I’m trying to forecast the product demand of several articles. I’m using a CNN-LSTM model and work with continuous and categorical features. (I embed the categorical data in the model).
I have daily data (a time series from 2013 until now) for around 100 article groups.
I only try to predict the demand of articles that get bought often. (and drop the data for the articles I have less data for)
At the start I summarized the data by month and used the last 12 months to predict the product demand for 1-6 months in the future.
That worked fine for the training data (around 90-99% accuracy), but I only got around 10-15 % accuracy for the test data. (I split the data: 85% train and 15% test) So the model was overfitting a lot. I added drop out layers and used weight decay and early stopping, but nothing worked.
Then, to get “more” data, I summarized the data on a weekly basis and now use the last 52 weeks o predict the demand of the next week (and then use the "new"data to predict the demand for another week in the future, and so on, step by step).
I am using a SGD optimizer. For the monthly data I used a CosineAnnealingWithWarmRestarts Scheduler, for the weekly data I first switched to an circular/triangular decreasing scheduler and now I am using the OneCycle scheduler (with the help of a learning rate finder: LRFinder).
To find better hyperparameters for the number of layers, filters, drop out probabilities, weight decay, base momentum, etc.) I am using Optuna. The metric to decide which trial is “better” than another is the test accuracy. (To also compare simpler and more complex models regarding the number of neurons ← battling the overfitting).
I run a lot of trials with different hyperparameters combinations now, but the model is still overfitting (a lot!) and the train accuracy is no longer as high as with the monthly data.
Any ideas what I could do or improve?
My model:
CNNLSTM(
(emb_layers): ModuleList(
(0): Embedding(8, 4)
(1): Embedding(12, 6)
(2): Embedding(53, 27)
(3): Embedding(2, 1)
(4): Embedding(2, 1)
(5): Embedding(2, 1)
(6): Embedding(2, 1)
(7): Embedding(28, 14)
(8): Embedding(4, 2)
)
(emb_dropout_layer): Dropout(p=0.386, inplace=False)
(cnn): CNN(
(conv1): Conv2d(52, 256, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1))
(maxpool): MaxPool2d(kernel_size=(3, 3), stride=1, padding=0, dilation=1, ceil_mode=False)
(drop): Dropout(p=0.1599, inplace=False)
)
(lstm): LSTM(85, 96, num_layers=2, batch_first=True, dropout=0.281)
(linear1): Linear(in_features=96, out_features=28, bias=True)
(linear2): Linear(in_features=1, out_features=1, bias=True)
(lbefore_lin_drop): Dropout2d(p=0.153, inplace=False)
(fin_drop): Dropout(p=0.073, inplace=False)
(leakyrelu): LeakyReLU(negative_slope=0.15)
)
So I embed the categorical features first, then concatenate them and pass it to a drop out layer.
Then I concatenate the embedded data with the continuous data and pass it to a CNN that consists of 2 convolutional layers Conv2D followed by a MaxPool2d and a Dropout layer.
The input for the CNN is of the shape (Number of samples x Number of articles x Time span x number of features), for weekly data the time span is 52 weeks, the number of features is the sum of the embedding dimensions plus the number of continuous features.
Then a LeakyReLU.
Then I reshape the data before i pass them to the LSTM.
(I reshape the data from (N x out_channel x H_out x W_out) to (N * out_channel x H_out x W_out).)
Then a Dropout2d layer.
Then a Linear layer.
More reshaping.
(I reshape the data from (N x number of articles * length of the forecast) to (N x number of articles x length of the forecast)), at the moment the length of forecast is 1 week, because I predict step by step, I also tried multiple step forecast before and the length of forecast was 12 weeks.)
Another LeakyReLU.
Then a final Linear layer followed by another Dropout layer and a LeakyReLU.

This is an overview over some trials, as you can see the test accuracy gets nowhere fast…
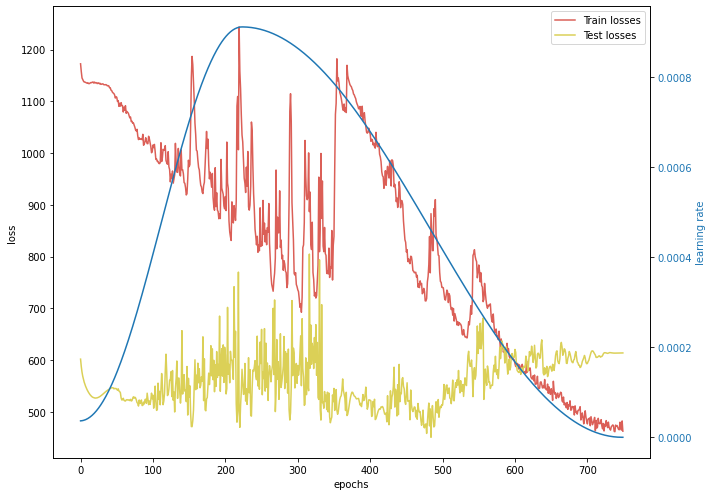
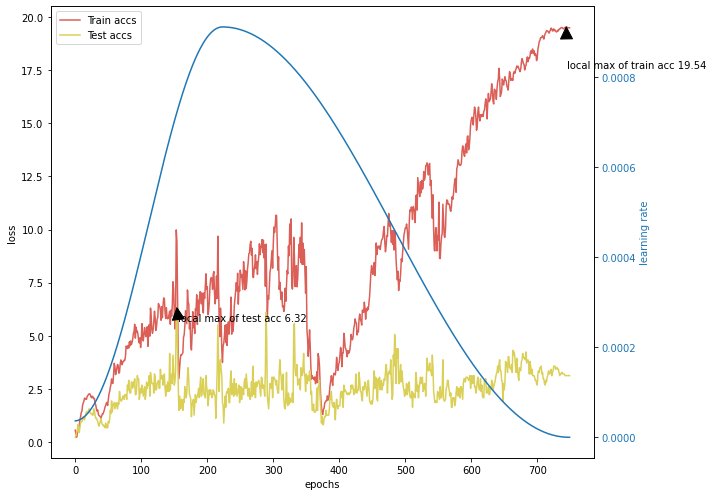
Just an example for a loss and accuracy history I get.
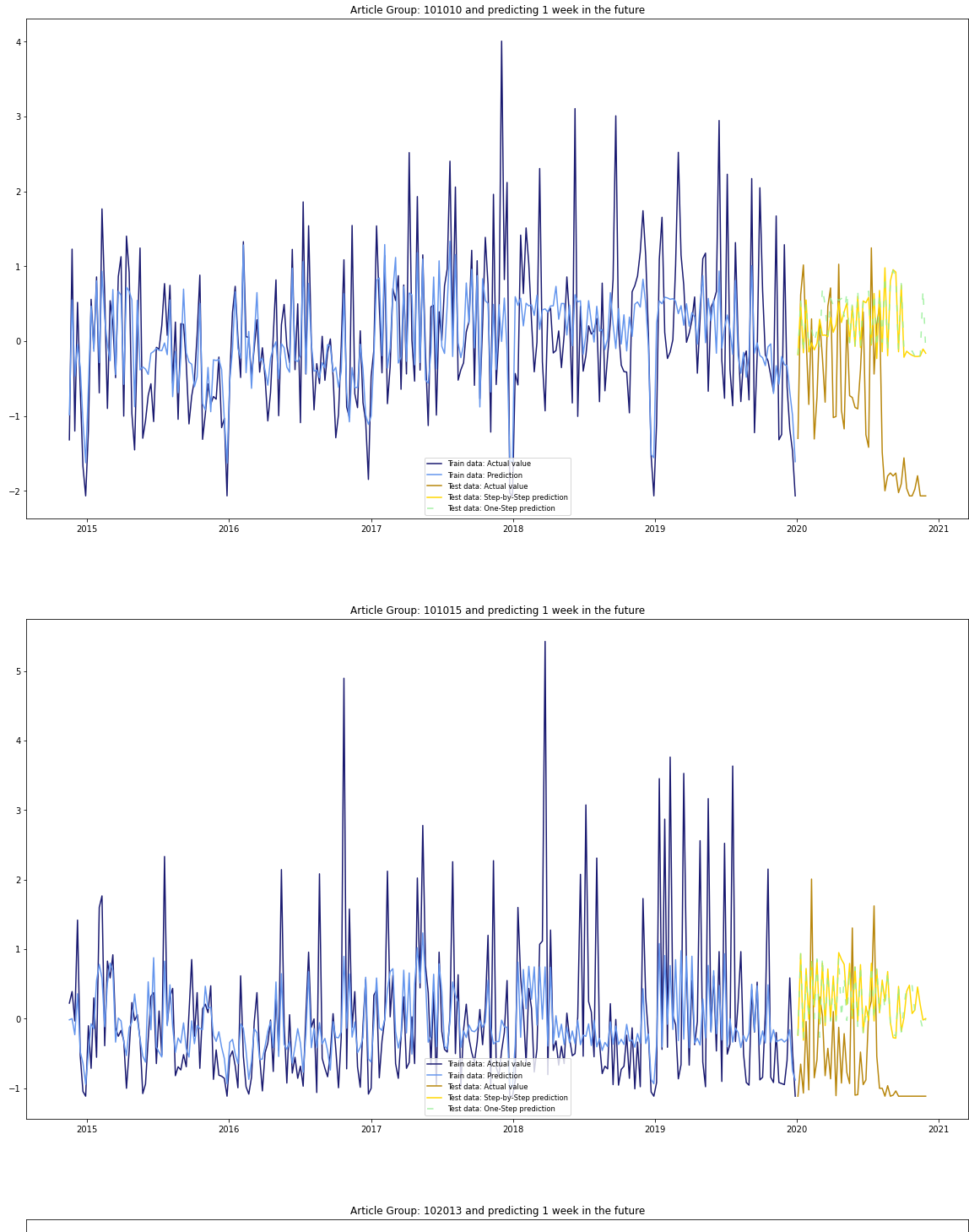
And the predictions look like this at the moment…