I defined a sentiment analysis model using lstm i usually do it with torchtext this this time i wanted to try it without. I used glove as embeddings and a 2 layers LSTM connected with a fc layer.
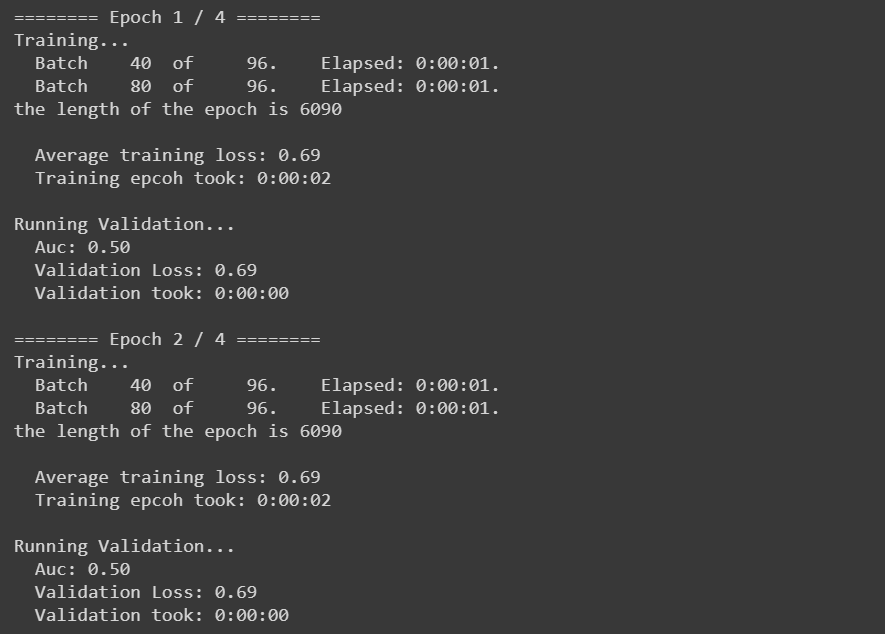
My problem is even if my gradients are changing the loss doesn’t change and I don’t understand why?
Model below:
glove_mat is a matrix with size vocabulary*300(size of an embedding)
Thanks for your help. I managed to make the network work by changing the optimizer i was using a SGD but the loss was not changing when i switched to an Adam optimizer after 10 epochs the loss start decreasing.
final_optimizer = optim.Adam(model.parameters(),
lr =LEARNING_RATE, # args.learning_rate - default is 5e-5, our notebook had 2e-5
eps = 1e-8 # args.adam_epsilon - default is 1e-8.
)
initial_optimizer = optim.SGD(model.parameters(), lr=1e-3, weight_decay=1e-6)
I still don’t understand the problem with SGD as SGD’s fluctuation, on the one hand, enables it to jump to new and potentially better local minima.