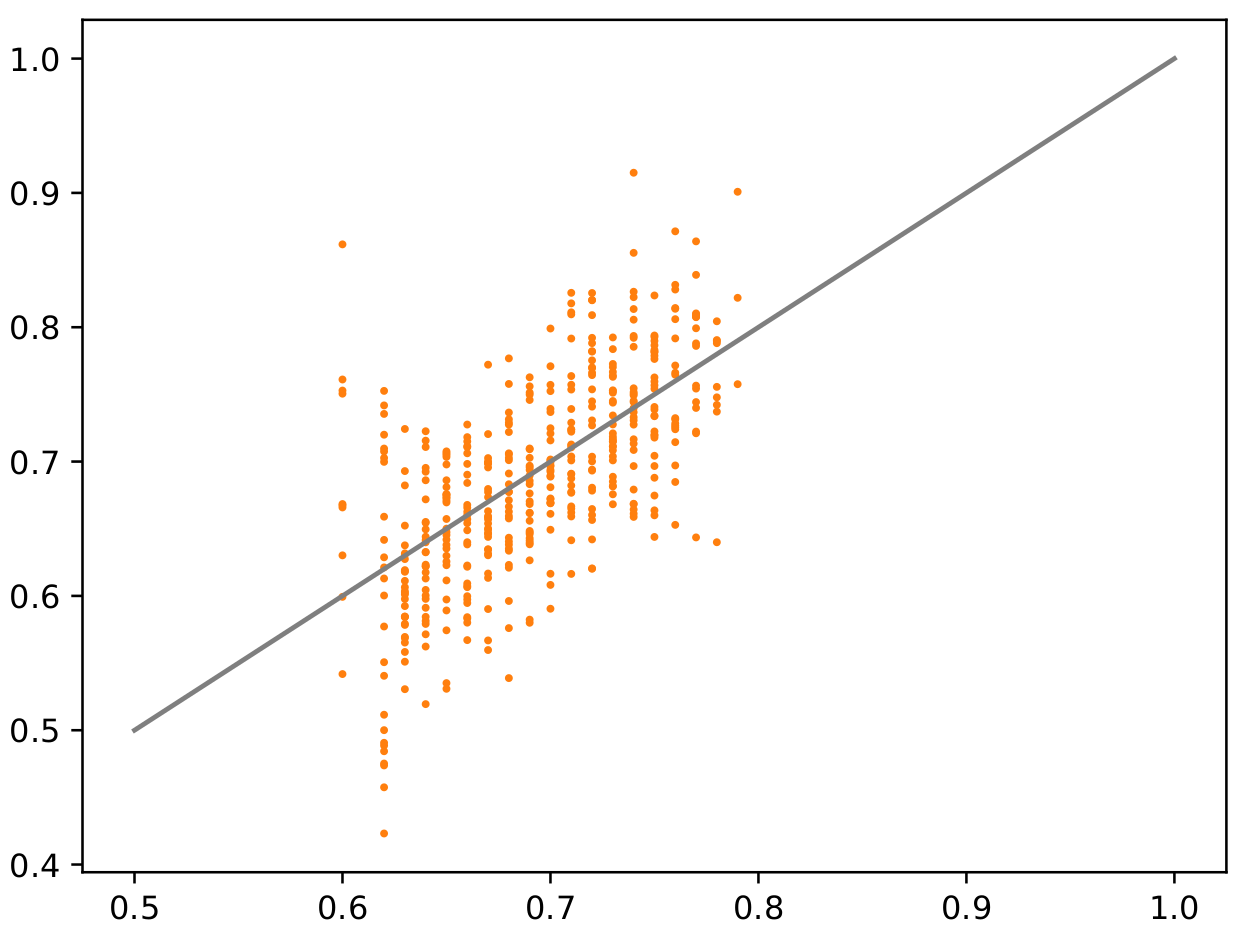
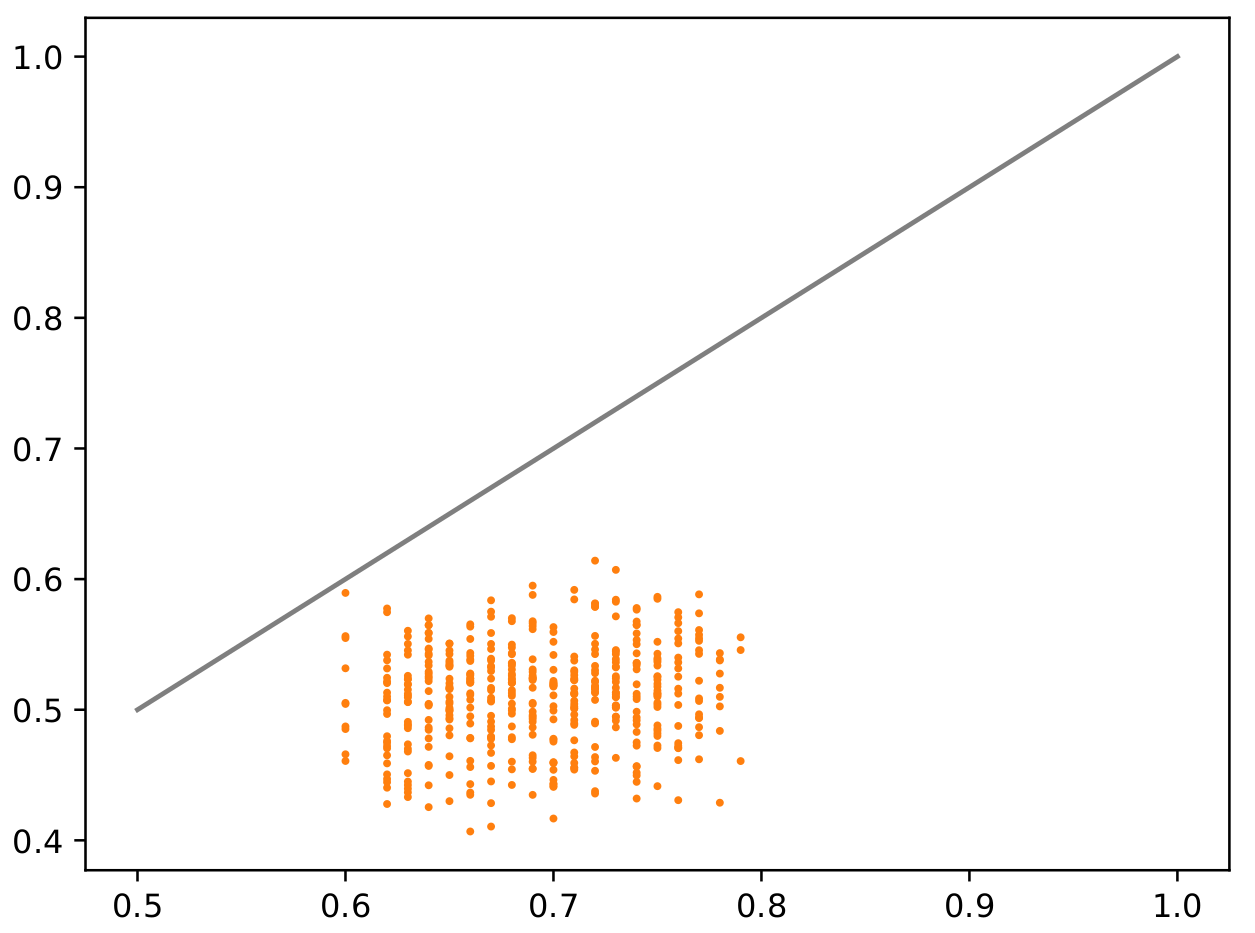
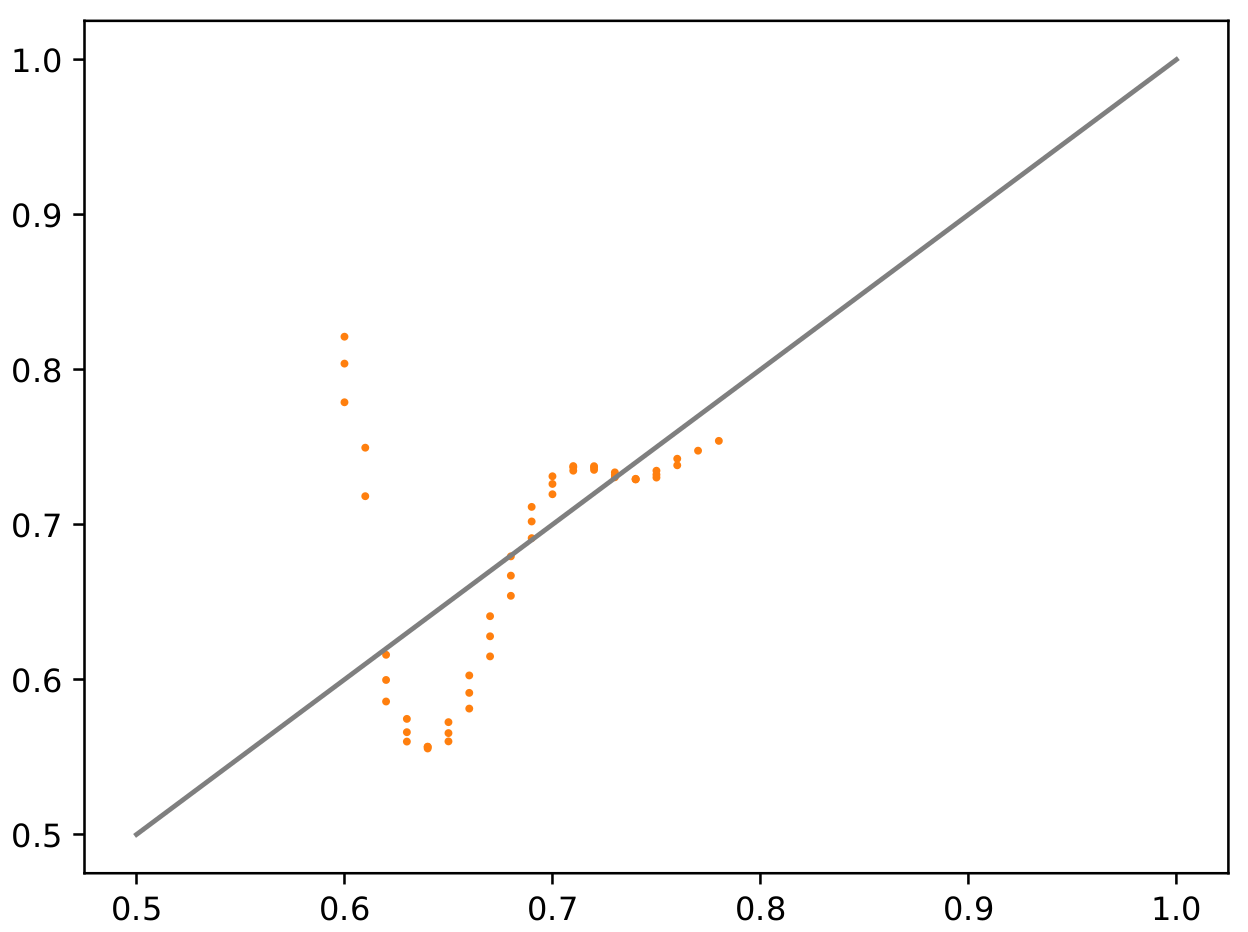
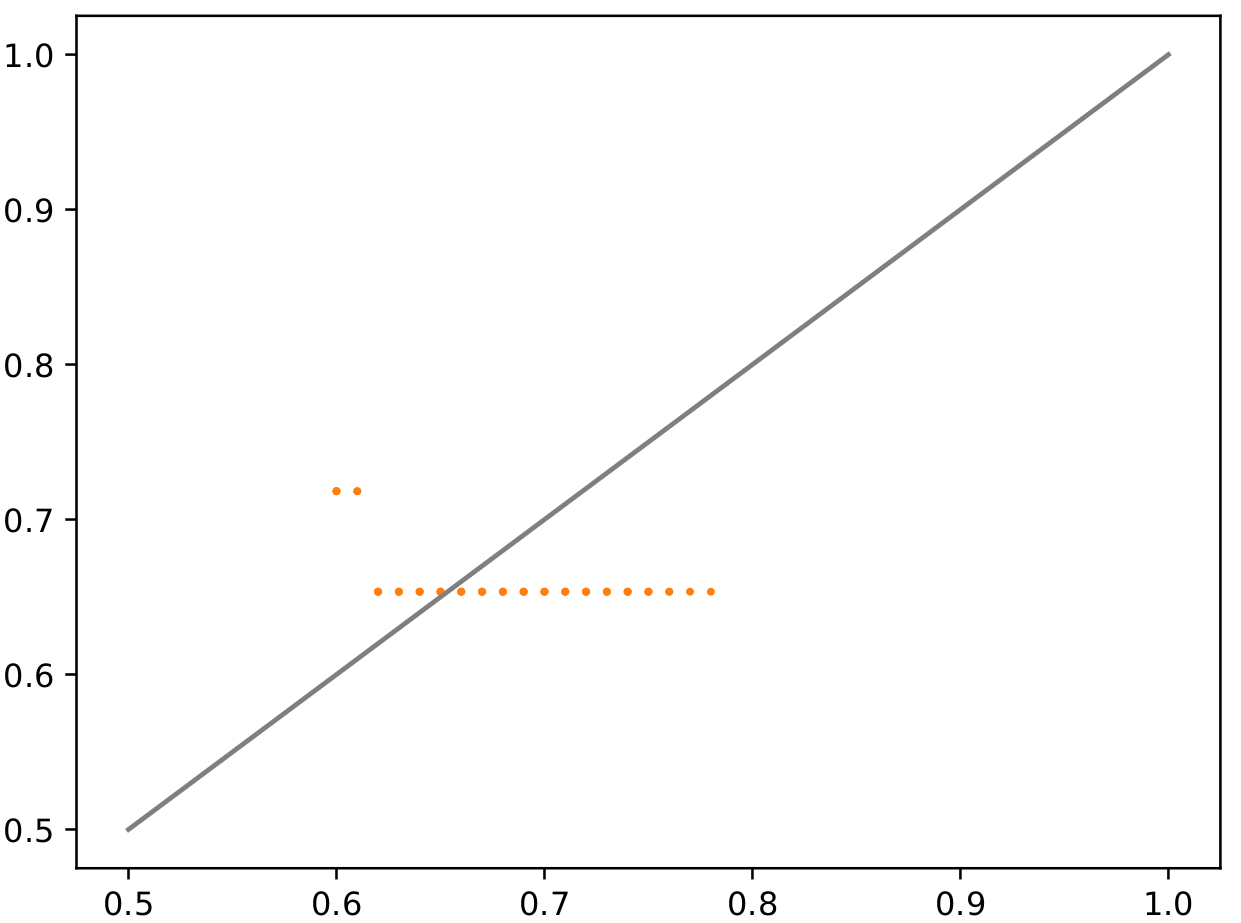
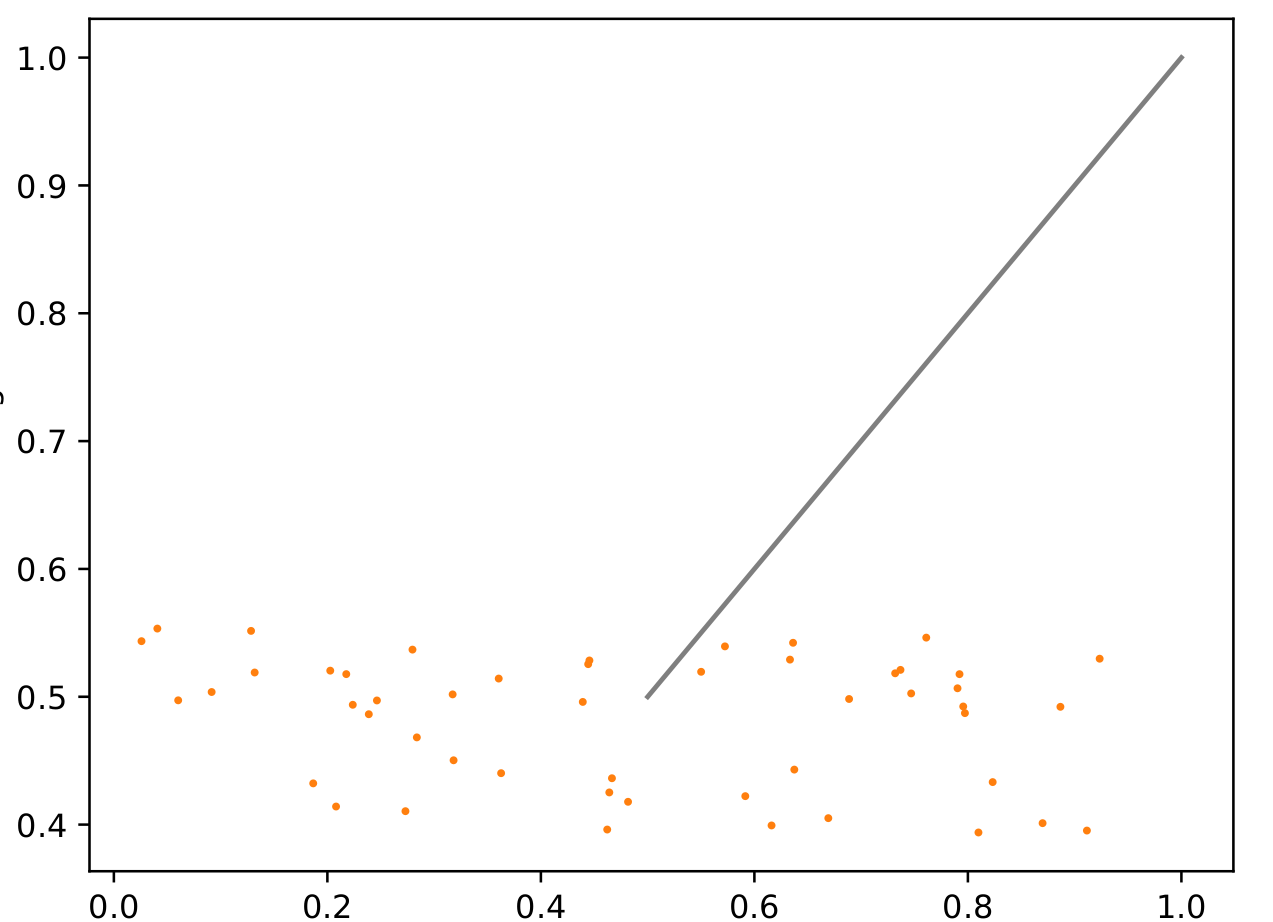
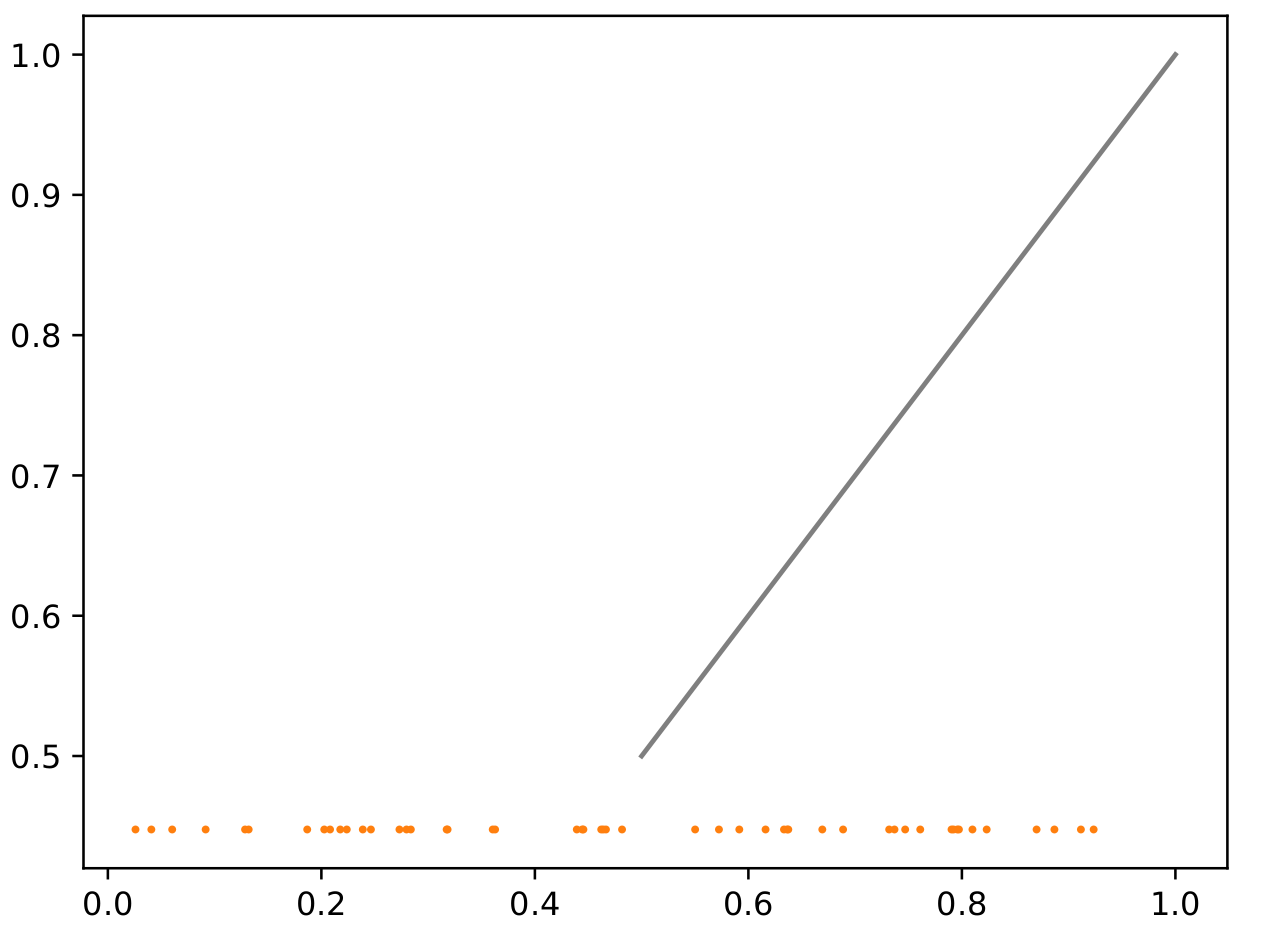
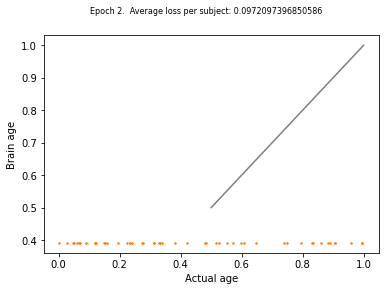
I do keep the model in train mode (I’ve tried going to eval first, but that didn’t work.)
I’ve created a version which should work on its own without any edits - thank you for taking a look.
import torch
from torch import nn
import numpy as np
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader, TensorDataset
from matplotlib import pyplot as plt
import numpy as np
###############
saved_model_filename = 'brain_age_network.pt'
###
learning_rate = 1e-3
batch_size = 1
n_global_epochs = 2 # going around all of the scans
###
rescaled_image_resolution = [200,256,256]
#
dropout = False
n_input_channels = 1
n_latent_channels = 128
total_down_conv_channels = n_latent_channels
first_down_res = True
first_down_res_stride = (2 if first_down_res else 1)
second_down_res = True
second_down_res_stride = (2 if second_down_res else 1)
#
kernel_size = 3
padding = 1
###
class RandDataset(Dataset):
def __init__(self, seed):
np.random.seed(seed)
self.image_data = np.random.rand(1, rescaled_image_resolution[0],rescaled_image_resolution[1],rescaled_image_resolution[2])
self.age = np.random.random()
def __len__(self):
return 1
def __getitem__(self, idx):
return self.image_data, self.age
#
class BNModel(nn.Module):
def __init__(self):
super().__init__()
# [200, 256, 256, x]
self.el0a = nn.Conv3d(in_channels=n_input_channels,out_channels=total_down_conv_channels,kernel_size=kernel_size, padding=padding, stride=2, bias=False)
self.el0b = nn.ReLU(inplace=True)
self.el0b_bn = nn.BatchNorm3d(total_down_conv_channels)
# [100, 128, 128, 64]
self.el1 = nn.Conv3d(in_channels=total_down_conv_channels,out_channels=total_down_conv_channels,kernel_size=kernel_size, padding=padding, stride=first_down_res_stride, bias=False)
self.el2 = nn.ReLU(inplace=True)
self.el2_bn = nn.BatchNorm3d(total_down_conv_channels)
self.max_pool_1 = nn.MaxPool3d(kernel_size=[2,2,2])
# [50, 64, 64, 64]
self.el3 = nn.Conv3d(in_channels=total_down_conv_channels,out_channels=total_down_conv_channels,kernel_size=kernel_size, padding=padding, stride=1, bias=False)
self.el4 = nn.ReLU(inplace=True)
self.el4_bn = nn.BatchNorm3d(total_down_conv_channels)
self.el3a = nn.Conv3d(in_channels=total_down_conv_channels,out_channels=total_down_conv_channels,kernel_size=kernel_size, padding=padding, stride=1, bias=False)
self.el4a = nn.ReLU(inplace=True)
self.el4a_bn = nn.BatchNorm3d(total_down_conv_channels)
if dropout:
self.mid_conv_dropout = nn.Dropout(p=0.3)
self.max_pool_2 = nn.MaxPool3d(kernel_size=[2,2,2])
# [50, 64, 64, 64]
self.el5 = nn.Conv3d(in_channels=total_down_conv_channels,out_channels=total_down_conv_channels,kernel_size=kernel_size, padding=padding, stride=second_down_res_stride, bias=False)
self.el6 = nn.ReLU(inplace=True)
self.el6_bn = nn.BatchNorm3d(total_down_conv_channels)
# [25, 32, 32, 64]
self.el7 = nn.Conv3d(in_channels=total_down_conv_channels,out_channels=total_down_conv_channels,kernel_size=kernel_size, padding=padding, stride=1, bias=False)
self.el8 = nn.ReLU(inplace=True)
self.el8_bn = nn.BatchNorm3d(total_down_conv_channels)
self.el7a = nn.Conv3d(in_channels=total_down_conv_channels,out_channels=total_down_conv_channels,kernel_size=kernel_size, padding=padding, stride=1, bias=False)
self.el8a = nn.ReLU(inplace=True)
self.el8a_bn = nn.BatchNorm3d(total_down_conv_channels)
# [25, 32, 32, 64]
self.el9 = nn.Conv3d(in_channels=total_down_conv_channels,out_channels=total_down_conv_channels,kernel_size=1, padding=0, stride=1, bias=False)
self.max_pool_3 = nn.MaxPool3d(kernel_size=[2,2,2])
self.el9_bn = nn.BatchNorm3d(total_down_conv_channels)
#############
self.global_pool = nn.AdaptiveAvgPool3d(output_size=1)
self.fc1 = nn.Linear(n_latent_channels, 256)
self.fc1_relu = nn.ReLU()
if dropout:
self.mid_fc_dropout = nn.Dropout(p=0.3)
self.fc2 = nn.Linear(256, 1)
self.fc2_relu = nn.ReLU()
#############
def forward(self, image_data):
x = self.el0a(image_data)
x = self.el0b(x)
x = self.el0b_bn(x)
x = self.el1(x)
x = self.el2(x)
x = self.max_pool_1(x)
x = self.el2_bn(x)
x = self.el3(x)
x = self.el4(x)
x = self.max_pool_2(x)
x = self.el4_bn(x)
x = self.el3a(x)
x = self.el4a(x)
x = self.el4a_bn(x)
if dropout:
x = self.mid_conv_dropout(x)
x = self.el5(x)
x = self.el6(x)
x = self.el6_bn(x)
x = self.el7(x)
x = self.el8(x)
x = self.el8_bn(x)
x = self.el7a(x)
x = self.el8a(x)
x = self.el8a_bn(x)
x = self.el9(x)
x = self.max_pool_3(x)
x = self.el9_bn(x)
#
x = self.global_pool(x) # this produces one per channel
x = torch.reshape(x, (1, total_down_conv_channels))
x = self.fc1(x)
x = self.fc1_relu(x)
if dropout:
x = self.mid_fc_dropout(x)
x = self.fc2(x)
x = self.fc2_relu(x)
#
predicted_age = x
return predicted_age
###
def train_model():
# set random seeds
torch.manual_seed(1)
torch.cuda.manual_seed(1)
# setup device cuda vs. cpu
cuda = torch.cuda.is_available()
device = torch.device("cuda:0" if cuda else "cpu")
assert cuda, "we require cuda for the brain network"
model = BNModel().to(device)
#
training_seeds = [np.random.randint(100000,999999) for i in range(50)]
# Setting the optimiser
try:
optimizer = torch.optim.Adam(
model.parameters(),
lr=learning_rate,
fused=True, # this does more of the work on the GPU
)
except Exception as e:
optimizer = torch.optim.Adam(
model.parameters(),
lr=learning_rate,
)
#
criterion = torch.nn.MSELoss(reduction='sum')
X = []
Y = []
#
from matplotlib.backends.backend_pdf import PdfPages
pdf = PdfPages("brain_age_model_training.pdf")
#
for global_epoch in range(1, n_global_epochs+1):
global_epoch_train_loss = 0
n_global_epoch_trainings = 0
X = []
Y = []
for seed in training_seeds:
try:
dataset = RandDataset(seed)
except Exception as e:
continue
train_loader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
# train for one epoch
model.train()
for image_data_s, actual_age_s in train_loader:
image_data_s = image_data_s.float().to(device)
actual_age_s = actual_age_s.float().to(device)
# ===================forward=====================
predicted_ages = model(image_data_s)
predicted_ages = predicted_ages.squeeze(1)
X.append(actual_age_s.clone().detach().item())
Y.append(predicted_ages.clone().detach().item())
loss = criterion(predicted_ages, actual_age_s)
local_loss = loss.clone().detach()
if global_epoch_train_loss is None: # keep it on the gpu to avoid unneccesary cpu/gpu syncs
global_epoch_train_loss = local_loss
else:
global_epoch_train_loss += local_loss
n_global_epoch_trainings += 1
# ===================backward====================
optimizer.zero_grad()
loss.backward()
optimizer.step()
global_epoch_train_loss = global_epoch_train_loss.item()
average_loss_per_scan = global_epoch_train_loss / n_global_epoch_trainings
print(f"Global epoch average scan loss: {average_loss_per_scan}")
# save a graph to a pdf to show our predictions vs reality
fig, ax = plt.subplots()
ax.plot([0.5,1.0],[0.5,1.0],c="tab:grey")
ax.scatter(X, Y, s=2.2,c="tab:orange")
ax.set_xlabel("Actual age")
ax.set_ylabel("Brain age")
fig.suptitle(f"Epoch {global_epoch}. Average loss per subject: {average_loss_per_scan}", fontsize=8)
pdf.savefig(fig)
plt.close(fig)
if True:
X = []
Y = []
#with torch.no_grad():
if True:
#model.train()
#model.eval()
for seed in training_seeds:
try:
dataset = RandDataset(seed)
except Exception as e:
continue
train_loader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
for image_data_s, actual_age_s in train_loader:
image_data_s = image_data_s.float().to(device)
actual_age_s = actual_age_s.float().to(device)
# ===================forward=====================
predicted_ages = model(image_data_s)
predicted_ages = predicted_ages.squeeze(1)
X.append(actual_age_s.clone().detach().item())
Y.append(predicted_ages.clone().detach().item())
loss = criterion(predicted_ages, actual_age_s)
#
fig, ax = plt.subplots()
ax.plot([0.5,1.0],[0.5,1.0],c="tab:grey")
ax.scatter(X, Y, s=2.2,c="tab:orange")
ax.set_xlabel("Actual age")
ax.set_ylabel("Brain age")
fig.suptitle(f"POST TRAINING RESULTS NON-RELOADED SCANS", fontsize=8)
pdf.savefig(fig)
plt.close(fig)
#
# save the state dict of the model
torch.save(model.state_dict(), saved_model_filename)
#
pdf.close()
plt.close('all')
###
train_model()
This gives the same fundamental problem to me - during training we get at least some learning (although it’s more random with fully random data):
And yet when not doing the backwards step (the final graph) - we just get flat output: