are biased towards classes 1 and 2, and on epoch 13 they are biased towards classes 3 and 7)
I checked my data stats, mean, std, min and max and the training stats are very similar to the validation stats that’s why i’m worried.
I even tried to do inference on my training set and it gave me bad results.
i’m training some of the batchnorm layers in resnet50 but my batch size isn’t small, maybe it has something to do with this?
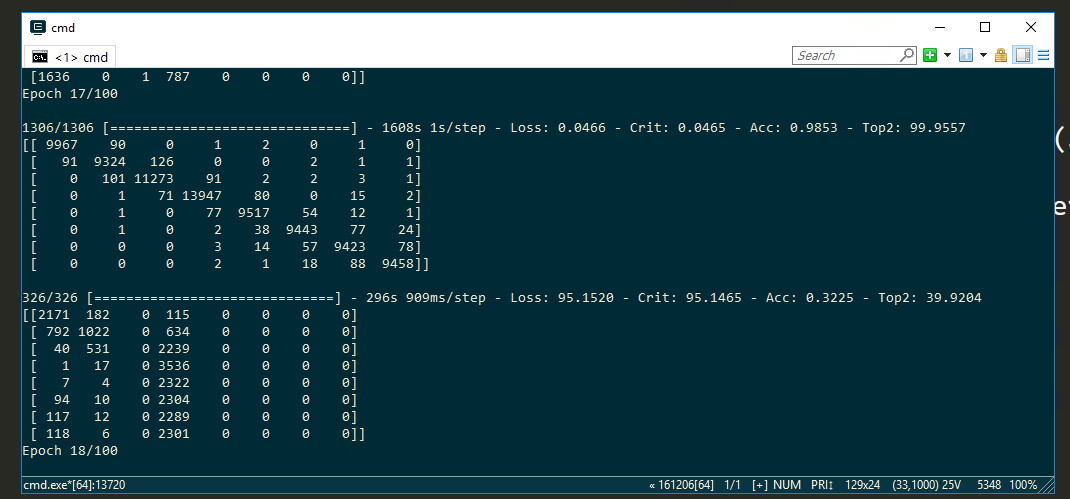
Based on the screenshot you shared, your training accuracy and confusion matrix looks good.
What do you mean by “tried to do inference on my training set and it gave me bad results”?
Did you switch to eval and the results were also bad on the training set?
If your batch size isn’t small, it’s not problematic to use BatchNorm layers. The opposite could be problematic.
i switched the model to eval() and used my train data loader to test the model on the training set to see if my problem is occurring on the training set also (got bad results on my training set) - which it did so i guess it’s not a normalization problem (which i thought at the beginning)
i’m using batch_size=64 for the training and for the eval phase
I even made sure that the layers weights are not updating in the eval mode.
i did not make any change in the BatchNorm layers.
I tried freezing all the BatchNorm layers and train the model - same results
I even tried to freeze the BatchNorm layers and do a transfer learning - same results
I have same problem, and freezing the BN does not change anything.
I am doing a simple classification task in medical imaging area. I have a dataset about 50k images and 4 class. The model overfitting a lot (below are the training for 4 epochs)
Validation accuracy before training is 0.28779987373737376
Epoch: 0
Training accuracy: 0.7547950186346696, Validation accuracy: 0.4102746212121212
Training loss: 0.5928439186062924, Validation loss: 1.9086839990182356
Epoch: 1
Training accuracy: 0.9022588855558585, Validation accuracy: 0.38691603535353536
Training loss: 0.25842620344117806, Validation loss: 2.5381281658856554
Epoch: 2
Training accuracy: 0.939960003636033, Validation accuracy: 0.36900252525252525
Training loss: 0.16145963321418264, Validation loss: 2.9992803214776393
so basically after the first iteration, it is overfitting. What should I do? I have tried everything I know from dropout, augmentation, increasing dataset, using WeightedSampler, weight decay.
I really do not understand how after the first epoch it is overfitting heavily. I have tested models from MobileNet to Inception. Nothing works.
Using more data should improve the ability to generalize. I would start by checking e.g. the preprocessing pipeline and make sure that e.g. the normalization is applied in the training and validation use case. A quick test might be to use the training dataset in the validation loop and check it’s performance.
I’m unsure if the model is only overfitting after the first epoch, since epoch0 already shows a worse validation accuracy than the training one.
I have tested this one, and accuracy for testing training dataset is near 90%, so I can say everything is fine regarding the preprocessing methods.
I really do not get how the model is acting like this. If it is not overfitting, what is happnening here? Any suggestion for improving this case?
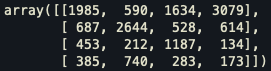
Also when I plot the confusion matrix, I see that most of the data are biased toward first class. What should I do for removing this bias? Add weight balancing to loss or try OnevsRest?