I want to serve the model in multi thread, but it hangs the gpu and there is no error log.
Is the model’s forwarding thread-safe ?
This is my envs:
PyTorch version: 1.0.1.post2
Is debug build: No
CUDA used to build PyTorch: 10.0.130OS: Ubuntu 16.04.5 LTS
GCC version: (Ubuntu 5.4.0-6ubuntu1~16.04.11) 5.4.0 20160609
CMake version: version 3.5.1Python version: 3.5
Is CUDA available: Yes
CUDA runtime version: 10.0.130
GPU models and configuration: GPU 0: GeForce RTX 2080
Nvidia driver version: 410.79
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.4.1
and the sample code :
from concurrent.futures import ThreadPoolExecutor
from itertools import repeat
import numpy as np
import torch
from torchvision import models
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
def task(model):
num_tasks = 100
for i in range(num_tasks):
input_tensor = torch.ones([16, 3, 224, 224], dtype=torch.float32)
with torch.no_grad():
input_tensor = input_tensor.to(device)
model(input_tensor)
vgg16 = models.vgg16(pretrained=False)
vgg16.eval()
vgg16.to(device)
num_workers = 16
with ThreadPoolExecutor(max_workers=16) as pool:
results = pool.map(task, repeat(vgg16, num_workers))
print(len(list(results)))
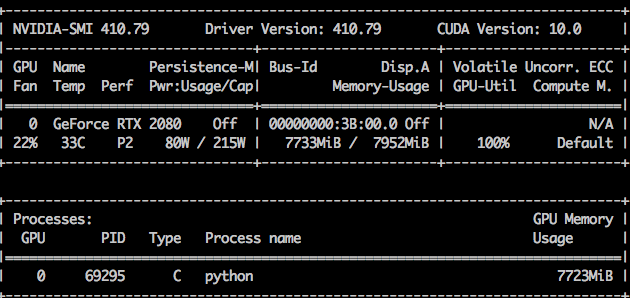
and nvidia-smi’s output is:
 .
.